
Spark 各种模式下的提交方式以及配置参数说明
使用下面的命令查看对应版本的提交参数详细说明
spark-submit --help
local 模式下的提交模板
SPARK_HOME/bin/spark-submit \ # 执行spark-submit脚本
# 指定提交jar包的主类
--class com.neusoft.client.xxxxxxxx \
# 4核cpu
--master local[4] \
# jar包路径,对于Python应用,在此位置传入一个.py文件并且以--py-files的方式搜索路径下加入Python.zip、.egg、.py文件
/usr/zhangqiang/xxxx.jar
# 额外的参数,传递给main函数的args
[application-arguments]
python file 提交
# 环境变量指定 python 版本
export SPARK_HOME=/usr/hdp/current/spark2-client
export PYTHONPATH=/usr/bin/python3
export IPYTHON=1
export PYSPARK_PYTHON=/usr/bin/python3
export PYSPARK_DRIVER_PYTHON=ipython3
export PYSPARK_DRIVER_PYTHON_OPTS="notebook"
SPARK_HOME/bin/spark-submit \ # 执行spark-submit脚本
# 4核cpu
--master local[4] \
# 在此位置传入一个.py文件并且以--py-files的方式搜索路径下加入Python.zip、.egg、.py文件
--py-files test.py
# main
test.py
Standalone 模式提交模板
# 在环境变量中配置了SPARK_HOME/bin后就可以直接调用此脚本
spark-submit \
--class com.neusoft.SimpleApp \
# spark集群master的地址
--master spark://10.4.120.83:7077 \
# 每个executor的内存大小
--executor-memory 2G \
# 所有executors一共使用10个核
--total-executor-cores 10 \
/usr/zhangqiang/xxxx.jar
[application-arguments]
YARN 模式提交模板
# 与standalone一一对应
spark-submit \
--class com.neusoft.SimpleApp \
# 默认是client模式,该集群的位置可以在HADOOP_CONF_DIR变量中找到
--master yarn \
--executor-memory 2G \
--num-executors 10 \
/usr/zhangqiang/xxxx.jar
[applications-arguments]
YARN 模式提交的两种方式
# 提交到yarn,默认以client模式提交
# 客户端方式提交
spark-submit --master yarn --deploy-mode client ...
# 集群模式提交
spark-submit --master yarn --deploy-mode cluster ...
导入第三方依赖
直接将依赖包打入提交的jar包里面
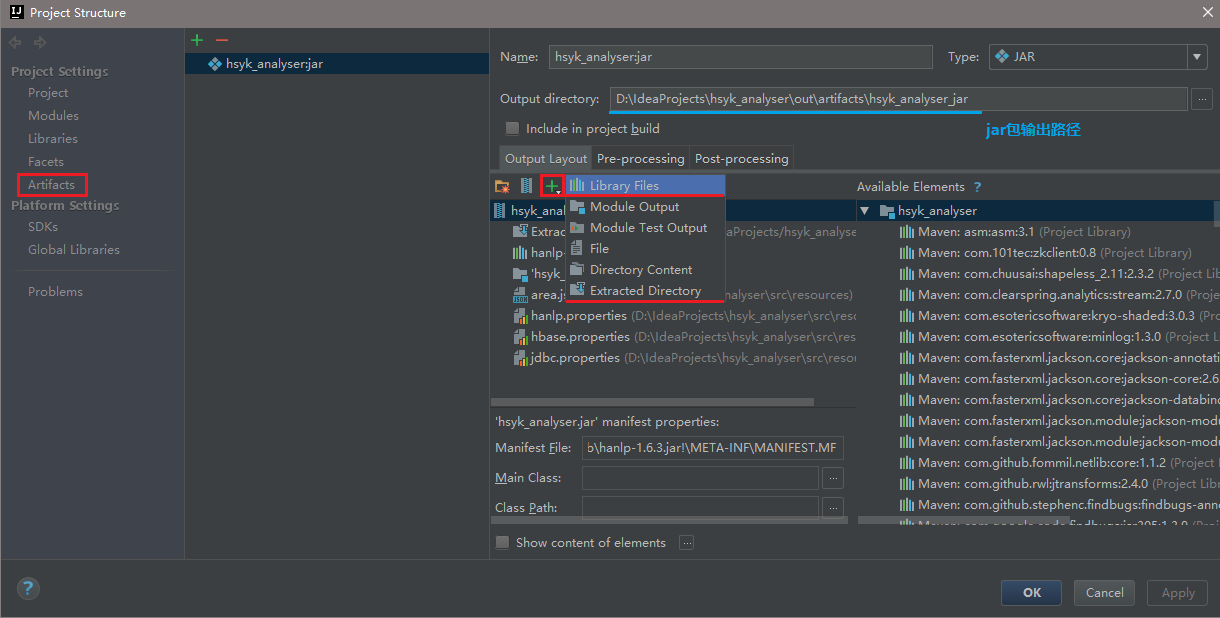
Library Files这种方式是把.jar文件打入到artifact.jar中,反编译后是这样的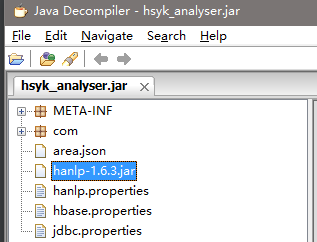
Extracted Directory是直接把.class文件打入到artifact.jar中,相当于maven-assembly的fat-jar。如下: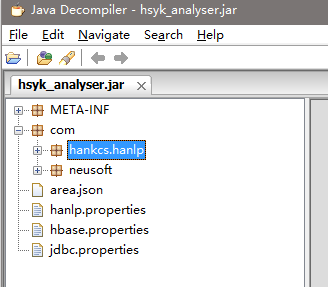
指定 –jars
--jars 即 Spark Runtime Environment Property saprk.jars,指定一个以,分割的jar包文件列表。注意只能指定文件。
spark-submit \
--class com.neusoft.SimpleApp \
--jars /opt/neu/jars/mysql-connector-java-5.1.27-bin.jar,/opt/neu/jars/hanlp-1.6.3.jar
指定 –packages
--packages 即 Spark Runtime Environment Property spark.jars.packages,包含在 driver 和 executors classpath 中的 jar 的 Maven 坐标的逗号分隔列表。 坐标应该是groupId:artifactId:version。 如果给出spark.jars.ivySettings,则会根据文件中的配置来解析artifacts,否则将在本地 Maven 库中搜索 artifacts,然后是 Maven Central 或者是--repositories指定的其他远程资源库
spark-submit \
--class com.neusoft.SimpleApp \
--packages mysql:mysql-connector-java:5.1.27,com.hankcs:hanlp:portable-1.6.3 \
--repositories https://maven.neusoft.com/nexus/content/groups/public/
添加到 SPARK_CLASSPATH
直接将依赖的jar包发送到各个节点的$SPARK_HOME/jars中,这个文件夹包含了Spark本身所需要的所有依赖,直接将额外的依赖包放到里面容易混淆。
更好的方式如下:
# Note: Env variable `SPARK_CLASSPATH` has been deprecated in Spark 1.0+.
vim $SPARK_HOME/conf/spark-env.sh
SPARK_CLASSPATH=$SPARK_CLASSPATH:/opt/spark/external_jars/*
# 指定 spark.driver.extraClassPath,不要在程序 SparkConf 中指定,因为那时候 JVM 已经启动了。
spark-submit --driver-class-path /somepath/project/mysql-connector-java-5.1.30-bin.jar --jars /somepath/project/mysql-connector-java-5.1.30-bin.jar
然后将所有依赖的jars包放到external_jars文件夹下就可以了。
上面所说的所有路径,集群所有节点都需要复制一份完全相同jar文件。
Spark On YARN
- 方式1:YARN Application 依赖的路径在 YARN 中的
yarn.application.classpath配置。将 jar 包放在该配置项指定的路径下即可。 - 方式2:在
conf/spark-defaults.conf配置spark.yarn.archive或spark.yarn.jars。详细介绍
客户端模式和集群模式的最主要的区别
客户端模式比较适合开发调试,因为它是在同一物理位置(即同一网关)的服务器上提交应用程序,Driver直接在用户的spark-submit进程(client)中启动,应用程序的输入和输出连接到控制台,能够快速的看到application的输出,比较适合开发和测试
如果应用程序是在远离Worker节点的某台机器上提交的(比如你远程开发的电脑),一般使用Cluster模式,这样可以使Drivers和Executors之间的网络延迟最小化,比较适合生产环境。
从深层次讲,他们的区别就是Application Master进程的区别,yarn-cluster模式下,driver运行在am(application master)中,他(driver)负责向yarn申请资源,并监督作业的运行状况,当用户提交了作业之后就可以关掉client了,作业会继续在yarn上运行。而client模式下am仅仅向yarn请求executor。driver运行在client中,client会和请求的container通信来调度他们的工作,也就是说不能关掉client(client 模式下你的 spark-submit 启动的进程,ctrl + c 你提交的任务就停了!)。
总结:
client模式下,am向yarn请求资源,client进行监督调度,所以spark yarn-client模式的配置都是以spark.am开头
cluster模式下,driver向yarn请求资源,并监督作业运行,所以spark yarn-cluster模式的配置以spark.driver开头
附:cluster模式的日志是下面这个样子的,因为具体的 driver 日志都返回到 driver 了,因此你看不到具体的日志信息,只能看到心跳信息。
17/04/07 18:27:10 INFO yarn.Client: Application report for application_1491557185266_0001 (state: RUNNING)
17/04/07 18:27:11 INFO yarn.Client: Application report for application_1491557185266_0001 (state: RUNNING)
17/04/07 18:27:12 INFO yarn.Client: Application report for application_1491557185266_0001 (state: RUNNING)
17/04/07 18:27:13 INFO yarn.Client: Application report for application_1491557185266_0001 (state: RUNNING)
17/04/07 18:27:14 INFO yarn.Client: Application report for application_1491557185266_0001 (state: RUNNING)
17/04/07 18:27:15 INFO yarn.Client: Application report for application_1491557185266_0001 (state: RUNNING)
Spark 指定执行用户
在shell中指定环境变量
export HADOOP_USER_NAME=hdfs
在程序中指定环境变量
System.setProperty("HADOOP_USER_NAME", "hdfs")
在 spark executor 指定执行用户
val sparkConf = new SparkConf()
sparkConf.set("HADOOP_USER_NAME", "hdfs")
SparkSubmit 源码
spark-submit具体的执行逻辑都在spark-core org.apache.spark.deploy.SparkSubmit的main方法中。
SparkShell
- What do the numbers on the progress bar mean in spark-shell?
[Stage7:===========> (14174 + 5) / 62500]What you get is a Console Progress Bar,
[Stage 7: shows the stage you are in now, and (14174 + 5) / 62500]is(numCompletedTasks + numActiveTasks) / totalNumOfTasksInThisStage]. The progress bar showsnumCompletedTasks / totalNumOfTasksInThisStage.
It will be shown when both
spark.ui.showConsoleProgressis true (by default) and log level inconf/log4j.propertiesis ERROR or WARN (!log.isInfoEnabled is true).
# Help
$ spark-shell -h
$ spark-shell \
--master yarn \
--driver-cores 4 \
--driver-memory 8G \
--num-executors 40 \
--executor-memory 30G \
--executor-cores 4 \
--conf "spark.yarn.maxAppAttempts=1" \
--packages com.databricks:spark-avro_2.11:4.0.0




