
Python Script
Python通过编写脚本来执行程序,Python脚本以.py为扩展名,.pyw代表后台运行的Python文件。
print 'hello python`
将代码保存在test.py中,在linux shell中使用python命令执行脚本。
python test.py
可以在脚本文件中指定python解释器所在的路径,以可执行文件的方式执行脚本
方式1:直接指定解释器所在的绝对路径
#!/usr/bin/python
print 'hello python`
方式2:告知python去环境变量里面查找python的安装路径,然后使用安装路径中的解释器
#!/usr/bin/env python
print 'hello python`
然后将test.py文件修改成为可执行文件
chmod +x test.py # 增加可执行权限
./test.py # 执行脚本
Python 标识符
标识符由字母、数字、下划线组成,区分大小写,但是不能以数字开头。
下划线开头的标识符有特殊意义。
单下划线开头的变量,如_foo代表不能直接访问的类属型,需要通过类提供的接口进行访问,并且不能用from xxx import *导入。
双下划线开头的变量,如__foo代表类的私有成员
以双下划线开头和结尾代表特殊方法,如__init__()代表类的构造函数
命令行参数
python -h # 查看参数使用方法
# 显示如下信息
usage: python [option] ... [-c cmd | -m mod | file | -] [arg] ...
Options and arguments (and corresponding environment variables):
-B : don't write .py[co] files on import; also PYTHONDONTWRITEBYTECODE=x
-c cmd : program passed in as string (terminates option list)
-d : debug output from parser; also PYTHONDEBUG=x
...
传参
python test.py hello world
接收参数
将下列代码写入test.py中
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import sys
print sys.argv[0] # 输出脚本文件名称 .test.py
print sys.argv[1] # 输出 hello
print sys.argv[2] # 输出 world
类与对象
member scope
默认情况下,Python 中的成员函数和成员变量都是公开的(public),在 Python 中没有类似public、private等关键词来修饰成员函数和成员变量。
Python 在内部使用一种 name mangling 技术,将__membername替换成_classname__membername,也就是说,类的内部定义中,所有以双下划线开始的名字都被”翻译”成前面加上单下划线和类名的形式。
例如:为了保证不能在 class 之外访问私有变量,Python 会在类的内部自动的把我们定义的__spam私有变量的名字替换成为_classname__spam(classname 前面是一个下划线,spam 前是两个下划线),这样,用户在外部访问__spam的时候就会提示找不到相应的变量,但是 Python 中的私有变量和私有方法仍然是可以访问的。访问方法如下:
私有变量:实例._类名__变量名私有方法:实例._类名__方法名()
因此,Python并没有真正的私有化支持,但可用下划线得到伪私有。尽量避免定义以下划线开头的变量!
_xxx: 单下划线开头的成员变量是保护成员,只有类实例和子类实例能访问到这些变量,需通过类提供的接口进行访问,无法通过from module import *导入__xxx: 双下划线开头的成员变量是私有成员,只有类对象自己能访问,连子类对象也不能访问到这个数据__xxx__: 系统定义名字,前后均有一个双下划线,代表 Python 里特殊方法专用的标识,如__init__()代表类的构造函数
lambada 表达式
条件运算,如简单的if else,可以用三元运算符表示,即:
# 普通条件语句
if 1==1:
name = '张三'
else:
name = '李四'
# 三元运算符
name = '张三' if 1==1 else '李四'
对于定义简单函数,可以用lambada表达式表示:
# 普通函数
def func(arg1, arg2):
return arg1 + arg2
# lambada
m_lambada = lambada arg1, arg2 : arg1 + arg2
lambada 就是函数的简洁表示,常用于表示匿名函数,高阶函数的参数,例如:
li = [1,2,3,4,5,6,7,8,9]
# reduce() 的三个参数:
# 参数1:两个参数的操作函数
# 要遍历的序列
# 初始默认值(可选)
result = reduce(lambda arg1, arg2: arg1 + arg2, li, 0)
下面用两张图直观的解释下reduce操作,不管是Python还是Scala还是Xxxx每个语言除了语法不同,要做的事情是一样的。
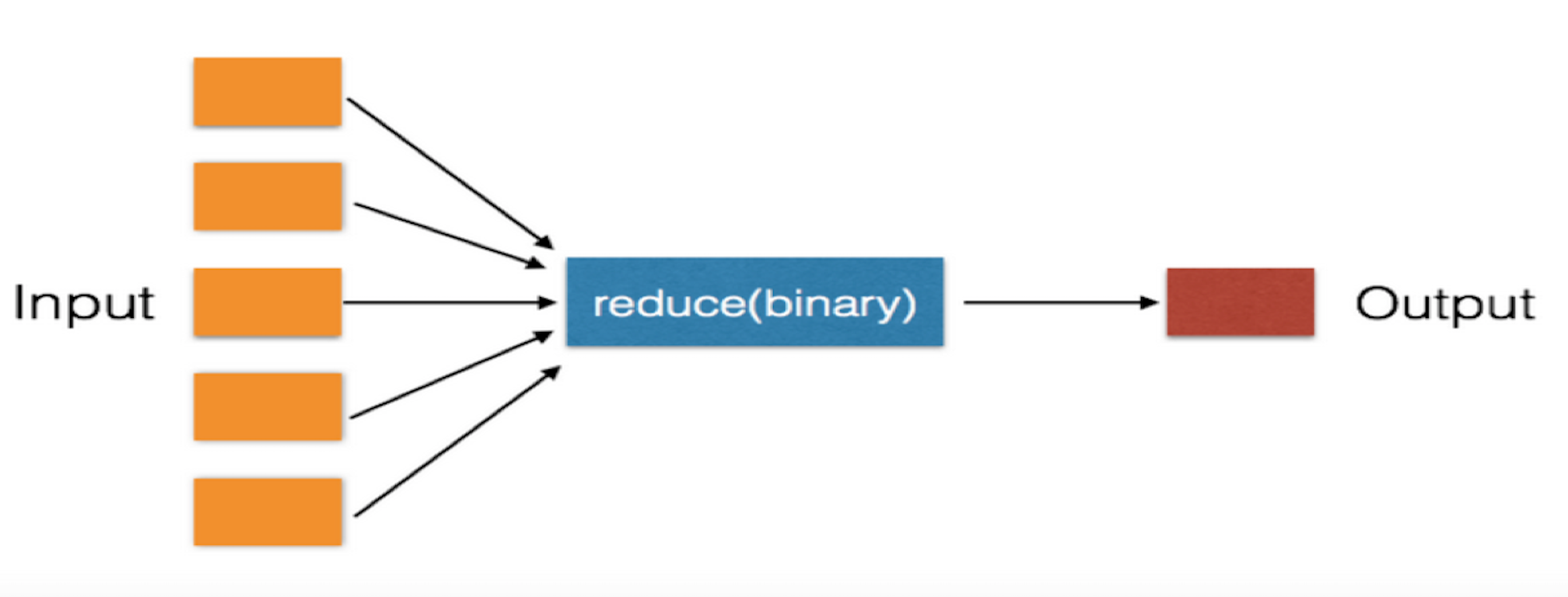
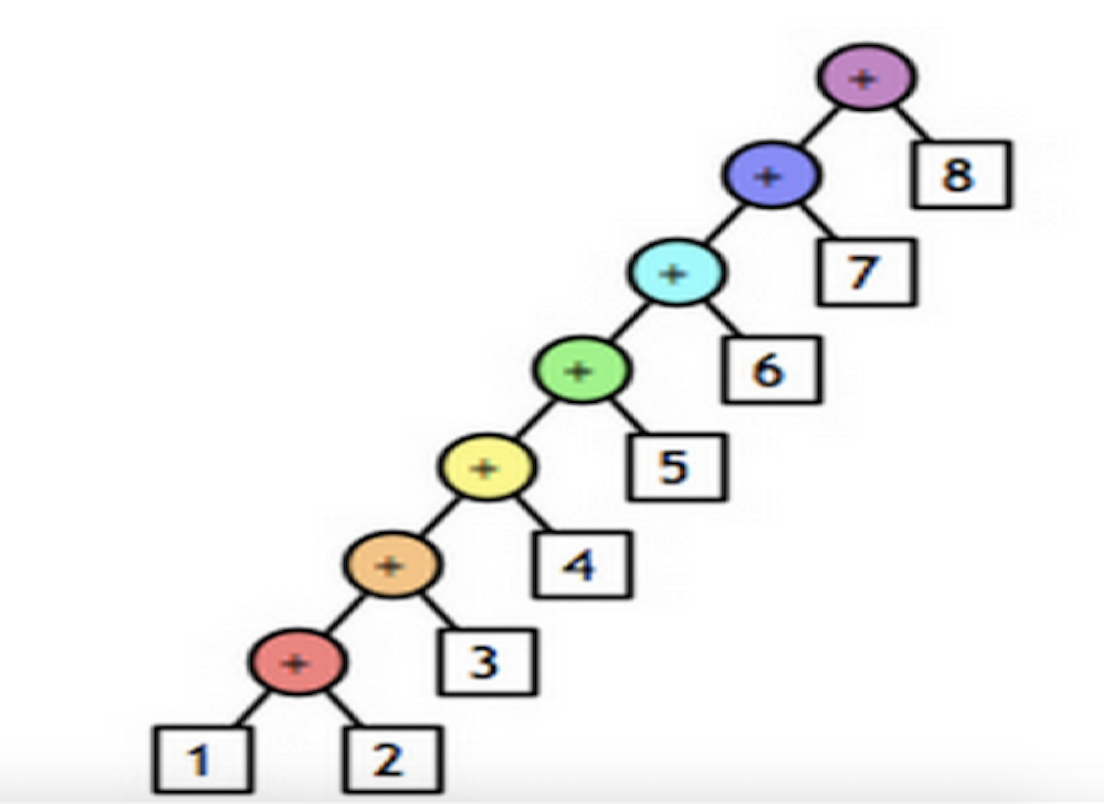
可迭代对象
Python中,可以直接作用于for循环的对象统称为可迭代对象(Iterable)。包括:
- 列表(list):
[1, 2, 3] - 集合(set):
{1, 2, 3} - 元组(tuple):
(1, 2, 3) - 字符串(str):
"123" - 生成器(generator):
xrange(1, 4)
可以使用 isinstance() 方法判断一个对象是否是Iterable对象。
>>> from collections import Iterable
>>> isinstance([1, 2, 3], Iterable)
True
>>> isinstance({1, 2, 3}, Iterable)
True
>>> isinstance((1, 2, 3), Iterable)
True
>>> isinstance("123", Iterable)
True
>>> isinstance(xrange(1, 4), Iterable)
True
Python生成器与列表的区别。如果列表中有10000个对象,那么在构造这个列表的时候就需要占用10000个对象的内存,而生成器就不会占用这么多内存。generator保存的是算法,真正需要获取值的时候才会去计算下一个值,属于惰性计算(lazy evaluation)。
最简单的例子如内置函数 range(1, 10) 与 xrange(1, 10),前者生成一个1到9的列表,后者生成一个1到9的生成器。
创建 generator
在Python中创建generator有两种方式
使用 Generator Function
通过关键词yield将函数变成 generator function
def get_generator():
for i in range(1, 10):
yield i
generator = get_generator()
函数执行到yield时就会停住,当需要下一个值时,会在yield的下一行继续执行。所以生成器函数即便是无限循环也没有问题。
例如利用yield生成斐波那契数列
def fibonacci():
a, b = 0, 1
while True:
# 第一次next()函数执行到此返回a的值,然后停止运行。第二次执行next()时在这行代码的下一行继续执行。
yield a
# 先将 = 右面的值计算出来,然后分别复制给 = 左面的变量
a, b = b, a + b
# 获取生成器
f = fibonacci()
print next(f),next(f),next(f),next(f),next(f),next(f),next(f),next(f)
# 0, 1, 1, 2, 3, 5, 8, 13
通过 () 与 嵌套 for 循环 构造 generator 生成器
注意: ()并不是要生成元组,而是生成generator生成器
lists = [[1, 2], [3, 4, 5], [6, 7, 8]]
# 生成 1 - 8 的生成器
generator = (x for list in lists for x in list)
# 生成 1 - 8 中为偶数的生成器
generator = (x for list in lists for x in list if x % 2 == 0)
引申:通过 for 循环构造集合
通过 for 循环生成list列表(列表生成式)
# 生成 2,4,6,8
list = [x * 2 for x in xrange(1, 5)]
通过 for 循环生成dict字典
# 键值是键的2倍
dict = {x : x * 2 for x in xrange(1, 5)}
通过 for 循环生成set集合
# set([1, 2, 3, 4]) 等价于 {1, 2, 3, 4}
set = {x for x in xrange(1, 5)}
注: 另外,dict 是 unhashable type: 'dict' 所以不可以将list dict转换成set dict,即不会存在set dict这种东西。如果想将list dict进行去重操作,可以使用下面的方法:
list_dict = [
{
"date": "2017-9-30",
"status": "2"
},
{
"date": "2017-10-1",
"status": "1"
},
{
"date": "2017-10-1",
"status": "1"
}
]
def deduplicate_list_dict(list_dict) =
deduplicate_set = set()
for dict in list_dict:
if dict['date'] not in deduplicate_set:
yield dict
deduplicate_set.add(dict['date'])
迭代器 Iterator
可以使用next()函数不断取值的对象就是Iterator对象。显然Iterable对象中,只有generator是Iterator。可以使用iter()函数将list、tuple、dict、set转换成Iterator。
>>> from collections import Iterator
>>> isinstance(iter([]),Iterator)
True
获取当前目录
import os
import sys
print("列出当前文件的绝对路径: %s" % sys.argv[0])
print("列出当前文件所在目录: %s" % os.getcwd())
print("列出当前文件所在目录下的所有文件: %s" % os.listdir())
# 路径拼接
log_file = os.path.join(os.getcwd(), 'daily.log')
# 或者使用正则表达式,防止`\`被当成转义符
log_file = os.getcwd() + r'\daily.log'
日期格式化
使用datetime模块,开发文档地址:https://docs.python.org/2.7/library/datetime.html#time-objects
from datetime import datetime
# 获取当前日期
date = datetime.now()
# 当前是周几(0-6)
day = date.weekday()
# 当前是周几(1-7)
day = date.isoweekday()
# 当前是几点(24小时)
hour = date.hour
# 日期转格式化字符串:方式1
date.strftime('%Y-%m-%d %H:%M:%S')
# 日期转格式化字符串:方式2
date_str = '%s-%s-%s' % (date.year, date.month, date.day)
# 字符串转日期
datetime.strptime('2017-09-12 10:16:31', '%Y-%m-%d %H:%M:%S')
输出结果:
# 当前日期'.'后面是微秒,即date.microsecond
2017-09-12 09:43:00.400000
# 周四
3
# 周四
4
# 上午9点
9
# 格式化后的日期:方式1
2017-09-12 09:43:00
# 格式化后的日期:方式2。区别就是方式1格式化后的月份小于10的时候自己默认补0
2017-9-12
使用 time 模块
strftime()和strptime()日期格式化字符含义
| 符号 | 说明 | 例子 |
|---|---|---|
| %a | 星期几的英文简写 | Sun, Mon, …, Sat (en_US) So, Mo, …, Sa (de_DE) |
| %A | 星期几的英文全拼 | Sunday, Monday, …, Saturday (en_US) Sonntag, Montag, …, Samstag (de_DE) |
| %w | 星期几的数字表示 0-6 | 0, 1, …, 6 |
| %d | 一个月中的第几号,不足10的十位补零 | 01, 02, …, 31 |
| %b | 月份英文简写 | Jan, Feb, …, Dec (en_US) Jan, Feb, …, Dez (de_DE) |
| %B | 月份英文全拼 | January, February, …, December (en_US) Januar, Februar, …, Dezember (de_DE) |
| %m | 月份数字表示,不足10的十位补零 | 01, 02, …, 12 |
| %y | 年份表示,不带世纪数(年份后两位), 不足10的十位补零 |
00, 01, …, 99 |
| %Y | 年份表示,带世纪数 (四位) | 1970, 1988, 2001, 2013 |
| %H | 24小时,不足10的十位补零 | 00, 01, …, 23 |
| %I | 12小时,不足10的十位补零 | 01, 02, …, 12 |
| %p | AM,PM | AM, PM (en_US) am, pm (de_DE) |
| %M | 分钟,不足10的十位补零 | 00, 01, …, 59 |
| %S | 秒,不足10的十位补零 | 00, 01, …, 59 |
| %f | 微秒,不足10的十位补零 | 000000, 000001, …, 999999 |
| %z | UTC offset in the form +HHMM or -HHMM (empty string if the the object is naive). |
(empty), +0000, -0400, +1030 |
| %Z | 时区名(empty string if the the object is naive). | (empty), UTC, EST, CST |
| %j | 一年中的第几天,不足10的十位补零 | 001, 002, …, 366 |
| %U | 一年中的第几周,周日作为每一周的第一天, 不足10的十位补零 |
00, 01, …, 53 |
| %W | 一年中的第几周,周一作为每一周的第一天, 不足10的十位补零 |
00, 01, …, 53 |
| %c | 与系统环境匹配的日期和时间的表示 | Tue Aug 16 21:30:00 1988 (en_US) Di 16 Aug 21:30:00 1988 (de_DE) |
| %x | 与系统环境匹配的日期的表示 | 08/16/88 (None) 08/16/1988 (en_US) 16.08.1988 (de_DE) |
| %X | 与系统环境匹配的时间的表示 | 21:30:00 (en_US) 21:30:00 (de_DE) |
| %% | 输出’%’字符 | % |
Examples
Downloads
requests
import requests
import time
response = requests.post('http://kq.neusoft.com/imageRandeCode')
now = time.time()
with open('%s.jpg' % now, 'wb') as file:
file.write(response.content)
urllib
from urllib import request
request.urlretrieve('http://kq.neusoft.com/imageRandeCode', '%s.jpg' % now)
PIL(Pillow)
import requests
from PIL import Image
''' ===== bytes-like object === '''
# 二元组
size = 50, 15
response = requests.post('http://www.xxx.com/imageRandeCode')
img = Image.frombytes('RGB', size, response.content)
img.save('%s.jpg' % now, 'JPG')
''' ===== file-like object ===== '''
response = requests.post('http://www.xxx.com/imageRandeCode')
# io.BytesIO() convert the bytes-like object containing the encoded image to file-like object
img = Image.open(io.BytesIO(response.content))
img.save('%s.jpg' % now, 'JPG')
模拟登陆
依赖
- Python3.6.4_x64
- requests: 安装
pip install requests - numpy: 安装
pip install numpy - Pillow(PIL): 官方手册,安装
pip --trusted-host pypi.tuna.tsinghua.edu.cn install -i https://pypi.tuna.tsinghua.edu.cn/simple Pillow - tesseract-ocr: 项目介绍,安装
https://github.com/tesseract-ocr/tesseract/wiki - pytesseract: 安装
pip --trusted-host pypi.tuna.tsinghua.edu.cn install -i https://pypi.tuna.tsinghua.edu.cn/simple pytesseract
环境变量配置
- 配置安装目录
Tesseract_Home=D:\Tesseract-OCR - 将
Tesseract-OCR的安装目录$Tesseract_Home添加到PATH中 - 将数据模型的路径添加到环境变量中
TESSDATA_PREFIX=$Tesseract_Home\tessdata - (可选)下载简体、繁体中文数据模型,下载地址,下载完后放到
$Tesseract_Home\tessdata目录下。
模拟登陆 源码放在github
from PIL import Image
import requests
import re
import io
import urllib.parse
from pytesseract import pytesseract
def kq():
session = requests.session()
response = session.post('http://www.xxxsoft.com/')
name_pattern = re.compile(r'name="(.*?)"')
# response.text 返回 string, response.content 返回 bytes-like object
names = name_pattern.findall(response.text)
value_pattern = re.compile(r'value="(.*?)"')
values = value_pattern.findall(response.text)
binary_img = session.post('http://www.xxxsoft.com/imageRandeCode')
img = Image.open(io.BytesIO(binary_img.content))
img_grey = img.convert('L')
# 二值化,采用阈值分割法,threshold为分割点
threshold = 140
table = []
for j in range(256):
if j < threshold:
table.append(0)
else:
table.append(1)
pytesseract.tesseract_cmd = 'D:\\Tesseract-OCR\\tesseract.exe'
out = img_grey.point(table, '1')
# 验证码识别
validate_code = pytesseract.image_to_string(out)
validate_code = validate_code.strip()
validate_code = validate_code.upper()
print('validate_code = %s' % validate_code)
# 语言包下载 https://github.com/tesseract-ocr/tesseract/wiki/Data-Files
# 下载后放 $Tesseract_Home\tessdata 目录下
# now = time.time()
# validate_code = pytesseract.image_to_string(Image.open('grey_%s.jpg' % now), lang="eng")
# print(validate_code)
params = {
names[1]: values[0],
names[2]: "",
names[3]: "",
names[4]: values[1],
names[5]: "account",
names[6]: "password",
names[7]: validate_code
}
params = urllib.parse.urlencode(params)
headers = {'user-agent': 'mozilla/5.0'}
# 登陆
response = session.post("http://www.xxxsoft.com/login.jsp", timeout=30, headers=headers, params=params)
names = name_pattern.findall(response.text)
print(names)
values = value_pattern.findall(response.text)
print(values)
params = {names[1]: values[0]}
params = urllib.parse.urlencode(params)
# 打卡
response = session.post("http://www.xxxsoft.com/record.jsp", timeout=30, headers=headers, params=params,
allow_redirects=False)
print(response.text)
response.raise_for_status()
cx_Orcale
Configure instant_oracle
Install cx_Oracle
$ pip install cx_Oracle
或者 安装文件的下载地址
注意事项:
- cx_Oracle下载的位数版本一定要和Python的位数版本相同,例如本地装的32位的Python,就一定要装32位的cx_Oracle。
- 本地oracle_instant的版本也必须得是32位的,因为在
import cx_Oracle的时候会出现ImportError: DLL load failed: 找不到指定的模块。的问题,需要将instant_oracle安装目录D:\Oracle\instantclient_11_2中的oci.dll,oraociei11.dll,ocijdbc11.dll添加到\Python27\Lib\site-packages目录下,而oci.dll不同位数的版本下是不一样的。 - 在PyCharm中开发时,如果你的PyCharm是64位的,那么
import cx_Oracle会报错。但是可以运行。
因此必须要保证 Python、cx_Oracle、instant_oracle 位数版本一致,要么都是32位的要么都是64位的。PyCharm 位数版本最好也一致,如果你有强迫症的话。
Note: Custom OCI applications, such as those that bundle Instant Client, may want to link with -rpath set to the directory containing Instant Client 12.1 instead of relying on libraries being in ~/lib.
在MAC系统下出现下面的问题时
ImportError: dlopen(/Library/Python/2.7/site-packages/cx_Oracle.so, 2): Library not loaded: @rpath/libclntsh.dylib.12.1
Referenced from: /Library/Python/2.7/site-packages/cx_Oracle.so
Reason: image not found
手动将@rpath对应的LC_RPATH添加到cx_Oracle.so中,出现上面的问题的详细解释
$ install_name_tool -add_rpath /opt/oracle/instantclient_12_1/ /Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/cx_Oracle.so




