
Reference
Useful Reference
- Kubernetes API Reference Index,包含了
apiserver可操作的所有 API 介绍
Overview
Kubernetes(k8s)是自动化容器操作的开源平台,包括部署、调度和集群扩展。如果你曾经用过 Docker 容器技术部署容器,那么可以将 Docker 看成 Kubernetes 内部使用的低级别组件。Kubernetes 不仅仅支持 Docker,还支持 Rocket,这是另一种容器技术。
Kubernetes 的功能:
- 自动化容器的部署和复制
- 随时扩展或收缩容器规模
- 将容器组织成组,并且提供容器间的负载均衡
- 很容易地升级应用程序容器的新版本
- 提供容器弹性,如果容器失效就替换它,等等…
实际上,使用 Kubernetes 只需一个部署文件,使用一条命令就可以部署多层容器(前端,后台等)的完整集群:
$ kubectl create -f just-single-config-file.yaml
Kubernetes Cluster Architecture
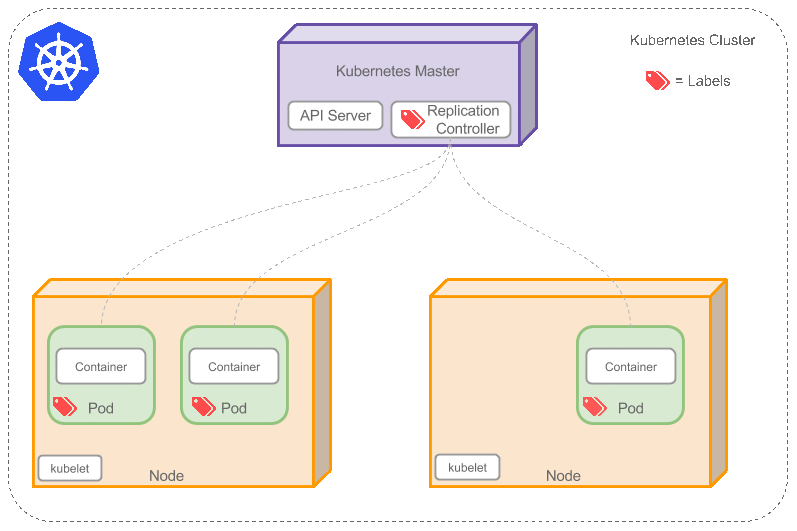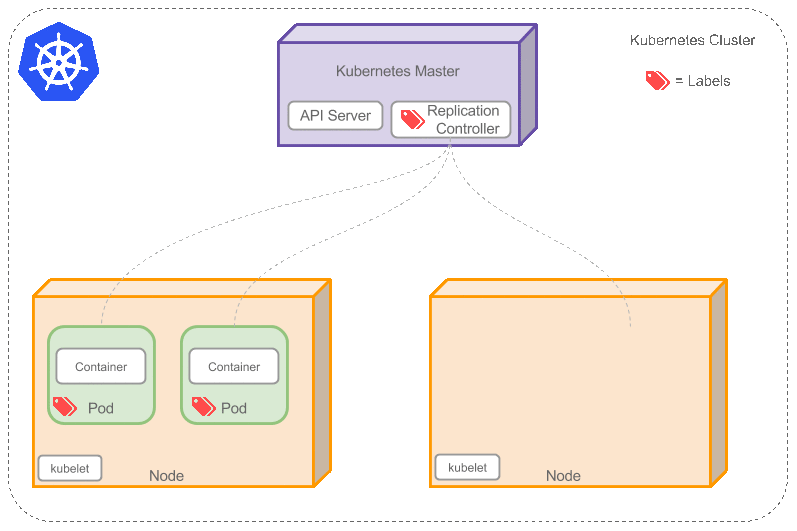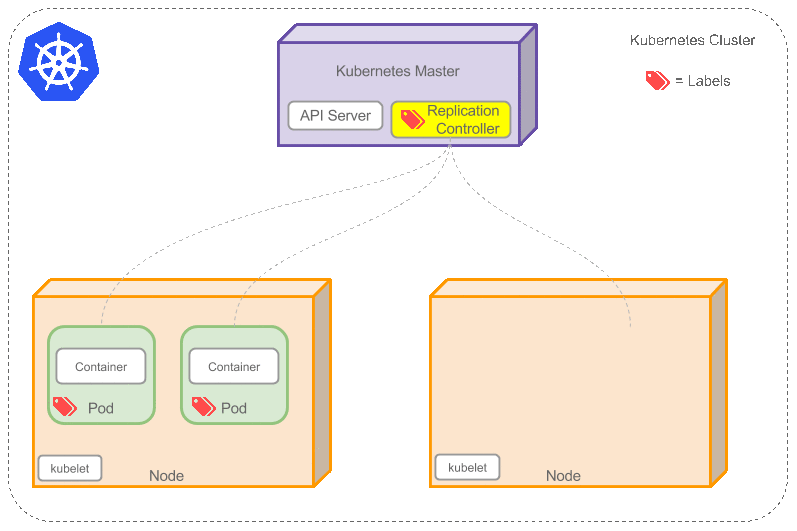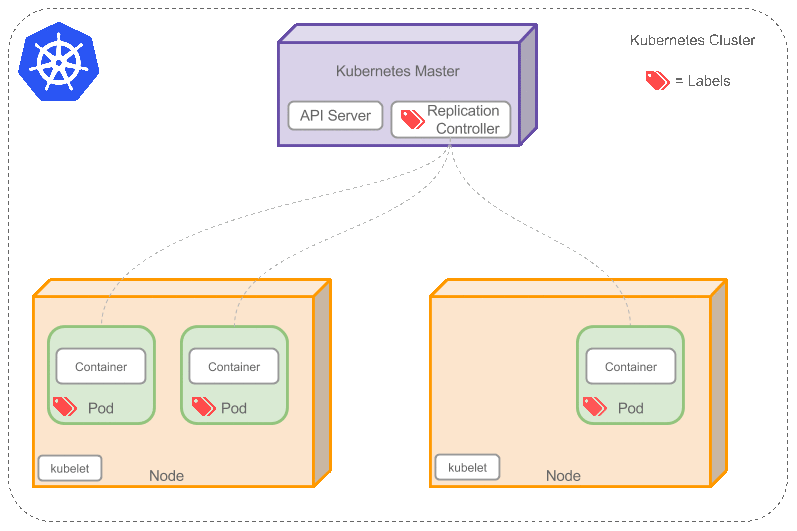
集群是一组节点,它可以是物理服务器或者虚拟机,其上安装了 kubernetes 所需要的组件,如下图所示。
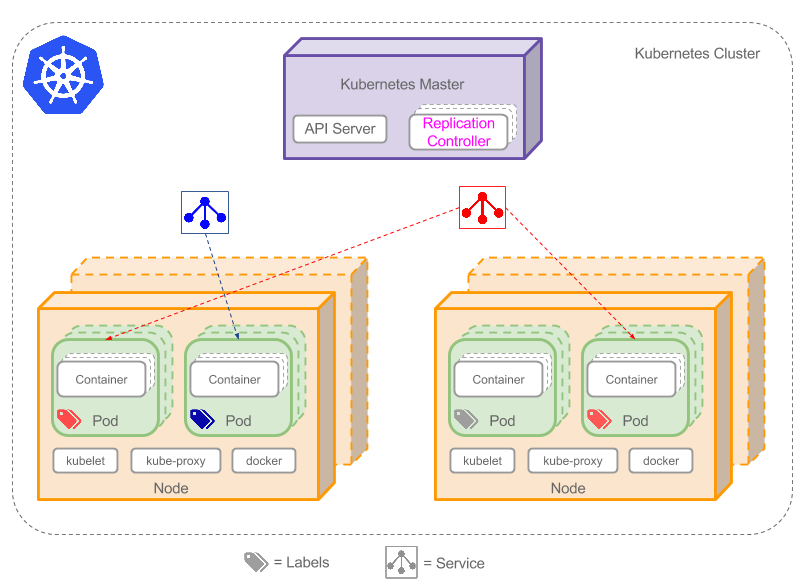
从上图可以看到一些比较关键的组件或属性
- Kubernetes Master
- Replication Controller
- Service
- Node
- Pod
- Container
- Label
Control Pane(Kubernetes Master)
Kubernetes Master 是在集群中的单个节点(Node)上运行的三个进程的集合,它被指定为主节点。 这些进程是:
主节点掌控集群的通信路径主要有两条。
- 从 API Server 到每个 Node 上都会运行的 kubelet 进程。
- 通过 API Server 的代理功能 kube-proxy 连到集群的任何 Node、Pod、Service。
apiserver to kubelet
主要用于:
- 获取 pods 的日志
- attach(通过 kubectl) 到正在运行的 pods 上
- 提供 kubelet 的端口转发功能
apiserver to nodes, pods and services
apiserver 通过 http 连接与 nodes, pods and services 交互
Node
节点(上图橘色方框)是物理或者虚拟机器,作为 Kubernetes Worker(过去称为 Minion)。每个节点都运行如下 Kubernetes 关键组件:
- kubelet:与 kubernetes master 交互。
- kube-proxy:网络代理,反射了每个节点上的 network services。
Standardized Glossary
- Standardized Glossary This glossary is intended to be a comprehensive, standardized list of Kubernetes terminology. It includes technical terms that are specific to Kubernetes, as well as more general terms that provide useful context.
Kubernetes Objects
kubernetes object 可以理解为record of intent,即一旦你创建了一个 object,那么 kubernetes 就会持续保证有这么一个 object 存在。并不是说这个 object 不会出问题,而是就算出问题了,kubernetes 也会新创建一个新 object,一直满足你的record of intent。
想要操作 kubernetes object,比如创建、修改或者删除,就需要 Kubernetes API,关于如何使用 API 详细可以参考api-concepts
- 可以使用 command line,通过kubectl调用 API
- 也可以在应用程序程序中使用client-libraries调用 API。
- 或者直接通过 Restful Request 发送 HTTP 请求
Kubernetes API is RESTful - 客户端通过标准 http 谓词(POST、PUT、DELETE、GET)创建、更新、删除或者检索对象的描述,这些 API 优先接收 JSON 并返回 JSON。kubernetes 还为其他非标准动词公开了额外的端点,并允许其他的内容类型。服务器接收或返回的 JSON 都有一个 Schema,由kind和apiVersion标识。另外所有的 API 公约在API conventions doc中有详细的描述。例如:
- Kind: kind 是表示特定对象的名称,例如
cat和dogkind就会包含不同的字段属性,它又可以分为三种:- Objects: object kind 是意图记录,一旦创建,系统将确保该资源会存在。一个 object 可能具有多个资源,client 可以对这些资源执行增删改查操作。
- Lists: list kind 是一种或更多种类资源的集合。List kind 的 name 必须以
List结尾。所有 list 都需要items字段来包含它们返回的对象数组。任何具有items字段的类型必须是 list kind。 - Simple: simple kind 用于对象和非持久性实体的特定操作
- Resource: 表示系统实体,可以通过 http 以 JSON 的方式从服务器检索。resources 可以表示为
- collections: 一组相同类型的 resources
- element: 一个可以通过URL访问的单独的 resource。
- API Group: 一组公开在一起的 resources,在
apiVersion中显示为GROUP/VERSION,例如policy.k8s.io/v1
每个 kubernetes object 都包含两个嵌套对象字段,用于控制对象的配置:对象规范(specification/spec)和对象状态。规范用于描述对象所需状态(对象应该具有怎样的特征),需要你规定一个规范,提交给 Kubernetes。而状态则是描述对象的实际状态,由 Kubernetes 系统提供和更新。Kubernetes 都时刻监控、管理对象的实际状态,以保证符合规范的所需状态。
例如,Kubernetes Deployment 就是一种 Kubernetes Object。创建 Deployment 时设置 Deployment 规范,希望该应用程序运行三个副本。 Kubernetes 系统读取 Deployment 规范,然后启动三个规范中描述的应用程序实例(更新状态以符合 Deployment 规范)。如果这些实例中的任何一个失败(状态改变),Kubernetes 系统通过进行校正来响应规范和状态之间的差异(在这种情况下,启动替换实例)。
那么如何提供一个规范呢?一般通过 API 操作 object 时,需要在 request body 中提供一个 JSON 用于描述你的 object spec(规范),但大多数情况下是指定一个.yaml文件,kubectl会在请求的时候将它转换成 JSON。一个.yaml例子:
# 其中 apiVersion、kind、metadata、spec 是必须的字段
apiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2
# object 类型,表示当前 object 是哪一种 REST resource
kind: Deployment
# object 的标准 metadata
metadata:
name: nginx-deployment
# 下面就是传说中的规范了(specification)
spec:
selector:
matchLabels:
app: nginx
replicas: 2 # tells deployment to run 2 pods matching the template
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
关于metadata的详细说明会可以参考api-conventions-metadata
不同类型 object 的规范在定义上是有区别的,比如有些 object 会包含特有的字段,所有类型的 object 的 spec 使用说明都可以通过[kubernetes-api](https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.19/)找到
可以通过下面的命令来将.yaml作为参数传递
$ kubectl create -f https://k8s.io/examples/application/deployment.yaml --record
下面来具体的讲解一下 kubernetes objects。
Name
kubernetes REST API 中的所有 object 都由一个 Name 和一个 UID 明确标识。如果用户需要为 object 指定非唯一性的属性,kubernetes API 使用 labels 和 annotations。
Names
name 用于引用资源 URL 中的对象,例如/api/v1/pods/some-name,只有指定 kind 的对象才可以有一个 name,如果删除了一个 object,你可以用这个 name 创建一个具有相同名称的新对象。kubernetes 资源名称的最大长度为253个字符,由小写字母、数字、-、.组成。
UIDs
kubernetes 系统生成的字符串,用于唯一标识 object。在 Kubernetes 集群的整个生命周期中创建的每个对象都具有不同的UID。它旨在区分类似实体的历史事件。
Pod
Pod 是 kubernetes 最基本的构建块 - 你在 kubernetes object model 中能够创建或者发布的最小、最简单的单元。它是一个在你的集群上运行的一个进程。
Pod 封装了单个 container 或者多个紧密耦合的 containers、存储资源(a set of shared storage volumes)、一个唯一的 IP 地址和一些控制 containers 应该怎么运行的 options。启动一个 Pod,可以将其理解为:为一个给定的 Application 启动一个实例。同一个 Pod 里的多个 container 共享存储资源、共享同一个 Network Namespace,可以使用 localhost 互相通信。很少会直接在 kubernetes 中创建 Pod 实例,因为 Pod 被设计为相对短暂的一次性实体。当Pod(由您直接创建或由Controller间接创建)时,它将被安排在群集中的 Node 上运行。 Pod 保留在该节点上,除非进程终止,Pod 对象被删除,Pod 因资源不足而被驱逐,或者 Node 挂掉。
Pod 本身不会自我修复,尽管可以直接使用 Pod,但在 kubernetes 中使用 Controller 是更常见的方式,它是更高级别的抽象,用来处理和管理相对一次性的 Pod 实例。
- 如果 Pod 是短暂的,那么我怎么才能持久化容器数据使其能够跨重启而存在呢?Kubernetes 支持卷(Volume)的概念,因此可以使用持久化的卷类型。
- 是否手动创建 Pod,如果想要创建同一个容器的多份拷贝,需要一个个分别创建出来么?可以手动创建单个 Pod,但是也可以使用 Replication Controller 的 Pod 模板创建出多份拷贝,下文会详细介绍。
- 如果 Pod 是短暂的,那么重启时IP地址可能会改变,那么怎么才能从前端容器正确可靠地指向后台容器呢?这时可以使用 Service,下文会详细介绍。
对于 pod 的一些配置可以参考:configure-pod-container
InitContainer
PauseContainer
Pod Lifecycle
ConfigMaps
使用kubectl cerate configmap从directories、files、literal values创建ConfigMap。
# <map-name> 是分配给configmap的name
# <data-source> 是要提取数据的源,可以是目录、文件或文字值
$ kubectl cerate configmap <map-name> <data-source>
Create ConfigMaps from directories
- 从文件夹创建 configmap
$ mkdir -p configure-pod-container/configmap/kubectl/
$ wget https://k8s.io/docs/tasks/configure-pod-container/configmap/kubectl/game.properties -O configure-pod-container/configmap/kubectl/game.properties
$ wget https://k8s.io/docs/tasks/configure-pod-container/configmap/kubectl/ui.properties -O configure-pod-container/configmap/kubectl/ui.properties
$ kubectl create configmap game-config --from-file=configure-pod-container/configmap/kubectl/
configmap/game-config created
- 查看创建好的 configmap
$ kubectl describe configmaps game-config
Name: game-config
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
game.properties:
----
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
ui.properties:
----
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
Events: <none>
- 以 yaml 格式查看生成的 configmap
$ kubectl get configmaps game-config -o yaml
apiVersion: v1
data:
game.properties: |-
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
ui.properties: |
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
kind: ConfigMap
metadata:
creationTimestamp: 2018-09-18T11:55:00Z
name: game-config
namespace: default
resourceVersion: "9102572"
selfLink: /api/v1/namespaces/default/configmaps/game-config
uid: abc545c3-bb39-11e8-9edf-00163e08ecdb
- 删除 configmap
$ kubectl delete configmap game-config
configmap "game-config" deleted
Create ConfigMaps from files
$ kubectl create configmap game-config --from-file=configure-pod-container/configmap/kubectl/game.properties
# --from-file 可以使用多次以指定多个 data-source
$ kubectl create configmap game-config --from-file=configure-pod-container/configmap/kubectl/game.properties \
--from-file=configure-pod-container/configmap/kubectl/ui.properties
# 使用 --from-env-file 从一个环境变量文件创建 configmap,它会忽略掉其中的#注释和空行
$ wget https://k8s.io/docs/tasks/configure-pod-container/configmap/kubectl/game-env-file.properties -O configure-pod-container/configmap/kubectl/game-env-file.properties
$ cat configure-pod-container/configmap/kubectl/game-env-file.properties
enemies=aliens
lives=3
allowed="true"
# This comment and the empty line above it are ignored
$ kubectl create configmap game-config-env-file \
--from-env-file=configure-pod-container/configmap/kubectl/game-env-file.properties
Note:当使用多次 –from-env-file 指定多个 env 文件创建 configmap 时,只有最后一个 env 文件可以生效!
Secret
- Secret: A Secret is an object that contains a small amount of sensitive data such as a password, a token, or a key.
# 直接创建 secret,这种方式下特殊字符,例如 $、\、! 需要转义例如 S!B\*d$zDsb 需要写为 --from-literal=password=S\!B\\*d\$zDsb
$ kubectl create secret generic "db-user-pass" --from-literal=username=admin --from-literal=password=1f2d1e2e67df
# 从文件创建 secrete,这种方式特殊字符不需要转义
$ echo -n 'admin' > ./username.txt
$ echo -n '1f2d1e2e67df' > ./password.txt
$ kubectl create secret generic "db-user-pass" --from-file=./username.txt --from-file=./password.txt
# 查看 secret
$ kubectl get secrets
NAME TYPE DATA AGE
db-user-pass Opaque 2 51s
$ kubectl describe secrets/db-user-pass
Name: db-user-pass
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password.txt: 12 bytes
username.txt: 5 bytes
base64 编码
# base64 编码
$ echo -n 'admin' | base64
# base64 解码
$ echo 'MWYyZDFlMmU2N2Rm' | base64 --decode
Service
- 假设我们创建了一组 Pod 的副本,那么在这些副本上如何进行负载均衡?
- 如果 Pods 是短暂的,那么重启时 IP 地址可能会改变,怎么才能从前端容器正确可靠地指向后台容器呢?
答案是Service,它定义了一组逻辑 Pods 和访问它们的策略。Service 通过Label Selector 选择一组 Pods。因为 Service 是抽象的,所以在图表里通常看不到它们的存在。
现在,假定有 2 个 backend pod,并且定义 Service 的名称为backend-service,Label Selector 为(tier=backend, app=myapp)。backend-service会完成两件事:
- 为 Service 创建一个本地集群的 DNS 入口,因此 frontend pod 只需要 DNS 解析
backend-service就能够得到前端应用程序可用的 IP 地址。 - frontend 得到后台服务的 IP 地址后,但是它应该访问 2 个 backend pod 的哪一个呢?Service 在这 2 个 backend pod 之间提供透明的负载均衡,会将请求分发给其中的任意一个(如下面的动画所示)。这是通过每个 Node 上运行的代理(kube-proxy)完成的。
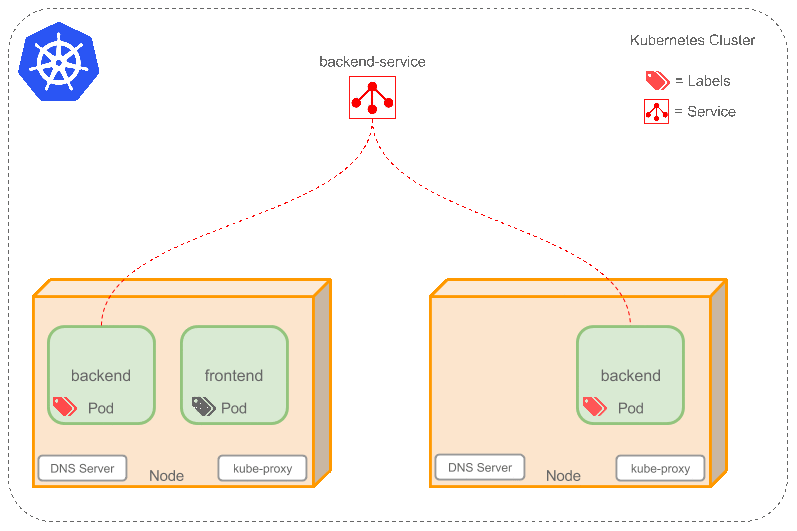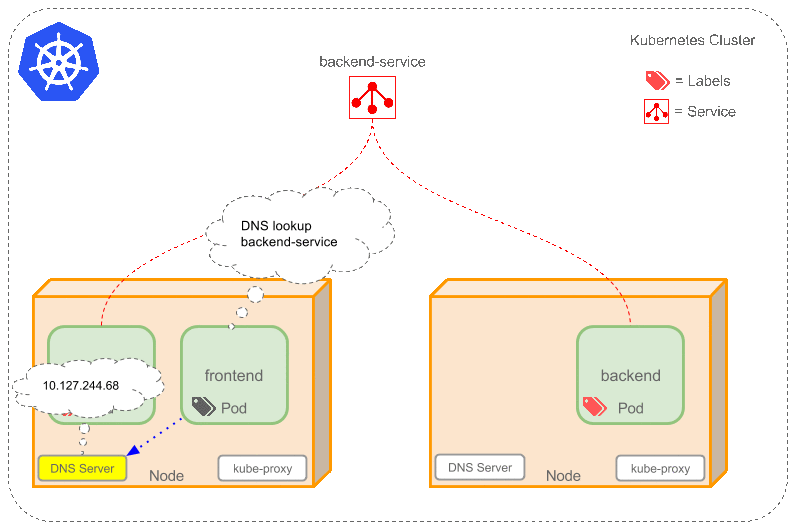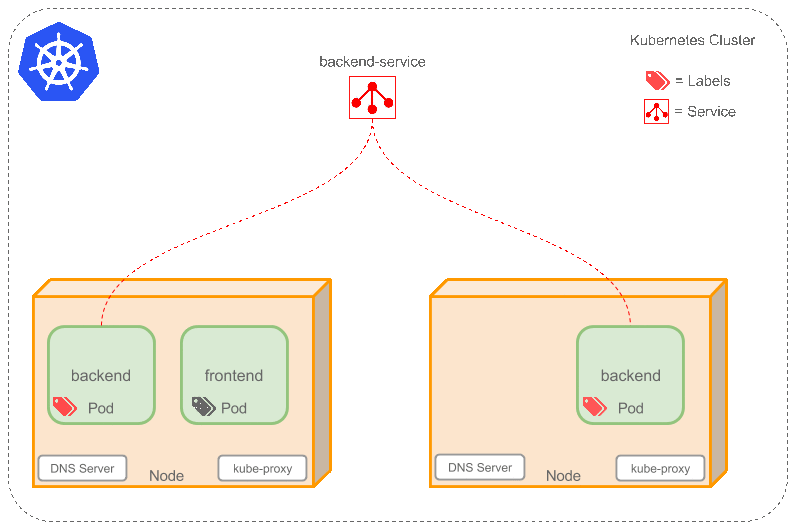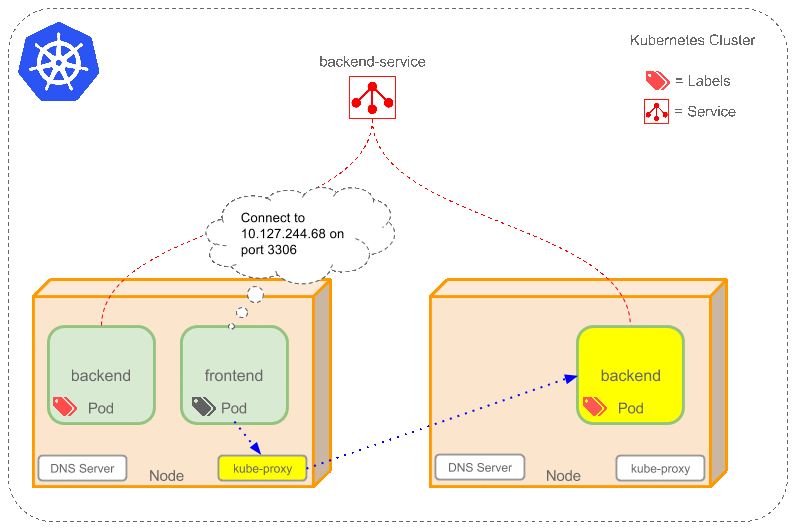
backend pod replicas 是一些可替代的复制品 frontend pods 并不关心它们具体使用的是哪一个 backend pod,尽管实际组成 backend 的 pods 可能会发生变化,但 frontend 不需要关心也不需要跟踪实际的 backend 列表。Service 抽象实现了这种解耦。
对于 kubernetes-native application,kubernetes 提供一个简单的EndpointsAPI,只要 Service 中的 pod 集合发生变化,它就会更新。而对于 non-native applications,kubernetes 提供了一个基于桥接的 Virtual-IP(VIP) 访问 Services,然后重定向到 backend pod。
Define a service
类似 Pod,Service 是 REST object。因此 Service definition 可以 POST request 到 APIServer 创建新实例。假设你有一组暴露了9376端口,并且label为app=MyApp的 pods。
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
# 不指定 type 默认就是 ClusterIP
type: ClusterIP
selector:
app: MyApp
# 当前 service 向外暴露的接口列表
ports:
# 当前 service port 的名称,必须是 DNS_LABEL,且所有 service port name
# 必须是唯一的,它会被映射到 EndpointPort objects 的`name`字段,如果当前
# service 仅定义了 Service port(例如本例),则该属性是可选的
- name: servi
# UDP/TCP/SCTP(kubernetes1.12+),默认 TCP
protocol: TCP
# 当前 service 向外暴露的端口
port: 80
# service 对应的目标 pod 的访问端口信息,可以是端口号(1~65536),或者端口名称(IANA_SVC_NAME)
targetPort: 9376
上面的 spec(规范)将创建一个name=my-service的 Service object,它会定位所有 label 为app=MyApp的 pods 的 TCP 端口9376。除此之外,他还会分配一个 Virtual-IP 地址(有时也称为Cluster IP),给 proxies 使用。Service selector 会被持续评估,然后将结果 POST 到名为my-service的Endpoints对象。
Service 可以将port映射到任意targetPort。如果给targetPort一个字符串,它会查找 target pod 中端口的name(端口名称),这样即便不同 target pod 实际向外暴露的端口号不同,只要name相同就可以了,这为部署和扩展服务提供了很大的灵活性,即便更改 backend pod 的port,对 Service 也没有任影响。如果不指定targetPort则默认被设置为与port相同的端口号。对于clusterIP=None的service,此字段被忽略,即和port相同。
规范参数的详细介绍可以参考ServiceSpec v1 core
Service type
根据创建Service的type类型不同,可分成几种种模式:
ClusterIP: 默认方式。根据是否生成ClusterIP又可分为普通Service和Headless Service两类:普通Service:通过为 Kubernetes 的 Service 分配一个集群内部可访问的固定虚拟IP(Cluster IP),实现集群内的访问。为最常见的方式。Headless Service:该服务不会分配Cluster IP,也不通过kube-proxy做反向代理和负载均衡。而是通过DNS提供稳定的网络ID来访问,DNS会将headless service的后端直接解析为podIP列表。主要供StatefulSet使用。
NodePort:除了使用Cluster IP之外,还通过将Service的port映射到集群内每个节点的相同一个端口,实现通过nodeIP:nodePort从集群外部访问服务。LoadBalancer:和NodePort类似,不过除了使用一个Cluster IP和NodePort之外,还会向所使用的公有云申请一个负载均衡器(负载均衡器后端映射到各节点的NodePort),实现从集群外通过LB访问服务。ExternalName:是 Service 的特例。此模式主要面向运行在集群外部的服务,通过它可以将外部服务映射进k8s集群,且具备k8s内服务的一些特征(如具备namespace等属性),来为集群内部提供服务。此模式要求kube-dns的版本为1.7或以上。这种模式和前三种模式(除headless service)最大的不同是重定向依赖的是 dns 层次,而不是通过 kube-proxy。
Virtual IPs and service proxies
kubernetes cluster 中的每个 node 都会运行一个kube-proxy,它负责为 Services 实现虚拟的 IP,ExternalName类型的 Service 除外。这个 IP 相对固定,只要不删除 Service, ClusterIP 就不会变。
kubernetes proxy-mode 目前有这么几种,userspace(k8s/v1.0 add)、iptables(k8s/v1.1 add)、ipvs(k8s/v1.8.0-beta.0 add)
- userspace:
kube-proxy会监听Master(apiserver)的添加或删除Service和Endpointsobjects的行为。对于每一个 Service,都会在本地 node 随机打开一个端口(代理端口),代理端口(下图中的kube-proxy)的所有连接都会转发到 Service 的 backend pods 之一(根据 Service 的 SessionAffinity 决定使用哪个 backend pod)。Service 会根据安装的 iptables rules,捕获流量到 Service 的clusterIP(虚拟)和port,并将流量重定向到代理 backend pod 的代理端口,最终转发到 backend pods 之一。默认情况下循环选择 backend。
- iptables: k8s/v1.2+ 默认的 proxy-mode。
kube-proxy会监听Master(apiserver)的添加或删除Service和Endpointsobjects的行为。对于每个 Service,会安装 iptables rules 捕获流量到 Service 的clusterIP和port,然后重定向到 backend pods 之一。对于每个Endpointsobject,它会安装 iptables rules 用于选择一个 backend pod。默认选择 backend 是随机的。显然,iptables不需要在 userspace(用户空间)和 kernelspace(内核空间)之间切换,他比 userspace proxy 更快、更可靠。但是,与 userspace proxy 不同的是,如果最初选择的 pod 没有响应时,iptables proxy 无法自动重试另一个 pod,因此它还需要依赖一个就绪探测器(readiness probes) - ipvs:
kube-proxy会监听Service和Endpoints,调用netlink接口去创建相应的 ipvs rules 并定期与Service和Endpoints同步 ipvs rules,以确保 ipvs 状态与期望一致,当访问Service时,流量将被重定向到其中一个 backend pod。类似 iptables,ipvs 基于 netfilter hook function,但是使用哈希表作为底层数据结构并在 kernelspace 中工作。这意味着 ipvs 可以更快的重定向流量,并且在同步 proxy rules 时具有更好的性能。此外,ipvs 还为负载均衡算法提供了更多选项。例如:rr:循环赛、lc:最少连接、dh:目的哈希、sh:源哈希、sed:最短的预期延迟、nq:永不排队。需要注意的是,ipvs 模式假定在运行kube-proxy之前在 node 上安装了 IPVS 内核模块。当kube-porxy以 ipvs 代理模式启动时,kube-proxy会验证节点上是否安装了 IPVS 模块,如果没有安装,则会回退到 iptables 代理模式。
对于 virtual IPs 的详细内容参考The gory details of virtual IPs
DNS for Services and Pods
Note: Since CoreDNS is now the default, kube-dns is now available as an optional DNS server.
kube-dns 可以解决 Service 的发现问题,k8s 将 Service 的名称当做域名注册到kube-dns中,通过 Service 的名称就可以访问其提供的服务。
实际上kube-dns插件只是运行在kube-system命名空间下的 Pod,完全可以手动创建它。可以在k8s源码(v1.2)的cluster/addons/dns目录下找到两个模板(skydns-rc.yaml.in和skydns-svc.yaml.in)来创建
通过skydns-rc.yaml文件创建kube-dns Pod,其中包含了四个 Containers:
- etcd: 它的用途是保存DNS规则,是一种开源的分布式 key-value存储,其功能与ZooKeeper类似。在
kube-dns中的作用为存储skydns需要的各种数据,写入方为kube2sky,读取方为skydns。 - kube2sky: 作用是写入 DNS 规则
- skydns: 是用于服务发现的开源框架,构建于
etcd之上。作用是为 kubernetes 集群中的 Pod 提供 DNS 查询接口 - exec-healthz: 是k8s提供的一种辅助容器,多用于 side car 模式中。它的原理是定期执行指定的 Linux 指令,从而判断当前 Pod 中关键容器的健康状态。在
kube-dns中的作用就是通过nslookup指令检查 DNS 查询服务的健康状态,k8s livenessProbe 通过访问exec-healthz提供的 Http API 了解健康状态,并在出现故障时重启容器。
有了 Pod 之后,还需要创建一个 Service 以便集群中的其他 Pod 访问 DNS 查询服务。通过skydns-svc.yaml创建 Service
目前最新的版本可以参考kube-dns.yaml
kube-dns支持的域名格式,具体为:<service_name>.<namespace>.svc.<cluster_domain>,其中cluster_domain可以使用kubelet的–cluster-domain=SomeDomain参数进行设置,同时也要保证kube2sky容器的启动参数中–domain参数设置了相同的值。通常设置为cluster.local。
既然完整域名是这样的,那为什么在 Pod 中只通过<service_name>.<namespace>就能访问 Service 呢?
Verify DNS
我们可以使用 kubernetes 内置的 imagebuzybox测试一下 DNS,如果还要测试网络可以使用cirros,它包含了常用的网络命令,如curl, ping等等
$ kubectl run buzybox --rm -ti --image=busybox /bin/sh --namespace test
$ kubectl run cirros --rm -ti --image=cirros /bin/sh --namespace test
$ kubectl get pods --namespace test
NAME READY STATUS RESTARTS AGE
busybox-7cd98849ff-t5qbh 1/1 Running 0 53s
cirros-8584959b4f-frr7c 1/1 Running 0 26s
metadata-test-7fdc74749-nvm7q 1/1 Running 0 12h
$ kubectl get service --namespace test -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
metadata-test ClusterIP 10.43.226.228 <none> 8088/TCP 1d app=metadata-test
metadata-test-nodeport NodePort 10.43.48.104 <none> 8088:30638/TCP 1d app=metadata-test
$ kubectl exec -it cirros-8584959b4f-frr7c /bin/sh --namespace test
/ # curl http://metadata-test:8088/metadata/swagger-ui.html
<!-- HTML for static distribution bundle build -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Swagger UI</title>
<link rel="stylesheet" type="text/css" href="webjars/springfox-swagger-ui/springfox.css?v=2.9.2" >
<link rel="stylesheet" type="text/css" href="webjars/springfox-swagger-ui/swagger-ui.css?v=2.9.2" >
...
# 删除 pod,可以看到一个新的 buzybox 又起来了,这是在确保 replicas 为 1 的 intent
$ kubectl delete pod busybox-7cd98849ff-t5qbh --namespace test
NAME READY STATUS RESTARTS AGE
busybox-7cd98849ff-gjtsd 1/1 Running 0 15s
busybox-7cd98849ff-t5qbh 1/1 Terminating 0 1m
$ kubectl get deployment --namespace test
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
busybox 1 1 1 1 17m
cirros 1 1 1 1 5m
$ kubectl delete deployment busybox --namespace test
deployment.extensions "busybox" deleted
Ingress
Ingress is an API object that manages external access to the services in a cluster, typically HTTP. Ingress can provide load balancing, SSL termination and name-based virtual hosting. Ingress exposes HTTP and HTTPS routes from outside the cluster to services within the cluster. Traffic routing is controlled by rules defined on the Ingress resource.
Volume
Container 中的文件是短暂的,当 Container 崩溃后 kubelet 会重新启动它,但是文件会丢失。Volume 用来持久化文件,并在 Container 之间共享它们。kubernetes 支持很多类型的 Volumes,如 configMap、hostPath、local、secret 等等。
Persist Volume (PV) & Persist Volume Claim (PVC)
- Persistent Volumes
Storage Class (SC)
- Storage Classes
Namespace
kubernetes 支持由统一物理集群支持的多个虚拟集群。这些虚拟集群就称为Namespace。
Controllers
除此之外。kubernetes 还包含一些高级抽象,称为 Controllers。Controllers 基于基本对象构建,并提供一些便利的功能和特性,下面简单介绍下,详细的可以参考官方文档。
Replication Controller
Replication Controller用于创建和复制 Pod,Replication Controller 确保任意时间都有指定数量的 Pod 副本在运行。如果为某个 Pod 创建了 Replication Controller 并且指定 3 个副本,它会创建3个Pod,并且持续监控它们。如果某个 Pod 不响应,那么 Replication Controller 会替换它,保持总数为 3 如下面的动画所示:
如果之前不响应的Pod恢复了,现在就有4个Pod了,那么Replication Controller会将其中一个终止保持总数为3。如果在运行中将副本总数改为5,Replication Controller会立刻启动2个新Pod,保证总数为5。还可以按照这样的方式缩小Pod,这个特性在执行滚动升级时很有用。
当创建Replication Controller时,需要指定两个东西:
- Pod 模板:用来创建Pod副本的模板
- Label:Replication Controller 需要监控的 Pod 的标签。
ReplicaSet
ReplicaSet 是下一代的 Replication Controller,大多数支持 Replication Controllers 的 kubectl 命令也支持 ReplicaSet。目前,他们唯一的区别就是 ReplicaSet 支持新的 set-based selector requirements,而 Replication Controller 仅支持 equality-based selector requirements。
ReplicaSet 保证在任何时候都有指定数量的 pod 副本在运行。
Deployment 是一个更高抽象的概念,它用来管理 ReplicaSet 并为 pod 提供声明式的更新以及很多其他有用的功能。因此,除非需要 custom update orchestration 或者根本不需要更新,更建议使用 Deployment 而不是直接使用 ReplicaSet。
这实际就意味着可能永远不需要直接操作 ReplicaSet object,而是使用 Deployment,并在 spec 部分定义应用程序。
ReplicaSet 有这么几个替代方案,Deployment(推荐)、Bare Pods、Job、DaemonSet
Deployment
Deployment 为 Pod 和 ReplicaSet 提供声明性更新,在 Deployment object 描述一个期望的状态,然后 Deployment controller 就会将实际的状态按照 controller rate 转换成期望的状态。你可以定义 Deployments 来创建一个新的 ReplicaSets,或者删除已经存在的 Deployments 并且用新的 Deployments 更新资源状态。
应该操作 Deployment object 来涵盖所有的用例,而不是直接管理属于 Deployment 的 ReplicaSet
典型的常用用例
- 创建一个 deployment 来部署 replicaSet
- 通过更新 deployment object 的 spec 来声明 pods 的新状态(更新),然后按照 controlled rate 创建一个新的 replicaSet,最后将 pods 从旧的 replicaSet 移动到新的 replicaSet,每个新的 replicaSet 都会更新 deployment 的 revision。
- 如果当前状态的 deployment 不稳定,可以回滚到之前的版本
- 扩展 deployment 以增加负载
- 暂停 deployment,将多个修改应用于 PodTemplateSpec,恢复并启动一个新的部署。
- 使用 deployment 的状态作为部署卡住的标志
- 清理不在需要的旧 replicaSet
StatefulSet
StatefulSet是 workload API object,用于管理有状态的应用程序。
StatefulSet 在 1.9 版本开始稳定(GA - General Availability,软件通用版本)
statefulSet 管理一组 pods 的部署和扩展,并提供这些 pods 排序和唯一性的保证
与 deployment 类似,statefulSet 管理基于相同容器 spec 的 pod。不同的是,statefulSet 为其管理的每个 pod 维护一个粘性标识。这些 pod 是根据相同的 spec 创建的,但是不可以互换:每个 pod 都会保留一个持久的标识符,它可以在重新调度的时候使用。
典型的常用用例:
- 需要稳定、唯一的网络标识符
- 稳定、持久化的存储
- 有序、优雅的部署、扩展、删除和终止
- 有序的自动滚动更新
在上文中,稳定是指可跨 pod 持久性的调度/重新调度。如果应用程序不需要任何稳定标识符或者有序部署、删除或扩展,则应该使用一组无状态的副本的控制器来部署应用程序,例如 Deployment 或 ReplicaSet。
DNS Name 命名规则: $podName.$headlessServiceName.$namespace.svc.$clusterDomain e.g.: clickhouse-.clickhouse.dlink-prod.svc.cluster.local 最简单的方式是直接 exec 到 pod 中直接查看
$ cat /etc/hosts
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
fe00::0 ip6-mcastprefix
fe00::1 ip6-allnodes
fe00::2 ip6-allrouters
10.244.194.173 clickhouse-0.clickhouse.dlink-prod.svc.cluster.local clickhouse-0
DaemonSet
DaemonSet 确保所有(或某些指定的) Node 会运行 Pod 的副本,随着 Node 添加到集群中,他会将 Pod 添加到新的 Node 中,当 Node 从集群中删除时,他也会确保 Pod 会被垃圾收集。删除 DaemonSet 会清除它所创建的 Pod。
DaemonSet 的应用场景:
- 在每个节点上运行集群存储的守护进程,如
glusterd、ceph - 在每个节点上运行日志收集守护进程,如
fluentd、logstash、filebeat - 在每个节点上运行节点监视的守护进程,如
Prometheus Node Exporter、collectd、Dynatrace OneAgent、Datadog agent、New Relic agent、Ganglia gmond
下面写一个 DaemonSet Spec,我们先创建一个daemonset.yaml运行 fluentd-elasticsearch Docker image。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: k8s.gcr.io/fluentd-elasticsearch:1.20
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
Garbage Collection
Job-run to completion
CronJob
Label and Selectors
Label 是 attach 到 Pod 的一个键/值对,用来传递用户定义的属性。比如,你可能创建了一个tier和app标签,通过Label(tier=frontend, app=myapp)来标记前端Pod容器,Label(tier=backend, app=myapp)标记后台Pod。然后可以使用 Selectors 选择带有特定 Label 的一组 Pods,并且将 Service 或者 Replication Controller 应用到匹配到的这组 Pods 上面。
Using kubectl
使用 kubectl 与 kubernetes 集群交互
kubectl-commands
kubectl yaml 配置项
Accessing the kubernetes API (Authorization)
Controlling Access to the Kubernetes API
controlling access to the kubernetes API
用户使用kubectl、client library、REST requests来访问 kubernetes API。用户可以理解为两种:human user和kubernetes service(process run in pods)。我们将这两种用户分别称为user account和service account。他们都可以获得 API 访问权限。
当请求到达API时,会经历几个阶段,如下图所示:

在典型的 Kubernetes 集群中,API server 在端口443上提供服务。API server 提供一个证书。此证书通常是自签名的,你通常可以在 kubernetes master 上的~/.kube/config中找到 API server 的根证书。除此之外,这个config的user是管理员角色,它拥有整个集群所有资源的管理和访问权限!当使用kube-up.sh自己创建群集时,此证书通常会自动写入$USER/.kube/config。如果群集有多个用户,则创建者需要与其他用户共享证书。
Authentication (认证)
一旦 TLS 被建立,HTTP 请求就会进入 Authentication(认证)阶段,即上图中的step1。集群创建脚本或者集群管理员配置 API server 去运行一到多个身份认证模块,更多关于认证器的描述可以参考Authenticator
身份认证步骤的输入是整个HTTP请求,但是他通常只检查 headers/client certificate。
身份认证模块包括 Client Certificates(客户端证书)、Password(密码)和 Plain Tokens(普通令牌),对于 Bootstrap Tokens(引导令牌) 和 JWT Tokens(JWT令牌) 则用于 service accounts
可以指定多个认证模块,每个认证模块按顺序尝试,直到其中一个成功。
在 GCE 上,Client Certificates(客户端证书)、Password(密码)、Plain Tokens(普通令牌)和 JWT Tokens(JWT令牌)都已启用。
如果请求无法通过身份认证,则会被拒绝访问并返回401。如果通过认证,会被认定为一个特定的username,该用户名用于后续的步骤的决策。某些身份认证器还提供用户的组成员身份。
虽然 Kubernetes 使用username进行访问控制决策和请求日志记录,但他没有 user object,也没有在其对象库中存储用户名或者有关用户的其他信息。
Authorization (授权)
当 request 认证成功并指定username之后,request 就会进入授权阶段(上图step2)
一个 request 必须包含请求者的用户名、请求的操作以及要操作的对象。如果现有的策略声明用户有权完成请求的操作,则对该请求进行授权。
例如:如果 Bob 有下面的策略,那么他只能在 namespace projectCaribou 中读取 pod:
{
"apiVersion": "abac.authorization.kubernetes.io/v1beta1",
"kind": "Policy",
"spec": {
"user": "bob",
"namespace": "projectCaribou",
"resource": "pods",
"readonly": true
}
}
下面的读取操作是允许的,因为他在namespace=projectCaribou是有读取权限的
{
"apiVersion": "authorization.k8s.io/v1beta1",
"kind": "SubjectAccessReview",
"spec": {
"resourceAttributes": {
"namespace": "projectCaribou",
"verb": "get",
"group": "unicorn.example.org",
"resource": "pods"
}
}
}
如果他要向namespace=projectCaribou的对象进行写(create/update)操作,就会被拒绝。同样的如果他向其他namespace的对象执行读(get)操作也会被拒绝。
Kubernetes 支持多种授权模块,例如ABAC模式,RBAC模式和Webhook模式。当管理员创建集群时,他们配置了应在 API server 中使用的授权模块。如果配置了多个授权模块,Kubernetes 将检查每个模块,如果任何一个模块对请求进行了授权,则请求就可以继续。如果所有模块拒绝该请求,则拒绝该请求并返回403。
要了解有关Kubernetes授权的更多信息,包括使用支持的授权模块创建策略的详细信息,可以参阅Authorization Overview。
Admission Control
准入控制模块是可以修改和拒绝请求的模块。除了授权模块可用的属性,准入模块还可以访问正在创建或更新的对象内容。他们对正在创建、删除、更新或连接(代理)的对象起作用,但对读取不起作用。
可以配置多个准入控制器,按顺序调用,如上图的step3。
与身份验证和授权模块不同,如果任何准入控制器模块拒绝,则会立即拒绝该请求。
除了拒绝对象之外,准入控制器还可以为字段设置复杂的默认值。
对于可用的准入控制模块的更多描述可以参考Using Admission Controllers
一旦请求通过所有的admission controllers,就会使用相应API对象的验证程序对其进行验证,然后将其写入对象库(object store),如上图step4所示。
API Server Ports and IPs
上面提到的适用于发送到 API serversecure port的请求。API server 实际上可以在两个端口上提供服务,默认为Localhost Port和Secure Port。
- Localhost Port(本地端口)
- 主要用于测试和引导,以及主节点的其他组件(scheduler,container-manager)与API通信。
- no TLS
- 默认端口
8080,可以用--insecure-port修改 - 默认IP是
localhost,可以用--insecure-bind-address修改 - 请求会绕过(bypass) authentication 和 authorization 模块
- 请求由 admission control 模块处理
- 需要拥有主机的访问权限
- Secure Port(安全端口)
- 尽可能使用安全端口。
- 使用 TLS。使用
--tls-cer-file设置证书,使用--tls-private-key-file设置密钥。 - 默认端口
6443,可以用--secure-port修改 - 默认IP是第一个非
localhost网络接口,可以用--bind-address修改 - 请求由 authentication 和 authorization 模块处理
- 请求由 admission control 模块处理
- authentication and authorization modules run.
当群集由kube-up.sh,Google Compute Engine(GCE)以及其他几个云提供商创建时,API server 在端口443上运行。在GCE上,在项目上配置防火墙规则以允许外部HTTPS访问API。其他群集设置方法各不相同
Managing Service Accounts
Configure Service Accounts for Pods
configure service account for pods
一个 Service Account 为在 Pod 中运行的进程提供一个标识。
当你访问集群时(例如,使用kubectl),apiserver 会授权你一个特定的 User Account(通常是admin,如果集群管理员没有自定义过的话)。pod 中容器内的进程也可以访问 apiserver,当他们这样做的时候,他们就会被认证为特定的 Service Account(例如default)。
当创建一个 pod 的时候,如果没有指定 Service Account,那么会在同一 namespace 中自动分配一个默认的 Service Account。可以通过kubectl get pod podname -o yaml看到spec.serviceAccountName字段已经被自动设置。
...
spec:
serviceAccount: default
serviceAccountName: default
...
你可以使用 automatically mounted service account 从 pod 中访问 apiserver,像Access the API from a pod中描述的那样。service account 的权限取决于正在使用的授权插件和策略。
在1.6+版本,可以通过在 service account 上进行如下设置,选择退出 service account 的自动挂载 api 凭据
apiVersion: v1
kind: ServiceAccount
metadata:
name: build-robot
automountServiceAccountToken: false
...
或者指定某个 pod 退出 service account 的自动挂载 api 凭据,并且在 pod 指定的优先级更高,它会覆盖在 ServiceAccount 的指定。
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
serviceAccountName: build-robot
automountServiceAccountToken: false
...
每一个 namespace 都有一个默认的 service account resourcedefault
$ kubectl get serviceAccounts
NAME SECRETS AGE
default 1 48d
Using RBAC Authorization
- using RBAC authorization 在 kubernetes 1.6之前,主要的授权策略是 ABAC(Attribute-Based Access Control)。对于ABAC,其实是比较难用的,而且需要 Mastser Node 的 ssh 和 root 文件系统的访问权限,当授权策略发生变化的时候还需要重启 API Server。
在 kubernetes 1.6+,RBAC(Role-based access control)进入 beta 阶段,RBAC 是一种基于用户角色来管理对计算/网络资源访问的方法。official reference
RBAC 使用rbac.authorization.k8s.io API group来控制授权决策,它允许管理员通过 Kubernetes API 直接为用户动态的配置访问策略,这样就不用操作 Master Node 了。要启用 RBAC 使用--authorization-mode=RBAC启动 API Server。使用kubeadmin初始化的1.6+版本会默认为 API Sever 开启 RBAC。
可以查看 Master Node 上 API Server 的静态 Pod 定义文件来验证:
$ cat /etc/kubernetes/manifests/kube-apiserver.yaml | grep RBAC
- --authorization-mode=Node,RBAC
也可以动态查看 api server pod 的 yaml 文件验证
$ kubectl get pods --namespace=kube-system | grep apiserver
kube-apiserver-cn-beijing.i-2ze3ym7umglfdb8lqwun 1/1 Running 2 49d
kube-apiserver-cn-beijing.i-2ze56bpwjuxguhc8xv9n 1/1 Running 2 49d
kube-apiserver-cn-beijing.i-2zeb3eh8po9pdz819vvj 1/1 Running 2 49d
$ kubectl get pod kube-apiserver-cn-beijing.i-2ze3ym7umglfdb8lqwun -o yaml --namespace=kube-system | grep RBAC
- --authorization-mode=Node,RBAC
RBAC API 定义了四个资源对象用于描述 RBAC 中 user 和 resource 之前的访问权限:
- Role
- ClusterRole
- RoleBinding
- ClusterRoleBinding
Role 和 ClusterRole
在 RBAC 中,role 定义一组权限规则。权限纯粹是附加的(没有拒绝规则)。可以在namespace中定义一个Role,或者在集群范围内定义ClusterRole。
Role只能用于授予单个namespace内的资源访问权限,下面是namespace=default的一个示例,用于授予对 pod 的读取权限
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: default
name: pod-reader
rules:
- apiGroups: [""] # "" indicates the core API group
resources: ["pods"]
verbs: ["get", "watch", "list"]
ClusterRole可以分配和Role相同的权限,但是由于他是cluster-scoped,所以它还能分配下面的权限
- cluster-scoped resources(like
nodes) - non-resource endpoints(like
/healthz) -
namespaced resources(like
pods) across all namespaces(need to runkubectl get pods --all-namespace, for example) - What’s apiGroups of kuber
下面是一个ClusterRole的示例,可用于授予对任何特定 namespace 或所有 namespaces 中secrets的读取权限(取决于它的绑定方式):
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
# "namespace" omitted since ClusterRoles are not namespaced
name: secret-reader
rules:
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get", "watch", "list"]
RoleBinding 和 ClusterRoleBinding
RoleBinding将role中定义的权限授予用户或一组用户。它包含一个subjetcs列表(user、group 或者 service accounts),以及要授予给用户的角色引用。可以使用RoleBinding在某个namespace上为用户/用户组(accounts)授于Role,也可以使用ClusterRoleBinding在cluster-scope上为用户/用户组(accounts)授予权限。
RoleBinding可以引用同一namespace中的Role,下面的RoleBinding将 Rolepod-reader授予namespace=default中的用户jane。这样jane就可以读取namespace=default中的pod。
# This role binding allows "jane" to read pods in the "default" namespace.
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: read-pods
namespace: default
subjects:
- kind: User
name: jane # Name is case sensitive (区分大小写)
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role # this must be Role or ClusterRole
name: pod-reader # this must match the name of the Role or ClusterRole you wish to bind to
apiGroup: rbac.authorization.k8s.io
RoleBinding还可以引用ClusterRole,以授予 ClusterRole 中定义的namespaced resources权限。 这允许管理员为整个集群定义一组公共角色,然后在多个namespace中重用它们。
例如,即使以下RoleBinding引用ClusterRole,用户dave(subjects,区分大小写)也只能读取development namespace(RoleBinding 的 namespace)中的secrets。
# This role binding allows "dave" to read secrets in the "development" namespace.
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: read-secrets
namespace: development # This only grants permissions within the "development" namespace.
subjects:
- kind: User
name: dave # Name is case sensitive
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: secret-reader
apiGroup: rbac.authorization.k8s.io
最后,ClusterRoleBinding可以分配cluster level和所有namespace的权限。下面的ClusterRoleBinding允许组manager中的任何用户读取任何namespace中的secrets。
# This cluster role binding allows anyone in the "manager" group to read secrets in any namespace.
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: read-secrets-global
subjects:
- kind: Group
name: manager # Name is case sensitive
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: secret-reader
apiGroup: rbac.authorization.k8s.io
Referring to Resources
大多数resources由一个字符串name表示。例如pods,就像它出现在相关 API endpoint 的 URL 中一样。但是,一些 Kubernetes API 涉及subresource像pod的logs,pod logs endpoint的 URL 就表示为:
GET /api/v1/namespaces/{namespace}/pods/{name}/log
这种情况下pods是 namespaced resource,而log是pod的子资源,要以 RBAC Role 表示的话,需要用斜杠/来分割 resource 和 subresource。要允许subject读取pod和pod log可以这么写:
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: default
name: pod-and-pod-logs-reader
rules:
- apiGroups: [""]
resources: ["pods", "pods/log"]
verbs: ["get", "list"]
对于某些resourceNames列表中的请求,可以通过resource的name引用resource。指定时,使用get、delete、update和patch动词的请求可以限制某个resource实例。如将subject限制为仅get和update一个configmap实例,可以这么写:
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: default
name: configmap-updater
rules:
- apiGroups: [""]
resources: ["configmaps"]
resourceNames: ["my-configmap"]
verbs: ["update", "get"]
Note:如果设置了resourceNames,则verbs不能是
list、watch、create或deletecollection。由于这些 verbs 的 API 请求的 URL 中不存在资源名称,所以 resourceNames 不允许使用这些 verbs,因为规则的 resourceNames 部分与请求不匹配。
Kubernetes logging architecture
logging at the node level
所有容器化应用程序写入stderr和stdout的所有内容都会被容器引擎处理并重定向到某个地方。例如: Docker 就会将这两个streams重定向到logging-driver,logging-driver=json-file将会把日志以 JSON 的格式写到/var/lib/docker/containers下。
但是 docker json logging driver 会按行来区分每一条日志,如果你想处理多条日志,就需要在 logging agent 作处理了。
另一个比较重要的考虑因素是实现日志轮换,以防止日志占用节点所有的存储资源。kubernetes 目前没有实现日志轮换的功能,但是 deployment tool 应该提供一个解决方案来解决这个问题。例如,kube-up.sh脚本部署时,有一个logrotate工具,可以配置为每小时运行一次;或者在运行 docker container 时指定log-opt。第一种方法可以用于任何其他环境,而后一种方法用于 GCP 的 COS 映像。这两种方法默认都会在日志文件超过10M的时候进行轮换。
Note: 如果某个外部系统已经执行了轮换,则只有最新的日志文件内容可以被
kubectl logs获得。例如:有一个10M的文件,logrotate执行轮转后,就会生成两个文件,一个10M,一个为空,当执行kubectl logs时会返回一个空的响应。
system component logs
系统组件的日志有两种:运行在容器中的和非运行在容器中的。例如 kubernetes scheduler 和 kube-proxy 就运行在 container 中,而 kubelet 和 docker 就不运行在 container 中。
在有systemd的机器上,kubelet 和 docker 会写到journald,如果systemd不可用就会写到/var/log目录下。在容器中的系统组件会把日志直接写在/var/log目录下。类似容器日志,在/var/log目录下的系统组件日志也会进行轮换,这些日志被logrotate配置为每天或者日志文件超过100M时进行轮换。
logging at cluster level
然而 kubernetes 没有为 cluster-level logging 提供一个原生的解决方案,但是有一些通用的方法可以考虑,例如:
- 在集群的每个节点上运行一个 node-level 的 logging-agent(专门用于将日志推送到后台的工具,如
fluentd、logstash、filebeat) - 在 application pod 中包含一个专门用于日志收集的 sidecar container
- 在应用程序直接将日志推送到后台日志服务器
下面分别来介绍一下这三种方法
Using a node-level logging agent
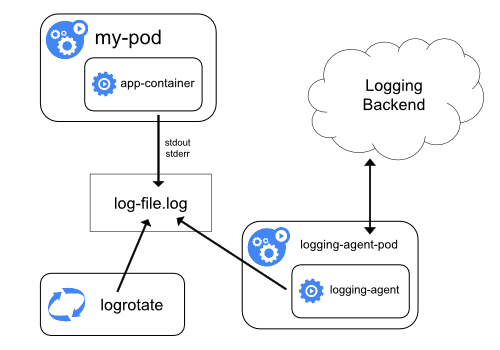
在每个节点上创建一个有日志目录访问权限的 logging-agent,常规的实现方式
- 使用 DamonSet Replica
- 使用 manifest pod
- 在节点上启动一个专门用于处理日志的原生进程。
但是后两种非常不推荐使用。另外 node-level logging agent 只能处理standard output和standard error。
Using a sidecar container with the logging agent
首先解释一下什么叫 sidecar,sidecar 就是与应用程序一起运行的独立进程,为应用程序提供额外的功能。更多了解可以读一下这篇关于Service Mesh的文章。
有两种使用 sidecar container 的方式:
- sidecar container 将应用程序日志传输到自己的 stdout/stderr,我们称他为 streaming sidecar container。然后通过 logging-agent-pod 将日志发送到 logging backend。
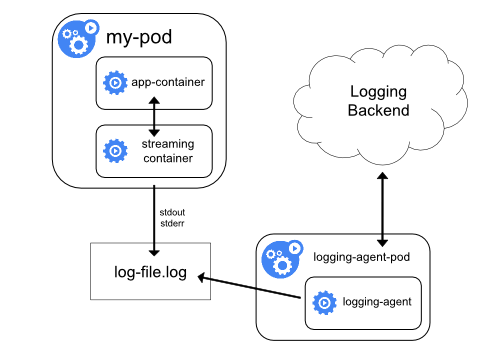
这种方式可以将不同类型的日志进行分流,例如下面的 yaml 所示:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
从上面的配置文件可以看到,application container 会输出两种类型的日志文件/var/log/1.log和/var/log/2.log。然后有两个 sidecar container 分别将两个日志文件分流到自己的 stdout 和 stderr。这样在运行这个 pod 的时候,就可以通过下面的方式单独获取某种类型的日志。
$ kubectl logs counter count-log-1
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
$ kubectl logs counter count-log-1
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
而安装在每个节点的 logging-agent-pod 会自动搜集这些日志,甚至可以直接去读取解析源容器的日志文件,然后将日志发送到 logging backend。
需要注意的是,使用 streaming sidecar container 将日志流传输到 stdout 会使磁盘使用量增加一倍,如果只是单个的日志文件写入,最好还是直接写到
/dev/stdout,而不是使用 streaming sidecar container。
最后 sidecar container 还可用于旋转应用程序本身无法旋转的日志文件。 这种方法的一个例子是定期运行 logrotate 的小容器。 但是,建议直接使用 stdout 和 stderr,并将循环和保留策略保留给 kubelet。
- sidecar container 运行日志记录的代理程序,该代理程序会从应用程序容器中读取日志,然后直接将日志发送到后端。
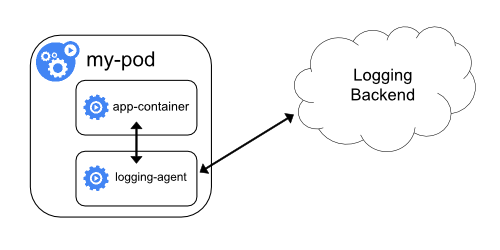
如果 node level logging-agent 不够灵活,可以创建一个带有单独日志记录功能的 sidecar container,他与主应用程序一起运行。
注意:在 sidecar container 中使用日志代理会导致大量的资源消耗,并且无法使用 kubectl logs 访问这些日志,因为他们不受 kubelet 控制。
可以使用Stack driver,他使用 fluentd 作为 logging agent。可以通过下面的两个配置文件实现这个方法:
第一个文件包含一个用来配置 fluentd 的ConfigMap,更多关于配置 fluentd 的信息可以参考official fluentd documentation
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
第二个文件描述了一个包含 fluentd 的 sidecar container,并且该 pod 安装了一个 fluentd 可以获取它配置数据的 volume。
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: k8s.gcr.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
一段时间后,就可以在 stack driver 洁面中找到日志信息。这只是一个示例,实际上可以用任何 logging-agent 替代 fluentd,从应用程序 container 内的任何源读取日志。
Exposing logs directly from the application
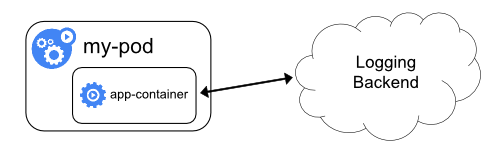
这种方式就是直接通过应用程序 container 将日志写到 logging backend,例如配置 log4j 到 kafka、redis、elasticsearch 等等。 但是这种日志机制就超出 kubernetes 的范畴了。
日志文件路径
kubernetes 的日志都写在/var/log/containers下:
ls -l /var/log/containers
总用量 68
lrwxrwxrwx 1 root root 90 9月 5 17:05 miami-group-understanding-test-67f55d4775-m4ct7_default_miami-group-understanding-test-7d57ebfab3b2590f06d2994e86e1254064e8d38c96c10d3007e4eddeb5c91178.log -> /var/log/pods/7f3ce883-acc8-11e8-b97b-00163e062f63/miami-group-understanding-test/1484.log
lrwxrwxrwx 1 root root 65 8月 2 18:19 monitoring-influxdb-6c54fbb78-fg64f_kube-system_influxdb-7cf9d0d3dca87e79a6d52eb6584c773801177a9019f80924d19b15b300ef9019.log -> /var/log/pods/3443796f-9637-11e8-9628-00163e08aadb/influxdb/1.log
lrwxrwxrwx 1 root root 65 8月 2 18:20 monitoring-influxdb-6c54fbb78-fg64f_kube-system_influxdb-a4b743d315325410e3b061c96b92c90d377831cfae89bd0126176fa882fdfd5a.log -> /var/log/pods/3443796f-9637-11e8-9628-00163e08aadb/influxdb/2.log
...
可以看到这里面的日志都是一些软连接,实际指向/var/log/pods下:
ls -l /var/log/pods/7f3ce883-acc8-11e8-b97b-00163e062f63/miami-group-understanding-test/1484.log
lrwxrwxrwx 1 root root 165 9月 5 17:05 /var/log/pods/7f3ce883-acc8-11e8-b97b-00163e062f63/miami-group-understanding-test/1484.log -> /var/lib/docker/containers/7d57ebfab3b2590f06d2994e86e1254064e8d38c96c10d3007e4eddeb5c91178/7d57ebfab3b2590f06d2994e86e1254064e8d38c96c10d3007e4eddeb5c91178-json.log
从上面可以看出最终实际的日志文件在/var/lib/docker/containers下面,实质还是 docker container 中的日志文件。
Scheduling and Eviction
Kubernetes Scheduler
Taints and Tolerations
Taints and Tolerations,翻译过来就是污点和容忍,Taints 是对于 Node 来说的,而 Tolerations 是对于 Pod 来说的。对于他们的关系也非常简单,举个比较简单的例子,如果你女朋友长得非常好看但是常常内裤和袜子一起洗(Taints),并且她也不可能听你的,现在我要向你发出灵魂拷问,你,能不能容忍?在这个例子当中,你女朋友就是 Node,而你就是个 Pod,能容忍你就可以被调度到她那儿(Scheduling),反之就会被驱逐(Eviction)。
Assigning Pods to Nodes
Extend the Kubernetes API with CustomResourceDefinitions
Extend the Kubernetes API with CustomResourceDefinitions




