
HDFS
HDFS 是 Hadoop 的分布式文件系统的实现,主要包含
- NameNode
- SecondaryNameNode
- DataNode
- JournalNode
HDFS Components and Architecture
NameNode
The NameNode manages the filesystem namespace. It maintains the filesystem tree and the metadata for all the files and directories in the tree. This information is stored persistently on the local disk in the form of two files: the namespace image and the edit log.
NameNode Metadata & Checkpoint
NameNode Metadata 包含了整个集群的文件状态,这些都存储在内存当中,而磁盘上的存储由fsimage和edits组成。
fsimage存储上次checkpoint生成的元数据镜像edits记录文件系统的操作日志,而checkpoint的过程,就是合并fsimage和edits,生成新fsimage,删除旧edits的过程
查看 fsimage 和 edits 内容
# 查看 fsimage 文件
$ hdfs oiv -p XML -i fsimage_file_name -o fsimage_output.xml
# 查看 edits 文件
$ hdfs oev -i edits_file_name -o edits_output.xml
NameNode Memory
从 NameNode 架构上来看,NameNode 管理的内存可以分为四大块
- NameSpace:维护整个文件系统的目录树结构及目录树上的状态变化
- BlockManager:维护整个文件系统中与数据块相关的信息及数据块的状态变化
- NetworkTopology:维护机架拓扑及 DataNode 信息,机架感知的基础
- Others:略
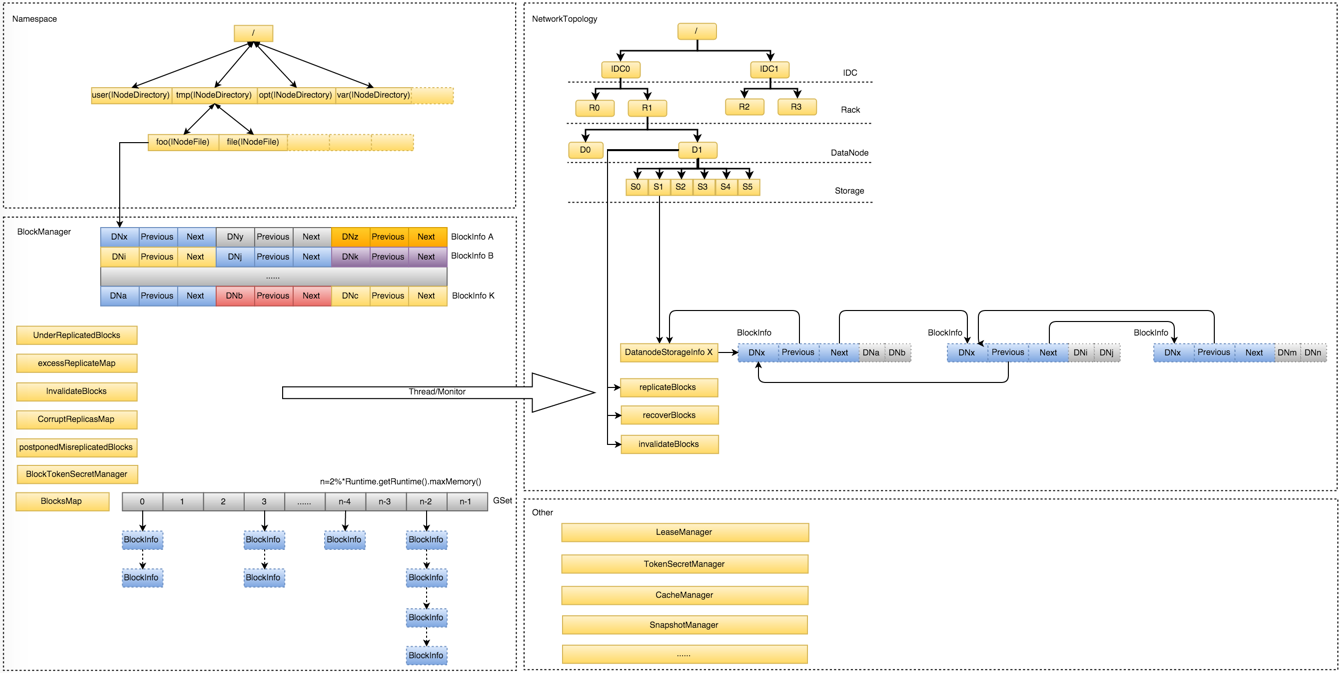
其中 NameNode 的大部分内存消耗主要在 NameSpace 以及 BlockManager 中,其他部分的内存使用相对较小且固定,基本可以忽略不计。
NameSpace
和传统单机文件系统类似,HDFS 的目录与文件结构也是以树的形式进行维护的,目录和文件分别由INodeDirectroy和INodeFile表示,而INodeFile中又包含了构成该文件的存储块信息BlockInfo[] blocks。内存大小估算公式如下
Total INodeDirectroy = (24 + 96 + 48 + 44) ∗ num(total directories) + 8 ∗ num(total children),其中total children = total directories + total filesTotal INodeFile = (24 + 96 + 48) ∗ num(total files) + 8 ∗ num(total blocks)
BlockManager
HDFS 中的文件会切割为多个 Block 进行存储,Block 是 HDFS 最基本的存储单元,默认一个 Block 128MB。为了保证数据可靠性,默认情况下,一个 Block 会有 3 Replications,而每个 Replication 分布在不同的 DataNode 上,除了 Block 本身的信息外,NameNode 还需要维护 Block 和 DataNode 的映射关系,来表示每个 Block Replication 实际的物理存储位置,这些信息都被封装在 BlockInfo 对象中。BlocksMap 的核心功能是通过 BlockID 快速定位到具体的 BlockInfo,为了解决内存使用、碰撞冲突和性能等方面的问题,BlocksMap 使用 LightWeightGSet 代替 HashMap,为了尽可能避免碰撞冲突,BlocksMap 会在初始化时直接分配整个JVM 堆空间的 2% 作为 LightWeightGSet 的索引空间。内存大小估算公式如下
LightWeightGSet = 16 + 24 + 2% ∗ size(JVM Heap)Total BlockInfo = (40 + 128) ∗ num(total blocks)
NameNode 内存膨胀后的问题
随着集群数据规模的扩张,NameNode 的内存占用也会随之线性增加,不可避免的会达到内存瓶颈,从而出现问题
- 启动时间变长,极端情况下甚至超过 60 min
- 性能下降,HDFS 的读写请求均需要 NameNode 的元数据查询,元数据的操作基本上都需要在 NameNode 上完成,内存变大之后元数据的增删改查效率都会下降。
- FullGC 频率增加,时间变长且不可控,极端情况下可以达到数百秒,导致服务不可用
- 线上分析 JVM 会成为一件异常困难的事情,Dump 本身极其费时费力,Dump 超大内存时有极大概率会使得 NameNode 不可用
优化的方向一般两种
- 水平扩展 NameNode,解决单点的内存限制问题,典型的如 Federation
- 垂直优化 NameNode 内存占用。根据上面的内存占用分析,可以很直观的看出 NameNode 的内存占用主要取决于三个参数 num(total directories), num(total files), num(total blocks),只要减少这三个参数的数量,就能降低 NameNode 的内存使用
- 对于小文件比较多的场景,最简单的就是将小文件合并,这样会同时减少 num(total files), num(total blocks) 的数量,典型的如 HAR, Sequence Files, Avro Fils,缺点也很明显打包后的文件就变成了只读文件,无法执行 append 操作,只能解包重新打包;或者使用 HBase MOB,以 KV 的方式存储,但这样就破坏了目录结构。对于小文件问题,社区也有大量有趣的讨论:
- HDFS-8998,Small Files Zone ,不过由于 Ozone 的方案更通用,社区并没有采用该设计方案
- HDFS-7240,Ozone,提供新的 Block Layer,Hadoop Distributed Storage Layer (HDSL)。它通过将块分组到容器中来扩展块层,从而减少块到存储位置的映射,以及块报告和其处理的数量。
- 对于超大文件而言,可以适当调整 dfs.blocksize 的大小,例如调整到 256MB,这样可以减少 num(total blocks) 的数量。
- 通过数据治理,业务上有些文件,可以合并到同一个文件夹,减少 num(total directories),但这个需要的成本相当高,且收益不明显,ROI 比较低。
Secondary NameNode and Standby NameNode
The SecondaryNameNode, which despite its name does not act as a NameNode. Its main role is to periodically merge the namespace image with the edit log to prevent the edit log from becoming too large.
In without HA mode, HDFS will have NameNode and Secondary NameNode. Here, Secondary NameNode periodically take a snapshot of NameNode and keep the metadata and audit logs up to date. So in case of NameNode failure, Secondary NameNode will have copy of latest NameNode activity and prevent data loss.
In HA mode, HDFS have two set of NameNodes. One acts as active NameNode and another acts as Standby NameNode. The duties of standby NameNode is similar to Secondary NameNode where it keeps the track of active NameNode activity and take a snapshot periodically. Here, in case of active NameNode failure, standby NameNode automatically takes the control and becomes active. This way user will not notice the failure in NameNode. This way High availability is guaranteed.
JournalNode
在 HA mode,两个 NameNode 为了数据同步,会通过一组称作 JournalNodes(Journal, 通报) 的独立进程进行相互通信。当active状态的 NameNode 的命名空间有任何修改时,会告知大部分的 JournalNodes 进程。standby状态的 NameNode 有能力读取 JNs 中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了。
DataNode
…
HDFS Configurations
- official docs -> configurations -> core-default.xml
- official docs -> configurations -> hdfs-default.xml
Meanings of Common ports
| 参数 | 描述 | 默认 | 配置文件 | 例子值 |
|---|---|---|---|---|
| fs.default.name NameNode | NameNode RPC 交互端口 | 8020 | core-site.xml | hdfs://master:8020/ |
| dfs.http.address | NameNode web 管理端口 | 50070 | hdfs-site.xml | 0.0.0.0:50070 |
| dfs.datanode.address | DataNode 控制端口 | 50010 | hdfs-site.xml | 0.0.0.0:50010 |
| dfs.datanode.ipc.address | DataNode 的 RPC 服务器地址和端口 | 50020 | hdfs-site.xml | 0.0.0.0:50020 |
| dfs.datanode.http.address | DataNode 的 HTTP 服务器地址和端口 | 50075 | hdfs-site.xml | 0.0.0.0:50075 |
HDFS Shell Commands
查看所有 NameNode
$ hdfs getconf -NameNodes
master002.hadoop.data.xxxxxxxxx.com master001.hadoop.data.xxxxxxxxx.com
# 查看 HA 服务名称
$ hdfs getconf -confKey dfs.nameservices
sensetime-shnew-hadoop
查看 NameNode 的状态
- active
- standby
$ vim $HADOOP_HOME/hdfs-site.xml
<property>
<name>dfs.nameservices</name>
<value>xxxxxx-data-hadoop</value>
</property>
<property>
<name>dfs.ha.NameNodes.xxxxxx-data-hadoop</name>
<value>nn0,nn1</value>
</property>
$ hdfs haadmin -getServiceState nn0
查看 hdfs 全局和各个 datanode 磁盘使用情况
$ hdfs dfsadmin -report
Filesystem Size Used Available Use%
hdfs://hadoop3:8020 7.0 T 2.2 T 3.2 T 32%
[hdfs@hadoop1 ~]$ hdfs dfsadmin -report
# 集群汇总信息
Configured Capacity: 7692823298048 (7.00 TB) # 集群配置容量
Present Capacity: 5998111523068 (5.46 TB) # 当前容量,可能有节点挂掉或者其他原因导致磁盘空间不可用
DFS Remaining: 3554867421066 (3.23 TB) # 集群剩余容量
DFS Used: 2443244102002 (2.22 TB) # 集群数据实际占用物理容量
DFS Used%: 40.73% # DFS Used / Present Capacity
Under replicated blocks: 713 # 没有 replica 的 blocks 数量
Blocks with corrupt replicas: 0 # replica 损坏的 blocks 数量
Missing blocks: 0 # 丢失的 blocks
Missing blocks (with replication factor 1): 0 # 丢失的 blocks(只有一个副本的 block,换言之就是数据对于 HDFS 来讲是彻底丢了)
-------------------------------------------------
Live datanodes (4):
# 集群具体某个节点的汇总信息
Name: 192.168.51.23:50010 (hadoop3)
Hostname: hadoop3
Decommission Status : Normal
Configured Capacity: 1923205824512 (1.75 TB)
DFS Used: 653372555985 (608.50 GB)
Non DFS Used: 396316900655 (369.10 GB)
DFS Remaining: 871685526740 (811.82 GB)
DFS Used%: 33.97%
DFS Remaining%: 45.32%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 14
Last contact: Wed May 29 16:14:10 CST 2019
Last Block Report: Wed May 29 13:44:34 CST 2019
...
清理回收站
# 从 trash 目录中永久删除早于保留阈值的检查点中的文件,并创建新的检查点。创建检查点时,垃圾箱中最近删除的
# 文件将移动到检查点下。 早于`fs.trash.interval`的检查点中的文件将在下次调用 -expunge 命令时被永久删除。
# 受影响的目录是当前用户 /user/{current_user}/.Trash 目录
$ hadoop fs -expunge
修改文件副本数量
# 首先 dfs.replication 这个参数是个 client 参数,即 node level 参数。需要在每台 datanode 上设置,默认为 3
# 可以在上传文件的同时指定创建的副本数,如果你只有 3 个datanode,但是你却指定副本数为4,是不会生效的,因为每个
# datanode 上最多只能存放一个副本。
$ hadoop fs -D dfs.replication=1 -put 70M logs/2
# 一个文件,上传到 hdfs 上时指定的是几个副本就是几个。即便你修改了 dfs.replication 副本数,对已经上传了的文件
# 也不会起作用,但可以通过命令来更改已经上传的文件的副本数。如果指定的 path 是个目录,则递归的更改该目录下所有文件的副本数
# -w 表示等待副本操作结束才退出命令,这可能需要很长时间
# -R 目录内递归生效,为了兼容,其实默认就是该效果
$ hadoop fs -setrep [-R] [-w] <numReplicas> <path>
查看指定路径 hdfs 的副本情况
$ hdfs fsck -locations <path>
Total size: 583921551399 B (Total open files size: 450 B)
Total dirs: 56028
Total files: 244955
Total symlinks: 0 (Files currently being written: 6)
Total blocks (validated): 234496 (avg. block size 2490113 B) (Total open file blocks (not validated): 5)
Minimally replicated blocks: 234496 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 481 (0.20512077 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 3.002051
Corrupt blocks: 0
Missing replicas: 1476 (0.20922963 %)
Number of data-nodes: 4
Number of racks: 1
FSCK ended at Thu May 16 14:51:42 CST 2019 in 3711 milliseconds
# 查看文件(注意是文件,文件夹看不到)的副本数,这里可以看到副本数是 3
$ hadoop fs -ls /apps/hive/warehouse/du.db/indices/dt=2017-09-01
-rw-r--r-- 3 root hadoop 72395047 2019-05-15 15:26 /apps/hive/warehouse/du.db/indices/dt=2017-09-01/part-00919-7aef8d30-1b51-4ad6-9336-81a39870aeba.c000.snappy.orc
统计文件大小
# 统计当前文件夹下每个文件/文件夹的大小
# -h 数据大小单位转换成人比较方便看的方式
$ hadoop fs -du -h /data
# 按单副本算(即逻辑空间,实际物理占用空间=逻辑空间*副本数量)
167.8 G /data/Remote
120.4 T /data/XXX
6.2 T /data/business-dev
39.9 T /data/connector
420.6 T /data/datum
5.0 G /data/facebank
18.3 T /data/gitlab
...
# 查看某个文件夹的数据大小
# -s 将所有文件累加,这里是将/data下所有文件和文件夹大小累加
$ hadoop fs -du -s -h /data
1.9 P /data
集群间数据传输
$ hadoop distcp [options] sourcePath targetPath
# 拷贝深圳集群的数据到当前集群(北京)
$ hadoop distcp hdfs://master002.hadoop-sz.data.sensetime.com/user/sre.bigdata/onedata/metadata hdfs:///user/sre.bigdata/onedata/aggregate/hadoop-sz/metadata
HDFS 集成 Keberos 认证
HDFS 集群原理与调优
TB 大文件上传性能优化
NameNode 上千 QPS 优化
Linux 文件系统
推荐使用xfs或ext4,centos7.0开始默认文件系统是xfs,centos6是ext4,centos5是ext3,ext3和ext4的最大区别在于,ext3在fsck时需要耗费大量时间,文件越多,时间越长。而ext4在fsck时用的时间会少很多。
ext4(Fourth Extended Filesystem, 第四代扩展文件系统)是 Linux 系统下的日志文件系统,是ext3的后继版本。ext4的文件系统容量达到1EB,最大单以文件容量则达到16TB,这是一个非常大的数字了。对一般的台式机和服务器而言,这可能并不重要,但对于大型磁盘阵列的用户而言,这就非常重要了。ext3目前只支持32000个子目录,而ext4取消了这一限制,理论上支持无限数量的子目录。Ext家族是 Linux 支持度最广、最完整的文件系统,当我们格式化磁盘后,就已经为我们规划好了所有的inode/block/metadata等数据,这样系统可以直接使用,不需要再进行动态的配置,这也是它的优点,不过这也是它最显著的缺点,磁盘容量越大,格式化越慢,centos7.x 已经选用xfs作为默认文件系统,xfs是一种适合大容量磁盘和处理巨型文件的文件系统。
xfs是一种非常优秀的日志文件系统,它是SGI公司设计的。xfs被称为业界最先进的、最具可升级性的文件系统技术。xfs是一个64位文件系统,最大支持8EB - 1Byte的单个文件系统,实际部署时取决于宿主操作系统的最大块限制。对于一个 32 位 Linux 系统,文件和文件系统的大小会被限制在16TB。xfs在很多方面确实做的比ext4好,ext4受限制于磁盘结构和兼容问题,可扩展性(scalability)确实不如xfs,另外xfs经过很多年发展,各种锁的细化做的也比较好。但是xfs文件系统不能缩小,当删除大量文件时性能会下降。
Common Exceptions
FileNotFoundException
莫名其妙的出现找不到文件的问题,有可能是因为文件的某一级路径中包含你看不到的特殊字符,而你不知道
# 可以看到有两个 /data/datum/pile
$ hadoop fs -ls /data/datum | cat -A
Found 11 items$
drwxrwxr-x+ - data-ops data 0 2018-11-28 19:55 /data/datum/migration$
drwxrwx---+ - robot_data data 0 2019-02-20 15:49 /data/datum/pile$
drwxrwxr-x+ - zhengshuai zhengshuai 0 2018-09-04 18:55 /data/datum/pile^M$
# 重命名的话,通过重定向写到脚本文件中,注意:直接复制这个字符在shell中执行是无效的,它会认为是普通字符,而非那个你正常看不到的字符
$ hadoop fs -ls /data/datum > modify.sh
# 注意脚本中的 ^M 不是你手动写的,而是重定向写进文件的,保留这个字符,将其他没用的东西删掉改成下面的脚本,然后执行就行了
$ vim modify.sh
hadoop fs -mv /data/datum/pile^M /data/datum/pile




