
JobManager 是 Dispatcher、集群框架特定的 ResourceManager、BlobServer 和一组 JobMaster(每个 Job 一个)的集合
Checkpoints
Flink 是有状态的流式计算引擎,因此需要定期将状态保存到文件系统,这样在任务重启和 Failover 的时候就可以从最近一次成功的 Checkpoint 中恢复,达到数据处理的 Exactly Once 语义
当数据的 Sink 实际写入(或下游可见)与 Checkpoint 绑定就可以实现端到端的 Exactly Once 语义
Flink 通过 CheckpointingMode.AT_LEAST_ONCE、CheckpointingMode.EXACTLY_ONCE 控制具体的语义实现方式
Checkpoints 如何保证 Exactly Once 语义
结论:Checkpoint Barrier 对齐机制实现 Exactly-Once 语义。如果 Barrier 不对齐,即 At Least Once 语义。
Checkpoint barrier 在单条数据流中下发
一文搞定 Flink Checkpoint Barrier 全流
Flink master git commit id: b076c52d8da914e81c3e004c0b0c7883463bb151 (HEAD -> master, origin/master, origin/HEAD) [FLINK-33044][network] Reduce the frequency of triggering flush for the disk tier of tiered storage
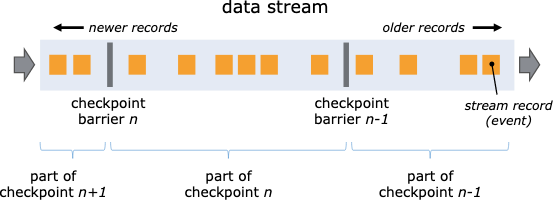
- 在 Flink Job 启动的时候会通过 startCheckpointScheduler() 在 CheckpointCoordinator 中启动 CheckpointScheduler,其实是一个定时任务,每隔
execution.checkpointing.interval的时间,定时执行ScheduledTrigger.run() -> triggerCheckpoint(...) -> startTriggeringCheckpoint(...) -> OperatorCoordinatorCheckpoints.triggerAndAcknowledgeAllCoordinatorCheckpointsWithCompletion(...)发送给应用所有的 OperatorCoordinator - 接着在 TaskExecutor 上调用 Task.triggerCheckpointBarrier(…),委托给 SourceStreamTask 调用
triggerCheckpoint(...) -> StreamTask.performCheckpoint(...),开始具体执行一次 checkpoint- operatorChain.prepareSnapshotPreBarrier(…) 准备 preBarrier,整个链路开始出现 barrier 消息
- operatorChain.broadcastCheckpointBarrier(…) 将 barrier 消息广播到 streamSourceOperator 的下游,下游 operator 接收到 barrier 消息就会触发当前 operator 的 checkpoint
- checkpointState() 执行实际的 checkpoint 操作,将 StreamSourceOperator 的 state 写到 checkpoint 文件
sourceTaskChain 是通过 triggerCheckpoint(…) 执行 checkpoint 的,而非 sourceTaskChain 是通过 processBarrier(…) 来执行 checkpoint 的。 需要注意的是主动触发 checkpoint 的只有 triggerOperator(在生成 ExecutionGraph 时会生成 triggerOperator,ackOperator,confirmOperator,这些 task 本质上是 operatorChain) ,triggerOperator 可以简单的理解成 streamSourceOperator。 换言之,streamSourceOperator 触发了 checkpoint, 一直到把 checkpoint barrier 广播到下游,具体广播到下游方式与普通消息的传递类似
- 然后下游的算子,比如 flatMap() 算子在 OneInputStreamTask.init() 时 createCheckpointedInputGate(…),创建 CheckpointedInputGate 时会 createCheckpointBarrierHandler(…),CheckpointBarrierHandler 根据 CheckpointingMode 决定是否对齐多个 Channels 的数据
- CheckpointedInputGate 在构造函数会执行
waitForPriorityEvents(...) async-> processPriorityEvents(...) -> pollNext() -> handleEvent(bufferOrEvent)会执行具体的事件处理,通过 BufferOrEvent 具体实现类类型执行相应的操作
private Optional<BufferOrEvent> handleEvent(BufferOrEvent bufferOrEvent) throws IOException {
Class<? extends AbstractEvent> eventClass = bufferOrEvent.getEvent().getClass();
if (eventClass == CheckpointBarrier.class) {
CheckpointBarrier checkpointBarrier = (CheckpointBarrier) bufferOrEvent.getEvent();
barrierHandler.processBarrier(checkpointBarrier, bufferOrEvent.getChannelInfo(), false);
} else if (eventClass == CancelCheckpointMarker.class) {
...
}
...
return Optional.of(bufferOrEvent);
}
Checkpoint barrier 在多条数据流之间对齐
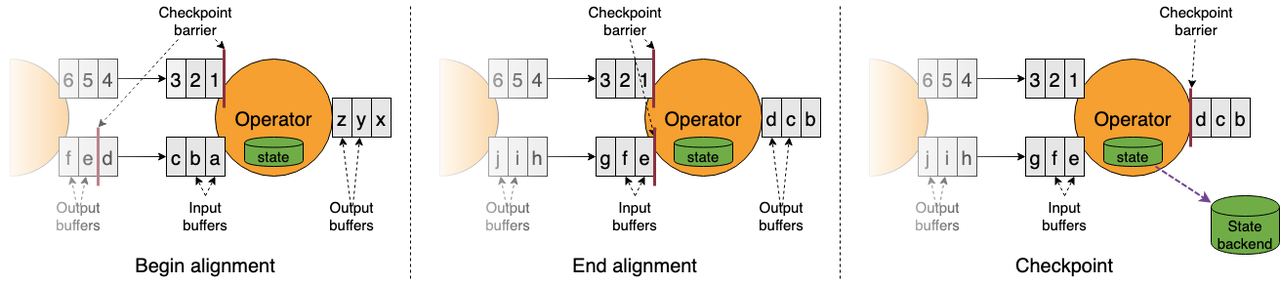
当 ExecutionGraph 物理执行图中的 subtask 算子实例接收到 barrier 的时候,subtask 会记录它的状态数据。如果 subtask 有 2 个上游(例如 KeyedProcessFunction、CoProcessFunction 等),subtask 会等待上游 2 个 barrier 对齐之后再进行 Checkpoint
Savepoints
Flink Savepoint 流程 RocksdbStateBackend 在触发 Savepoint 之后的主要流程,主要分为以下几个步骤
- 同步阶段 RocksDB 实例执行一次 Snapshot,获得一个 Snapshot 对象。
- 异步阶段
- 通过 CheckpointStreamFactory 拿到 CheckpointStateOutputStream 作为快照写出流
- 分别将快照的 Meta 信息和数据写到的输出流中(主要包括 version,keySerializer,state 数量,State serializer 等信息)
- 拿到输出流的句柄,然后开始遍历 Rocksdb 中的全量 KV 数据依次写入输出流中。 遍历 KV数据的时候对于每个 key group 依次写 state-id、k-v pair、END_OF_KEY_GROUP_MARK。写入格式如下所示: 暂时无法在飞书文档外展示此内容
- 将 RocksDB 的快照对象及一些辅助资源释放。
通过分析相关代码和火焰图可以看到,整个遍历 KV 的过程是单线程的,在遍历的过程非常耗时。 由于 Rocksdb 默认会将数据写入的时候压缩,因此在遍历 KV 的过程中需要将数据进行解压,导致 CPU 使用量也会增加。
综上所述,在大状态作业制作 Savepoint 面临以下几个问题:
- 单线程遍历慢导致制作失败,使得作业只能从其他的快照恢复。降低了作业的回滚和异常容错能力。
- 有些用户为了让 Savepoint 制作成功,会设置很长超时时间(30min~1h)。在这段过程中,如果作业发生 Failover ,任务需要回溯大量历史数据,对于用户来说不可接受。 目标 针对现有 快照制作的问题进行优化,实现以下目标:
- 优化算子制作 Savepoint 的流程,缩短 Savepoint 制作的耗时。
- 降低 Savepoint 期间作业 Failover 之后对任务的影响。 社区解决方案 Flip-193:Snapshot ownership 主要问题:当任务自动 Failover 的时候,如果最后一次成功的快照是 Savepoint ,就会从 Savepoint 去恢复。但是从 Savepoint 恢复会需要遍历全量的数据,所以耗时会非常高。此外,社区认为 Savepoint 的数据由用户去管理,所以有可能从 Savepoint 恢复的时候数据已经被用户删除。但是如果当前直接跳过 Savepoint ,从最新的 Checkpoint 去恢复(perfer-checkpoint-for-recovery),会打破 exactly once 的语义,对于一部分依赖两阶段提交的算子会造成重复提交。 解决思路:将 Savepoint 从 Checkpoint 的时间线中移除,当任务 Failover 的时候,从最新的 Checkpoint 恢复。具体来说有主要有以下几点
- Savepoint 的触发逻辑和 Checkpoint 一样
- Savepoint 成功之后不会去发送 “notifyCheckpointComplete()”
- Savepoint 成功之后也不会加入 CompletedCheckpoingStore 中
- Operator 在 savepoint 成功之后,不会去执行 Commit Flip-203:Incremental savepoints 主要问题:从 Savepoint 恢复速度慢,需要遍历数据,耗时较长。 解决思路:将 Savepoint 分为 native/canonical 两种类型。正常情况下使用 native 类型,只有 stop-with-savepoint 的时候才使用 canonical 类型。
- canonical 类型的 Savepoint 和当前一样,格式都是统一的 kv ,用于任务切换 StateBackend 和版本升级等
- native 类型的 Savepoint ,本质上和增量的 Checkpoint 一样。Savepoint 的由全量的 sst 文件组成,在制作的时候,只需要上传增量的 sst 文件,然后存量的文件通过 文件系统的 duplicated 接口拷贝到 Savepoint 目录中。这样可以节省数据遍历的资源消耗,加快制作和恢复的速度。 Savepoint vs Checkpoint
| Checkpoints | Savepoints | |
|---|---|---|
| 管理 | 完全由 Flink 系统管理 | 完全由用户管理 |
| 使用范围 | 一个 Checkpoint 只能被一个 Flink 任务管理和使用 | 每个 Savepoint 都是独立的,Savepoint 之间不会共享文件,文件是不可变的,可以被多个作业之间共用 |
| 生命周期 | 当 subsumed 的时候被清理掉 | 不会被 Flink 删掉 |
Task 制作 Savepoint 性能优化 方案一:并发制作 Savepoint 主要思路: 单并发遍历改为变多线程并发遍历 当前 Savepoint制作主要的耗时在单线程遍历全量 kv 数据。因此可以很自然的想到把单线程扩展为多线程,并发的去遍历 kv。因此,并发制作 Savepoint 的流程如下:
- 计算遍历的并发度, 支持设置遍历的最大并发度 maxParallelism ,默认为 4; 根据单 Task 状态大小计算出遍历的并发度 p = min( stateTotalSize / 5g , maxParallelism )
- 对状态进行分片 将 KeyGroup 按照遍历的并发度进行分片,切分完之后每个分片的 KeyGroup 仍然是连续的。
- 并发遍历 KV 并发的遍历每个分片的 KV ,然后并发的写入 HDFS ,最终每个分片会形成一个状态文件。 举个例子具体的例子: 下面这个 task 中包含 KeyGroup 1 ~ 100 的数据,我们可以将这个 Task 的 KeyGroup 分为3个部分,分别是 1 ~ 33, 34~66 , 67 ~100 ,然后并行的将每个 KeyGroup 的数据进行遍历。 暂时无法在飞书文档外展示此内容 每个分片进行遍历的时候,每个状态文件的格式和之前仍然保持一致。 暂时无法在飞书文档外展示此内容 优点:
- 兼容现有 Savepoint 格式,后续可以随意跨 StateBackend 恢复 缺点:
- 文件数量会变多
- 短时间资源消耗会更大 方案二:增量制作 Savepoint (Flip-203) 主要思路: 对于 Rocksdb StateBackend 来说, Savepoint 的制作方式和增量的Checkpoint 一样。不同的点在于制作 Savepoint 不再遍历数据,是直接上传全量的 sst 文件。 具体流程
- 制作 Savepoint 的时候,Rocksdb 执行一次 Native Checkpoint ,产生一些 sst 文件。
- 社区的方案是将 增量的文件上传 ,然后将存量的文件通过 存储系统 duplicate 的方式拷贝过去。但是目前字节 HDFS 没有类似于硬连接或者 Fast Copy 的功能,因此可以直接把文件都进行合并然后上传到 HDFS。
- 考虑到 SavePoint 的保存周期较长,为了控制 savepoint 总的文件个数,因此可以在制作 savepoint 的时候单独配置文件合并之后的个数。 暂时无法在飞书文档外展示此内容 优点:
- 速度快,资源消耗少。
- 后续如果使用支持硬件接的文件系统 (S3 copy_object\GCS_rewrite\OSS_copy_object)那么制作 savepoint 和 checkpoint 的耗时就几乎一样。 缺点:
- Savepoint 的格式仍然为 sst 文件,无法跨 Statebackend 恢复
- 如果 sst 文件损坏则状态无法恢复 方案三:读写分离 业界公司 阿里和快手都通过自研的 RemoteStateBackend 实现了读写分离。在这个基础上制作快照的过程可以和作业运行的流程完全解耦,对任务的运行不会产生影响。




