
参考
HBase 应用场景
- 推荐画像:特别是用户的画像,是一个比较大的稀疏矩阵,蚂蚁的风控就是构建在HBase之上
- 对象存储:我们知道不少的头条类、新闻类的的新闻、网页、图片存储在HBase之中,一些病毒公司的病毒库也是存储在HBase之中
- 时序数据:HBase之上有OpenTSDB模块,可以满足时序类场景的需求
- 时空数据:主要是轨迹、气象网格之类,滴滴打车的轨迹数据主要存在HBase之中,另外在技术所有大一点的数据量的车联网企业,数据都是存在HBase之中
- CubeDB OLAP:Kylin一个cube分析工具,底层的数据就是存储在HBase之中,不少客户自己基于离线计算构建cube存储在hbase之中,满足在线报表查询的需求
- 消息/订单:在电信领域、银行领域,不少的订单查询底层的存储,另外不少通信、消息同步的应用构建在HBase之上
- Feeds流:典型的应用就是xx朋友圈类似的应用
- NewSQL:之上有Phoenix的插件,可以满足二级索引、SQL的需求,对接传统数据需要SQL非事务的需求。
HMaster
HMaster 是 HBase 主/从集群架构中的中央节点。通常一个 HBase 集群存在多个 HMaster 节点,其中一个为 Active Master,其余为 Backup Master。
HBase 每时每刻只有一个 HMaster主服务器程序在运行,HMaster 将 Region 分配给 RegionServer,协调 RegionServer 的负载并维护集群的状态。HMaster 不会对外提供数据服务,而是由 RegionServer 负责所有 Regions 的读写请求及操作。
由于 HMaster 只维护表和 Region 的 metadata,而不参与数据的输入/输出过程,HMaster 失效仅仅会导致所有的元数据无法被修改,但表的数据读/写还是可以正常进行的。
HMaster的作用:
- 为 RegionServer 分配 Region
- 负责 RegionServer的负载均衡
- 发现失效的 RegionServer 并重新分配其上的 Region
- HDFS 上的垃圾文件回收
- 处理 Schema 更新请求
HRegionServer
HRegionServer作用:
- 维护 Master 分配给他的 Region,处理对这些 Region 的 IO 请求
- 负责切分正在运行过程中变的过大的 Region
可以看到,client 访问 HBase 上的数据并不需要 Master 参与(寻址访问 Zookeeper 和 RegionServer,数据读写访问 RegionServer),Master 仅仅维护 Table和Region的元数据信息(Table的元数据信息保存在 Zookeeper 上),负载很低。
注意:Master 上存放的元数据是Region的存储位置信息,但是在用户读写数据时,都是先写到 RegionServer 的 WAL 日志中,之后由 RegionServer 负责将其刷新到 HFile 中,即 Region 中。所以,用户并不直接接触 Region,无需知道 Region 的位置,所以其并不从 Master 处获得什么位置元数据,而只需要从 Zookeeper 中获取 RegionServer 的位置元数据,之后便直接和 RegionServer 通信。
HRegionServer 存取一个子表时,会创建一个 HRegion 对象,然后对表的每个列族创建一个 Store 实例,每个 Store 都会有一个 MemStore 和0个或多个 StoreFile 与之对应,每个StoreFile都会对应一个 HFile, HFile 就是实际的存储文件。因此,一个 HRegion 有多少个列族就有多少个 Store。
一个 HRegionServer 会有多个 HRegion 和一个 HLog。
当 HRegionServer 意外终止后,HMaster 会通过 Zookeeper感知到。
Region 详解
一张 HBase 表会纵向分为多个region,region是按大小分割的,每个表开始只有一个region,随着数据增多,region不断增大,当增大到一个阀值的时候,region就会等分会两个新的region,之后会有越来越多的region。region是 HBase 中分布式存储和负载均衡的最小单元,不同region分布到不同 RegionServer 上。
每个region按column family又可划分成多个store,一个column family对应一个store,而每个store中又会包含一个memstore和 n 个storefile,其中memstore在 RegionServer 的内存中,而storefile会持久化到 HDFS 上。
Zookeeper
Zookeeper 是 HBase 集群的”协调器”。由于 Zookeeper 的轻量级特性,因此我们可以将多个 HBase 集群共用一个 Zookeeper 集群,以节约大量的服务器。多个 HBase 集群共用 Zookeeper 集群的方法是使用同一组 ip,修改不同 HBase 集群的Zookeeper.znode.parent属性,让它们使用不同的根目录。比如 cluster1 使用/hbase-c1,cluster2 使用/hbase-c2,等等。
Zookeeper作用在于:
- HBase RegionServer 向 Zookeeper注册,提供 HBase RegionServer 状态信息(是否在线)。
- HMaster启动时候会将 HBase 系统表
-ROOT-加载到 Zookeeper,这样通过 Zookeeper 就可以获取当前系统表.META.的存储所对应的 RegionServer 信息。1.0+ 之后系统表变成了hbase:meta和hbase:namespace。
HBase DataModel
HBase 强一致性详解
HBase connection and connection pool
HBase 存储原理
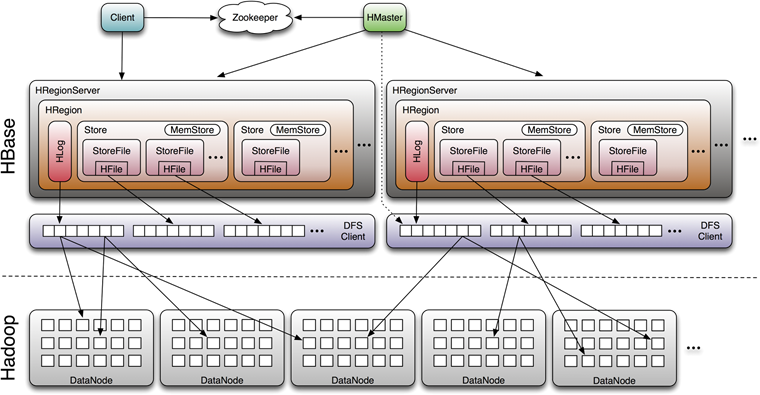
HBase 底层使用 LSM Tree 进行存储,HBase会将最近的修改写入Memstore,为了防止数据丢失,还会将WAL写入HLog。当Memstore的树大到一定程度的时候会flush到HRegion的磁盘中,一般是HDFS,MemStore写入磁盘就变成StoreFile,HRegionServer会定期对DataNode的数据做merge操作,彻底删除无效数据,多棵小树在这个时机合并成大树,来增强读性能。




