
划分 Stage
当某个 Action 操作触发计算,向 DAGScheduler 提交作业时,DAGScheduler 需要从 RDD 依赖链的末端出发,遍历整个 RDD 依赖链,划分 Stage,并且决定 Stage 之间的依赖关系。
Stage 划分是以 Shuffle 依赖为依据,当某个 RDD 运算需要将数据进行 Shuffle 时,这个包含了 Shuffle 依赖关系的 RDD 将被用来作为输入信息,构建一个新的 Stage,由此为依据划分 Stage,可以确保有依赖关系的数据能够按照正确的顺序得到处理和运算。
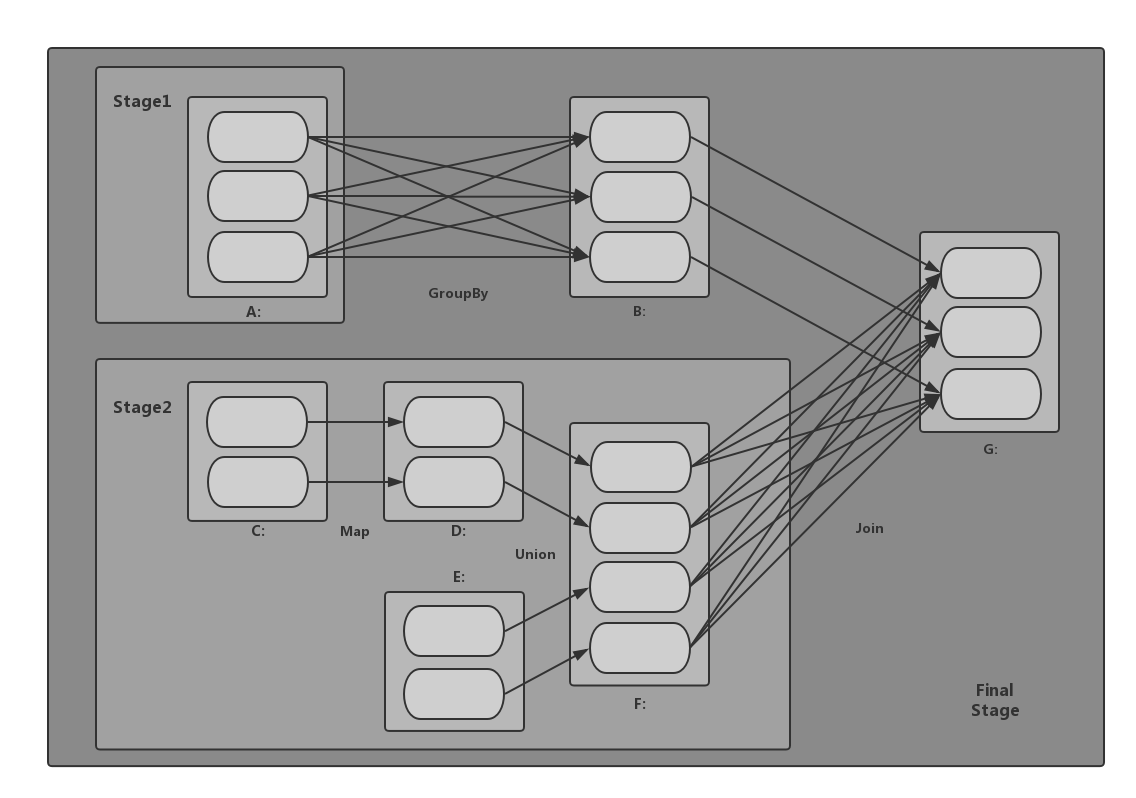
以GroupBy为例,该操作的结果实际上是一个ShuffleRDD(上图中的B),当DAGScheduler遍历到这个ShuffleRDD时,因为其依赖是一个ShuffleDependency,于是这个ShuffleRDD的父RDD以及ShuffleDependency等对象构建一个新的Stage,此Stage的输出结果的分区方式,是由ShuffleDependency中的Partitioner对象决定的。
其中ShuffleRDD本身的运算操作(其实就是一个获取Shuffle结果的过程),是在下一个Stage里进行的。
生成Job,提交Stage
划分Stage步骤得到一个或多个有依赖关系的Stage,其中,直接触发Job的RDD所关联的Stage作为finalStage生成一个Job实例,这两者的关系进一步存储在resultStageToJob映射表中,用在该Stage全部完成时做一些后续处理,如报告状态、清理Job相关数据等。
具体提交一个Stage时,首先判读该Stage所依赖的父Stage的结果是否可用,如果所有父Stage的结果都可用,则提交该Stage,如果有任何一个Stage不可用,则迭代尝试提交父Stage。所有迭代过程中由于所依赖Stage的结果不可用而没有提交成功的Stage都被放到waitingStages列表中等待将来被提交。
当一个属于中间过程Stage的任务(这种类型的任务所对应的类为ShuffleMapTask)完成以后,DAGScheduler会检查对应的Stage的所有任务是否都完成了,若完成,DAGScheduler会扫描waitingStages队列,检查他们是否还有任何依赖的Stage没有完成,如果没有就可以提交该Stage。此外,每当完成一次DAGScheduler的事件循环以后,也会触发一次从等待和失败列表中扫面并提交就绪Stage的调用过程。
任务集的提交
每个Stage的提交,最终是转换成一个TaskSet任务集的提交,DAGScheduler通过TaskScheduler接口提交TaskSet,这个TaskSet最终会触发TaskScheduler构建一个TaskManager的实例来管理这个TaskSet的生命周期,而对于DAGScheduler来说提交Stage的工作到此就完成了。而TaskScheduler的具体实现则会在得到计算资源时,进一步通过TaskSetManager调度具体的Task到对应的Executor节点上进行运算。
任务作业完成状态的监控
要保证相互依赖的Job/Stage能够顺利的调度执行,DAGScheduler就必然需要监控当前Job/Stage乃至Task的完成情况。这是通过对外(主要是对TaskScheduler)暴露一系列的回调函数来实现的,对于TaskScheduler来说,这些回调函数主要包括任务集的开始、结束、失败,任务集的失败,DAGScheduler根据这些Task的生命周期信息进一步维护Job和Stage的状态信息。
此外,TaskScheduler还可以通过回调函数通知DAGScheduler具体的Executor的生命状态,如果某一个Executor崩溃,或者由于任何原因与Driver失去联系,则对应Stage的ShuffleMapTask的输出结果也被标志位不可用,这将导致对应Stage状态的变更,进而影响相关Job的状态,再进一步可能触发对应Stage的重新提交来重新计算获取相关数据。
任务结果的获取
一个具体任务在Executor中执行完毕以后,其结果需要以某种形式返回给DAGScheduler,根据任务类型的不同,任务结果的返回方式也不同。FinalStage所对应的任务(对应的类为ResultTask)返回给DAGScheduler的是运算结果本身,而ShuffleMapTask返回给DAGScheduler的是一个MapStatus对象,这个对象管理了ShuffleMapTask的运算输出结果在BlockManager里的相关存储信息,而非结果本身。这些存储位置信息将作为下一个Stage任务获取输入数据的依据。而根据任务结果大小的不同,ResultTask返回的结果又分为两类,如果结果足够小,则直接放在DirectTaskResult对象内,如果超过特定尺寸(默认约为10M)则在Executor端会将DirectTaskResult先序列化,再把序列化的结果作为一个Block存放在BlockManager内,而后将BlockManager返回的BlockID放在IndirectTaskResult对象中返回给TaskScheduler,TaskScheduler进而调用TaskResultGetter将IndirectTaskResult中的BlockID取出并通过BlockManager最终取得对应的DirectTaskResult。当然从DAGScheduler的角度来说,这些过程对它来说是透明的,它所获得的都是任务的实际结果。




