
索引和搜索过程
索引过程
- 有一系列需要被索引的数据文件
- 被索引的数据文件经过语法分析和语言处理形成一系列词(Term)。
- 经过索引创建形成词典和倒排索引表。
- 通过索引存储将索引写入硬盘。
搜索过程
- 用户输入查询语句。
- 对查询语句经过语法分析和语言分析得到一系列词(Term)。
- 通过语法分析得到一个查询树。
- 通过索引存储将索引读入到内存。
- 利用查询树搜索索引,从而得到每个词(Term)的文档链表,对文档链表进行交,差,并得 到结果文档。
- 将搜索到的结果文档对查询的相关性进行排序。
- 返回查询结果给用户。
Lucene 的索引文件格式
- Lucene 的索引过程,就是按照全文检索的基本过程,将倒排表写成此文件格式的过程。
- Lucene 的搜索过程,就是按照此文件格式将索引进去的信息读出来,然后计算每篇文档打分(score)的过程。
Lucene 的索引结构是有层次结构的,主要分成以下层次
索引(Index)
- 在 Lucene 中一个索引是放在一个文件夹中的。
- 同一文件夹中的所有的文件(不同类型的文件)构成一个 Lucene 索引。
段(Segment)
- 一个 Index 可以包含多个 Segment,Segment 与 Segment 之间是独立的,添加新文档可以生成新的 Segment,不同的 Segment 可以合并。
- 如上图,具有相同前缀文件的属同一个 Segment,图中共两个段
_0和_1。 segments.gen和segments_5是段的元数据文件,也即它们保存了段的属性信息。
文档(Document)
- Document 是我们建 Index 的基本单位,不同的 Document 是保存在不同的 Segment 中的,一个 Segment 可以包含多篇 Document。
- 新添加的 Document 是单独保存在一个新生成的 Segment 中,随着 Segment 的合并,不同的 Document 会合并到同一个 Segment 中。
域(Field)
- 一篇 Document 包含不同类型的信息,可以分开索引,比如标题,时间,正文,作者等, 都可以保存在不同的 Field 里。
- 不同 Field 的索引方式可以不同,在真正解析域的存储的时候,我们会详细解读。
词(Term)
- Term 是索引的最小单位,是经过词法分析和语言处理后的字符串。
Lucene 的索引文件具体格式
Lucene 的索引结构中,即保存了正向信息,也保存了反向信息,还有其他一些 Lucene 特有的其他信息。
正向信息
正向信息按层次保存了从索引,一直到词的包含关系: Index –> Segment(segments.gen, segments_N) -> Document -> Field(fnm, fdx, fd) -> Term(tvx, tvd, tvf),即此索引包含了那些段,每个段包含了那些文档,每个文档包含了那些域,每个域包了那些词。
包含正向信息的文件有:
segments_N保存了此索引包含多少个 Segment,每个 Segment 包含多少篇 Document。*.fnm保存了此段包含了多少个 Field,每个 Field 的名称及索引方式。 **.fdx,*.fdt保存了此 Segment 包含含的所有 Document ,每篇 Document 包含了多少 Field,每个 Field 保存了哪些信息。*.tvx,*.tvd,*.tvf保存了此 Segment 包含含多少 Document,每篇 Document 包含了多少 Field,每个 Field 包含了多少 Term,每个 Term 的字符串,位置等信息。
段的元数据信息(segments_N)
一个索引(Index)可以同时存在多个segments_N,当要打开一个索引,就需要按照策略(N最大)选择一个segments_N打开
Format: 索引文件格式的版本号,由于 Lucene 是在不断开发过程中的,因而不同版本的 Lucene,其索引文件格式也不尽相同,于是规定一个版本号。。Version: 索引的版本号,记录了 IndexWriter 将修改提交到索引文件中的次数。NameCount: 是下一个新段(Segment)的段名。所有属于同一个段的索引文件都以段名作为文件名,一般为_0.xxx, _0.yyy, _1.xxx, _1.yyy ...新生成的段的段名一般为原有最大段名加一。NameCount读出来是 2,说明新的段为_2.xxx, _2.yyySegCount: 段(Segment)的个数。SegCount 个段的元数据信息: 每个段的元数据信息又包含以下结构SegName: 段名,SegSize: 此段中包含的文档数,然而此文档数是包括已经删除,又没有optimize的文档的,因为在optimize之前,Lucene的段中包含了所有被索引过的文档,而被删除的文档是保存在.del文件中的,在搜索的过程中,是先从段中读到了被删除的文档,然后再用.del中的标志,将这篇文档过滤掉。DelGen:.del文件的版本号,在optimize之前,删除的文档是保存在.del文件中的。每当 IndexWriter 向索引文件中提交删除操作的时候,DelGen加 1,并生成新的.del文件。DocStoreOffset: 对于域(Stored Field)和词向量(Term Vector)的存储可以有不同的方式,即可以每 个段(Segment)单独存储自己的域和词向量信息,也可以多个段共享域和词向 量,把它们存储到一个段中去。如果 DocStoreOffset 为-1,则此段单独存储自己的域和词向量,从存储文件上 来看,如果此段段名为 XXX,则此段有自己的 XXX.fdt,XXX.fdx,XXX.tvf,XXX.tvd, XXX.tvx 文件。DocStoreSegment 和 DocStoreIsCompoundFile 在此处不被保存。如果 DocStoreOffset 不为-1,则 DocStoreSegment 保存了共享的段的名字,比 如为 YYY,DocStoreOffset 则为此段的域及词向量信息在共享段中的偏移量。 则此段没有自己的 XXX.fdt,XXX.fdx,XXX.tvf,XXX.tvd,XXX.tvx 文件,而是将 信息存放在共享段的 YYY.fdt,YYY.fdx,YYY.tvf,YYY.tvd,YYY.tvx 文件中。DocStoreSegment: 共享域和词向量存储并不是经常被使用到,实现也或有缺陷。DocStoreIsCompoundFile:HasSingleNormFile:在搜索的过程中,标准化因子(Normalization Factor)会影响文档最后的评分。不同的文档重要性不同,不同的域重要性也不同。因而每个文档的每个域都可以有自己的标准化因子。如果 HasSingleNormFile 为 1,则所有的标准化因子都是存在.nrm 文件中的。如果 HasSingleNormFile 不是 1,则每个域都有自己的标准化因子文件.fNNumField: 域的数量NormGen: 如果每个域有自己的标准化因子文件,则此数组描述了每个标准化因子文件的版本号,也即.fN 的 N。IsCompoundFile: 是否保存为复合文件,也即把同一个段中的文件按照一定格式,保存在一个文件当中,这样可以减少每次打开文件的个数。DeletionCount: 记录了此段中删除的文档的数目。HasProx: 如果至少有一个段 omitTf 为 false,也即词频(term freqency)需要被保存,则 HasProx 为 1,否则为 0。Diagnostics: 调试信息。
User map data: 保存了用户从字符串到字符串的映射 Map<String,String>CheckSum: 此文件 segment_N 的校验和。
域(Field)的元数据信息(.fnm)
一个段(Segment)包含多个域,每个域都有一些元数据信息,保存在.fnm 文件中,.fnm 文件 的格式如下:
FNMVersion: 是 fnm 文件的版本号,对于 Lucene 2.9 为-2FieldsCount: 域的数目一个数组的域(Fields):FieldName: 域名,如”title”,”modified”,”content”等。FieldBits: 一系列标志位,表明对此域的索引方式,8 bits,2 bits 保留最低位: 1 表示此域被索引,0 则不被索引。所谓被索引,也即放到倒排表中去。倒数第二位: 1 表示保存词向量,0 为不保存词向量。倒数第三位: 1 表示在词向量中保存位置信息。倒数第四位: 1 表示在词向量中保存位置信息。倒数第五位: 1 表示不保存标准化因子倒数第六位: 是否保存 payload
要了解域的元数据信息,还要了解以下几点:
- 位置(Position)和偏移量(Offset)的区别: 位置是基于词 Term 的,偏移量是基于字母或汉字的。
- 索引域(Indexed)和存储域(Stored)的区别: 一个域为什么会被存储(store)而不被索引(Index)呢?在一个文档中的所有信息中,有这样一部分信息,可能不想被索引从而可以搜索到,但是当这个文档由于其他的信息被搜索到时,可以同其他信息一同返回。
- payload 的使用: 我们知道,索引是以倒排表形式存储的,对于每一个词,都保存了包含这个词的一个链表,当然为了加快查询速度,此链表多用跳跃表进行存储。Payload 信息就是存储在倒排表中的,同文档号一起存放,多用于存储与每篇文档 相关的一些信息。当然这部分信息也可以存储域里(stored Field),两者从功能上基本是一样的,然而当要存储的信息很多的时候,存放在倒排表里,利用跳跃表,有利于大大提高搜索速度。
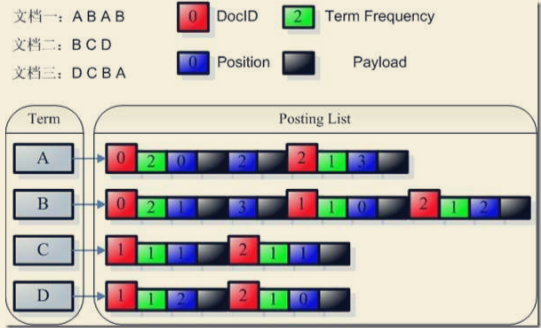
Payload 主要有以下几种用法:
- 存储每个文档都有的信息:比如有的时候,我们想给每个文档赋一个我们自己的文档号,而不是用 Lucene 自己的文档号。于是我们可以声明一个特殊的域 (Field)”_ID”和特殊的词(Term)”_ID”,使得每篇文档都包词”_ID”,于是在词”_ID”的倒排表里面对于每篇文档又有一项,每一项都有一个 payload,于是我 们可以在 payload 里面保存我们自己的文档号。每当我们得到一个 Lucene 的 文档号的时候,就能从跳跃表中查找到我们自己的文档号。
- 影响词的评分
域(Field)的数据信息(.fdt,.fdx)
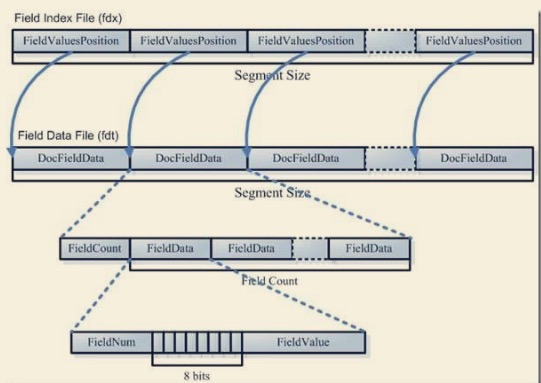
- 域数据文件(fdt):
- 真正保存存储域(stored field)信息的是 fdt 文件
- 在一个段(segment)中总共有 segment size 篇文档,所以 fdt 文件中共有 segment size 个项,每一项保存一篇文档的域的信息
- 对于每一篇文档,一开始是一个 fieldcount,也即此文档包的域的数目,接下来是 fieldcount 个项,每一项保存一个域的信息。
- 对于每一个域,fieldnum 是域号,接着是一个 8 位的 byte,最低一位表示此域是否分词(tokenized),倒数第二位表示此域是保存字符串数据还是二进制数据,倒数第 三位表示此域是否被压缩,再接下来就是存储域的值,比如 new Field(“title”, “lucene in action”, Field.Store.Yes, …),则此处存放的就是”lucene in action”这个字符串。
- 域索引文件(fdx):
- 由域数据文件格式我们知道,每篇文档包的域的个数,每个存储域的值都是不一样的,因而域数据文件中 segment size 篇文档,每篇文档占用的大小也是不一样的, 那么如何在 fdt 中辨每一篇文档的起始地址和终止地址呢,如何能够更快的找到 第 n 篇文档的存储域的信息呢?就是要借助域索引文件。
词向量(TermVector)的数据信息(.tvx,.tvd,.tvf)
- 由域数据文件格式我们知道,每篇文档包的域的个数,每个存储域的值都是不一样的,因而域数据文件中 segment size 篇文档,每篇文档占用的大小也是不一样的, 那么如何在 fdt 中辨每一篇文档的起始地址和终止地址呢,如何能够更快的找到 第 n 篇文档的存储域的信息呢?就是要借助域索引文件。
反向信息
反向信息保存了词典到倒排表的映射: 词(Term)–>文档(Document)
包含反向信息的文件有:
*.tis,*.tii保存了词典(Term Dictionary),也即此段包含的所有的词按字典顺序的排序。*.frq保存了倒排表,也即包含每个 Term 的 DocumentID 列表。*.prx保存了倒排表中每个 Term 在包含此 Term 的 Document 中的位置。
词典(tis)及词典索引(tii)信息
文档号及词频(frq)信息
词位置(prx)信息
其他信息
标准化因子文件(nrm)
删除文档文件(del)
NRT
Nearly Real Time 实现




