
原理
FileBeat 由两个重要的组件构成,inputs和harvesters,这两个组件从尾部读取数据,然后将数据发送到指定的outputs
harvesters
harvesters负责逐行读取单个文件的内容,并将读取的数据发送到output。每个文件都会启动一个harvesters,并由harvesters负责打开和关闭文件。由于文件描述符在harvesters运行时会一直保持在打开状态,因此,如果文件在被收集时被删除或者重命名,FileBeat 仍然会读取该文件,即在harvesters被关闭之前,磁盘上的空间仍然被harvesters占用着。默认情况下,FileBeat 会保持文件处于打开状态,直到达到close_inactive。
- 如果文件在被
harvesters读取文件时删除,关闭文件处理程序才会释放底层资源。 - 关闭
harvesters后,只有在scan_frequency(指定扫描目录中文件的频率,details)结束后才会再次启动文件的收集。 - 如果在
harvesters关闭时移动或移除文件,则不会继续收集文件。
使用close_ *配置选项控制harvesters何时关闭。
inputs
input负责管理harvesters并查找所有要读取的源。
例如输入类型时log,则input会查找磁盘上所有能匹配上的文件,并为每个文件启动harvester。
FileBeat 目前支持多种输入类型。每种输入类型都可以定义多次。日志输入检查每个文件以查看是否需要启动收集器,是否已经运行,或者是否可以忽略该文件(参考ignore_older)。如果自harvesters关闭后文件的大小发生变化,则只会收集新行。
FileBeat 会保存每个文件的状态,并经常将状态刷新到磁盘中的注册表文件。状态用于记住harvester正在读取的最后一个偏移量并确保发送所有日志行。如果无法访问output(Elasticsearch/Logstash),FileBeat 会跟踪发送的最后一行,并在output再次可用时继续读取文件。在 FileBeat 运行时,状态信息也会保存在内存中。重新启动 FileBeat 时,会读取注册表文件的数据来重建状态,FileBeat 会在最后一个已知位置继续运行每个收集器。
对于每个input,FileBeat 保存它找到的每个文件的状态。由于可以重命名或移动文件,因此文件名和路径不足以标识文件。对于每个文件,FileBeat 存储唯一标识符以检测先前是否读取过文件。
FileBeat 保证事件将至少一次(At least once)传递到配置的output,并且不会丢失数据。 FileBeat 能够实现此行为,因为它将每个事件的传递状态存储在注册表文件中。在已定义的output被阻止且尚未确认所有事件的情况下,FileBeat 将继续尝试发送事件,直到output确认已收到事件。如果 FileBeat 在发送事件的过程中关闭,它不会等待output确认所有事件。重新启动 FileBeat 时,将再次发送所有已经发送到output但在 FileBeat 关闭之前未确认的事件,确保每个事件至少发送一次,但最终可能会将重复事件发送到输出。可以通过设置shutdown_timeout将 FileBeat 配置为在关闭之前等待特定时间。
Note: 涉及日志轮换和旧文件的删除时,FileBeat 的至少一次交付保证有一个限制。如果日志文件写入磁盘的速度超过 FileBeat 可以处理的速度,或者在
output不可用时删除文件,数据有可能会丢失。在 Linux 上,FileBeat 也可能因为 inode 重用而跳过行。
安装
注意安装换对应平台的 FileBeat,以防出现can not exec bianary file的异常
启动
# 运行 FileBeats
# -e 日志输出到 stderr 并禁用 syslog/file 输出
# -c 指定配置文件
# -d 启用对指定选择器的调试,publish 可以看到完整的 event 信息
sudo nohup filebeat -e -c filebeat.yml -d "publish" >filebeat.log 2>&1 &
# FileBeat 会在注册表中存储每个文件收集的状态,
# 想强制 FileBeat 从日志的最开始重新读取,可以直接删除注册表文件
sudo rm data/registry
# deb/rpm 安装路径
sudo rm /var/lib/filebeat/registry
# 查看 filebeat 运行日志,发送的事件格式
tail -100f /var/log/filebeat/filebeat
配置文件格式
filebeat.yml 各配置项详细介绍
Filter and enhance the exported data
由 filebeat 导出的数据,你可能希望过滤掉一些数据并增强一些数据(比如添加一些额外的 metadata)。filebeat提供了一系列的工具来做这些事。
下面简单介绍一些方法,详细的可以参考Filter and enhance the exported data
Processors
在将 event 发送到 output 之前,你可以在配置文件中define processors去处理 event。processor 可以完成下面的任务:
- 减少导出的字段
- 添加其他的 metadata
- 执行额外的处理和解码
每个 processor 会接收一个 event,将一些定义好的行为应用到 event,然后返回 event,如果你在配置文件中定义了一系列 processors,那么他会按定义的顺序依次执行。
Add Kubernetes metadata
除了自己定义 processor 之外,filebeat 还提供了一些已经定义好的 processor,例如 add_kubernetes_metadata processor
add_kubernetes_metadata processor 根据 event 源自哪一个 kubernetes pod,使用相关 metadata 为每个 event 添加 annotations,包括:
- Pod Name
- Pod UID
- Namespace
- Labels
add_kubernetes_metadataprocessor 有两个基本构建块。Indexers和Matchers。
Indexers 接收pod元数据并根据pod元数据构建索引。例如:ip_portindexer可以使用kubernetes pod并根据所有pod_ip:container_port组合、索引元数据。
Matchers 用于构造查询索引的查找键。例如:当字段匹配器将["metricset.host"]作为查找字段时,它将用字段metricset.host的值构造一个查找键。
每个 Beat 都可以定义自己的默认Indexers和Matchers,新定义的Indexers和Matchers默认是开启的。例如启用containerindexer,它会根据所有containerID索引pod元数据,以及logs_pathmatcher,它接收source filed,提取container ID,并使用它来检索元数据。
让 filebeat 作为 Kubernetes 中的 pod运行:
processors:
- add_kubernetes_metadata:
in_cluster: true
让 filebeat 作为 Kubernetes Node 上的进程运行:
processors:
- add_kubernetes_metadata:
in_cluster: false
host: <hostname>
kube_config: ${HOME}/.kube/config
禁用默认的Indexers和Matchers,并启用感兴趣的Indexers和Matchers。
processors:
- add_kubernetes_metadata:
in_cluster: false
host: <hostname>
kube_config: ~/.kube/config
default_indexers.enabled: false
default_matchers.enabled: false
indexers:
- ip_port:
matchers:
- fields:
lookup_fields: ["metricset.host"]
举个栗子:
- add_kubernetes_metadata:
in_cluster: true
include_labels:
- app
- k8s-app
- k8s-ns
include_annotations:
- k8s.cloud/controller-kind
matchers:
- logs_path:
logs_path: /var/log/containers
输出结果
{
"@timestamp": "2018-07-23T07:18:59.712Z",
"@metadata": {
"beat": "filebeat",
"type": "doc",
"version": "6.3.0"
},
"source": "/var/log/containers/infra-wayne-7b6786958f-tcsxk_default_wayne-a5113b31cd75d50fc93ae48ecf7c790e100c91f5fbe12850e465dd2de3d2282c.log",
"offset": 74902,
"log": "\u001b[0m\n",
"stream": "stdout",
"type": "k8s-log",
"cluster": "shbt",
"hostname": "docker4081",
"prospector": {
"type": "log"
},
"input": {
"type": "log"
},
"kubernetes": {
"container": {
"name": "wayne"
},
"pod": {
"name": "infra-wayne-7b6786958f-tcsxk"
},
"node": {
"name": "docker4081"
},
"namespace": "default",
"labels": {
"k8s-app": "infra",
"k8s-ns": "infra",
"app": "infra-wayne"
},
"annotations": {
"k8s": {
"cloud/controller-kind": "deployment"
}
}
},
"host": {
"name": "kube-filebeat-wn2w6"
},
"time": "2018-07-23T07:18:58.099250606Z"
}
其中k8s.cloud/controller-kind是在Pod Template 的 annotation中添加的。
这样我们可以得到以下信息,PodName、ContainerName、AppName、Namespace和ControllerKind,以便于日志分析。
更加详细的内容可以参考add kubernetes metadata
Manage Multiline Message
FileBeat 默认是一行一行的处理日志的,但是对于类似 Java 异常栈这种多行的 message 怎么处理呢?这就需要配置filebeat.yml中的multiline去指出哪些行是属于同一事件。
Note: Logstash 中使用 Logstash multiline codec 实现多行事件处理可能会导致流和损坏数据的混合。因此尽量在事件数据发送到 Logstash 之前先处理多行事件。
multiline.pattern: 正则表达式,用于匹配行multiline.negate:true或false,匹配或不匹配,默认是 false。multiline.match:before或者after。
例如:
# 将匹配的行添加到不匹配的行后面,例如:
# a
# b
# b
multiline.pattern: ^b
multiline.negate: false
multiline.match: after
# 将匹配的行添加到不匹配的行前面,例如:
# b
# b
# a
multiline.pattern: ^b
multiline.negate: false
multiline.match: before
# 将不匹配的行添加到匹配的行后面,例如:
# b
# a
# a
multiline.pattern: ^b
multiline.negate: true
multiline.match: after
# 将不匹配的行添加到匹配的行前面,例如:
# a
# a
# b
multiline.pattern: ^b
multiline.negate: true
multiline.match: before
Filebeat input - docker
注意 Filebeat 6.3+ 才有这个插件,并且这个插件目前只是实验性的,未来可能会完全更改或者删除,酌情使用。reference
filebeat.inputs:
- type: docker
containers.ids:
- '28b843cc25a683a4add4d911127d1aaa3326d9620c49f838ac03dfa477af14de'
注意containers.ids必须是完全的id,而docker ps命令显示的container.id是省略的id。因为这个插件会默认读取${containers.path}/${containers.ids}/*.log
less /var/log/filebeat/filebeat
:/Configured paths
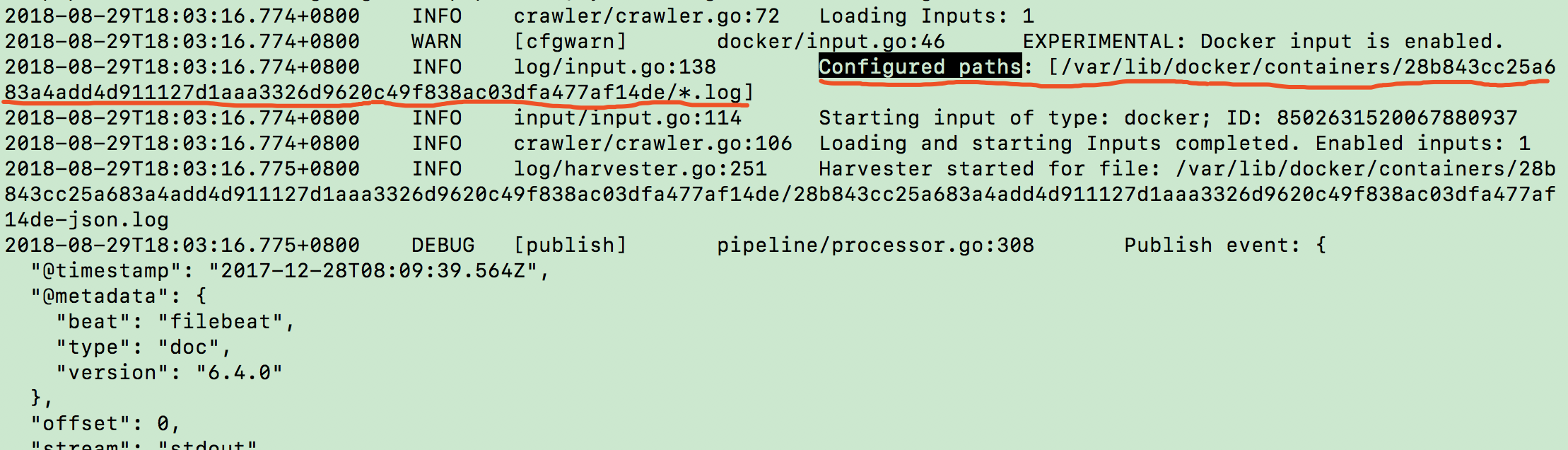
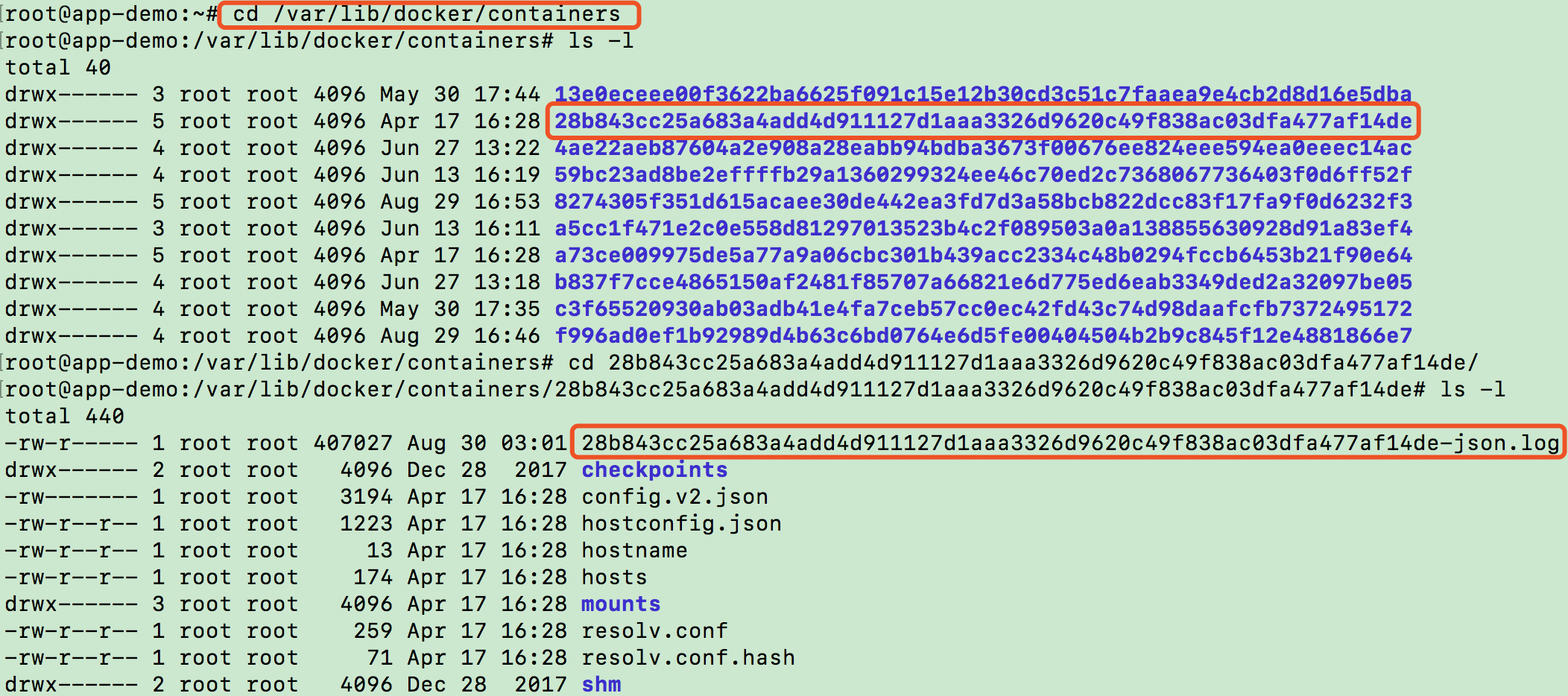
containers.path默认为/var/lib/docker/containers,即 docker 默认镜像存储的位置。让我们进目录看一下
了解了原理之后,docker 插件同样的可以使用 log 插件实现,方式如下:
filebeat.prospectors:
- type: log
paths:
- '/var/lib/docker/containers/*/*.log'
json.message_key: log
json.keys_under_root: true
processors:
- add_docker_metadata: ~
Filebeat output - logstash
如果要使用 Logstash 对 FileBeat 收集的数据执行其他处理,首先需要配置filebeat.yml中的output.logstash,并注释掉output.elasticsearch。
vim /etc/FileBeat/filebeat.yml
FileBeat.prospectors:
- type: log
paths:
- /var/lib/logstash-tutorial.log
output.logstash:
hosts: ["hostname:5044"]
# 注意需要将 output.elasticsearch 注释掉
发送到 Logstash 的每个事件都包含一些元数据字段(metadata),这样就可以在 Logstash 中使用这些字段进行索引或者过滤。
除了元数据字段之外,如果还想添加额外的自定义的信息给output,可以使用fields,这样output就可以更方便的通过字段过滤或者区分日志。字段可以是标量值,数组,字典或这些的任何嵌套组合。 默认情况下,在此处指定的字段会被分组到output文档中fields的下一级。 要将自定义字段存储为顶级字段,需要将fields_under_root选项设置为true。 如果在常规配置中声明了重复字段,此处声明的值优先级更高。
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/hadoop-yarn/hadoop-cmf-yarn-NODEMANAGER-cdh1.log.out
fields:
topic_id: yarn_log
- type: log
enabled: true
paths:
- /var/log/spark2/spark2-history-server-cdh1.log
fields:
topic_id: spark_log
output.logstash:
hosts: ["cdh3:5044"]
FileBeat 发送给output的事件如下:
...
2018-08-23T11:23:25.014+0800 DEBUG [publish] pipeline/processor.go:275 Publish event: {
"@timestamp": "2018-08-23T03:23:25.014Z",
"@metadata": {
"beat": "filebeat",
"type": "doc",
"version": "6.2.3"
},
"beat": {
"name": "cdh1",
"hostname": "cdh1",
"version": "6.2.3"
},
"source": "/var/log/hadoop-yarn/hadoop-cmf-yarn-NODEMANAGER-cdh1.log.out",
"offset": 15771466,
"message": "2018-05-31 13:13:25,414 INFO org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService: org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService waiting for pending aggregation during exit",
"prospector": {
"type": "log"
},
"fields": {
"topic_id": "yarn_log"
}
}
...
Running Filebeat on Kubernetes
$ curl -L -O https://raw.githubusercontent.com/elastic/beats/6.4/deploy/kubernetes/filebeat-kubernetes.yaml
内容如下:
# 有些注释是我额外添加的,原始文件是没有的
---
# 定义一个`name=filebeat-config`的configMap,用于指定 filebeat output
apiVersion: v1
kind: ConfigMap
# 标准 object 的元数据
metadata:
name: filebeat-config
namespace: kube-system
labels:
k8s-app: filebeat
data:
filebeat.yml: |-
filebeat.config:
inputs:
# Mounted `filebeat-inputs` configmap:
path: ${path.config}/inputs.d/*.yml
# Reload inputs configs as they change:
reload.enabled: false
modules:
path: ${path.config}/modules.d/*.yml
# Reload module configs as they change:
reload.enabled: false
# To enable hints based autodiscover, remove `filebeat.config.inputs` configuration and uncomment this:
#filebeat.autodiscover:
# providers:
# - type: kubernetes
# hints.enabled: true
processors:
- add_cloud_metadata:
cloud.id: ${ELASTIC_CLOUD_ID}
cloud.auth: ${ELASTIC_CLOUD_AUTH}
output.elasticsearch:
hosts: ['${ELASTICSEARCH_HOST:elasticsearch}:${ELASTICSEARCH_PORT:9200}']
username: ${ELASTICSEARCH_USERNAME}
password: ${ELASTICSEARCH_PASSWORD}
---
# 定义一个`name=filebeat-inputs`的configMap,用于指定 filebeat input
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-inputs
namespace: kube-system
labels:
k8s-app: filebeat
data:
kubernetes.yml: |-
- type: docker
containers.ids:
- "*"
processors:
# 为每个 event 添加来自哪个 pod 的注解
- add_kubernetes_metadata:
# true: filebeat 将运行在 pod 中,否则以进程方式运行在节点上
in_cluster: true
---
# 将 filebeat 配置为 DaemonSet
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: filebeat
namespace: kube-system
labels:
k8s-app: filebeat
# DaemonSetSpec
spec:
template:
metadata:
labels:
k8s-app: filebeat
# PodSpec
spec:
# 指定运行在当前 pod 的 Service Account
serviceAccountName: filebeat
# 优雅的终止pod所需要的时间,单位秒(0表示立即删除,nil表示使用默认宽限期)
# 宽限期是向pod中运行的进程发送终止信号到进程被终止的时间。
# 需要设置此值的时间大于你的进程的预期清理时间。默认为30秒
terminationGracePeriodSeconds: 30
# 配置运行在pod中的container
containers:
- name: filebeat
image: docker.elastic.co/beats/filebeat:6.4.0
# 向入口点传送的参数,如果没有设置则使用docker images 的 CMD
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
# 配置环境变量,在其他配置里面可以通过 ${VAR} 获取到
env:
- name: ELASTICSEARCH_HOST
value: elasticsearch
- name: ELASTICSEARCH_PORT
value: "9200"
- name: ELASTICSEARCH_USERNAME
value: elastic
- name: ELASTICSEARCH_PASSWORD
value: changeme
- name: ELASTIC_CLOUD_ID
value:
- name: ELASTIC_CLOUD_AUTH
value:
# securityContext定义Pod或Container的权限和访问控制设置
securityContext:
# UID 用于运行容器进程的入口点。
# 如果没有指定,默认为镜像指定的用户。如果`SecurityContext`和
# `PodSecurityContext`都指定了,以`SecurityContext`为准
runAsUser: 0
# 分配容器所需的资源
resources:
# 设置允许的最大资源
limits:
# 内存: 可以使用的单位E、P、T、G、M、K,另外 Mi 和 M 的含义相同
memory: 200Mi
# 设置所需的最小资源,如果省略该配置项则默认为 limits
requests:
# 转换为 millicore 值并乘以100。
# 容器每100毫秒可以使用的cpu时间总量。
cpu: 100m
memory: 100Mi
# 把 volume mount 到 container 的 filesystem
volumeMounts:
# 将 name=`config` 的 volume mount 到 container 的 /etc/filebeat.yml,并设为只读
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
# 应安装容器卷的卷内路径,默认为""(卷的根路径)
subPath: filebeat.yml
- name: inputs
mountPath: /usr/share/filebeat/inputs.d
readOnly: true
- name: data
mountPath: /usr/share/filebeat/data
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
# 属于该 pod 的容器可以 mount 的 volume 列表
volumes:
# 给 volume 取个名字
- name: config
# 引用一个 configMap object 填充 volume
configMap:
# 设置创建文件时默认的文件读写权限
# 必须是0~0777之间的值。默认为 0644
defaultMode: 0600
# 要引用的 configMap object 的 name
name: filebeat-config
- name: varlibdockercontainers
# 宿主机直接暴露给 container 的预先存在的文件或目录。
hostPath:
# 宿主机上的路径,如果是链接文件,它会找到真实的文件路径。
path: /var/lib/docker/containers
- name: inputs
configMap:
defaultMode: 0600
name: filebeat-inputs
# data folder stores a registry of read status for all files, so we don't send everything again on a Filebeat pod restart
- name: data
hostPath:
path: /var/lib/filebeat-data
# 默认为"",在 mount hostPath volume 之前不会执行任何检查
# DirectoryOrCreate 代表如果给定路径中不存在,则会根据需要创建一个空目录(0755),
# 并与 Kubelet 具有相同的组和所有权
# 其他的 type 参考:https://kubernetes.io/docs/concepts/storage/volumes/#hostpath
type: DirectoryOrCreate
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: filebeat
# 主题包含对该角色适用的对象的引用
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
# 只能引用全局 namespace 中的 clusterRole。如果无法解析 roleRef,则 Authorizer 一定会返回错误。
roleRef:
kind: ClusterRole
name: filebeat
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: filebeat
labels:
k8s-app: filebeat
# 此 ClusterRole 的所有策略规则
rules:
# 包含 resources 的 apiGroup 的名字,如果指定了多个 apiGroup,
# 那么对于任何一个 apiGroup 资源请求的任何操作都会允许
# "" indicates the core API group
- apiGroups: [""]
# 此 rule 适用的资源列表,`ResourceAll`代表所有资源
resources:
- namespaces
- pods
# 此 rule 适用的所有资源类型和属性限制的动词列表,`VerbAll`代表所有动词
verbs:
- get
- watch
- list
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat
namespace: kube-system
labels:
k8s-app: filebeat
---
Auto discover
当应用程序运行在容器中,对于监控系统来说,他们就变成了移动的目标。auto discover 提供 track 功能,并在发生变化时调整设置。official reference
在filebeat.yml的filebeat.autodiscover部分定义一些providers来启用 auto discover。当运行 filebeat 时,auto discover 子系统就会开始监听服务。
Providers
auto discover providers 会观察系统上的 event,并将这些 event 转换为具有通用格式的内部 auto discover event,这样在配置 provider template 的时候就可以获取 auto discover event 中的某些字段的值,当满足条件时就启用某些特定的配置(比如获取 docker.container.name = “my_redis” 的日志)。
一开始,filebeat 会扫描所有现有容器并为他们启动合适的配置,然后它会持续观察新的容器的开始/停止事件。
Docker auto discover
Docker auto discover provider 会监视 docker containers 的开始和结束 event,然后转换成 auto discover event,每个 auto discover event 的可用字段如下。
- host
- port
- docker.container.id
- docker.container.image
- docker.container.name
- docker.container.labels
例如一个具体的 docker auto discover event 如下
{
"data": {
"host": "10.4.15.9",
"port": 6379,
"docker": {
"container": {
"id": "382184ecdb385cfd5d1f1a65f78911054c8511ae009635300ac28b4fc357ce51",
"name": "redis",
"image": "redis:3.2.11",
"labels": {
"io.kubernetes.pod.namespace": "default",
...
}
}
}
}
}
在 providers 中可以定义一组配置模版,以便在条件与事件匹配的时候应用。模版用于定义与 auto discover event 匹配的条件,以及当条件匹配成功时要执行的配置列表。
在配置模版中使用 auto discover event 的内容,可以通过data命名空间获取。如访问host字段信息:${data.host}会得到结果10.4.15.9。
下面举一个实际的例子,收集docker.container.image包含redis的所有 containers 的 docker logs
filebeat 支持inputs(默认)和modules的templates。
filebeat.autodiscover:
providers:
- type: docker
templates:
# 匹配条件
- condition:
contains:
docker.container.image: redis
# 条件匹配成功时要执行的配置列表
config:
- type: docker
containers.ids:
- "${data.docker.container.id}"
exclude_lines: ["^\\s+[\\-`('.|_]"] # drop asciiart lines
如果使用modules,可以使用docker input重写default input
filebeat.autodiscover:
providers:
- type: docker
templates:
- condition:
contains:
docker.container.image: redis
config:
- module: redis
log:
input:
type: docker
containers.ids:
- "${data.docker.container.id}"
Note:在读取多个容器的日志的时候需要注意,例如想读取/mnt/logs/<container_id>/*.log,下面的写法就会出现问题,它会多次重复(每个nginx container一次)读取路径下的日志
autodiscover.providers: - type: docker templates: - condition.contains: docker.container.image: nginx config: - type: log paths: - "/mnt/logs/*/*.log"
正确的写法
autodiscover.providers: - type: docker templates: - condition.contains: docker.container.image: nginx config: - type: log paths: - "/mnt/logs/${data.docker.container.id}/*.log"
对于多条件的条件匹配
filebeat.autodiscover:
providers:
- type: docker
templates:
# 多条件匹配(且), and 需要接收一个 list
- condition.and:
- contains:
docker.container.image: "**SOMETHING**"
- not.contains:
docker.container.image: "**SOMETHING_ELSE**"
# 条件匹配成功时要执行的配置列表
config:
- type: docker
containers.ids:
- "${data.docker.container.id}"
exclude_lines: ["^\\s+[\\-`('.|_]"] # drop asciiart lines
Kubernetes auto discover
Kubernetes auto discover provider 会监视 kubernetes pods 的开始、更新和结束事件,并转换成标准的 auto discover event,每个 auto discover event 的可用字段如下
- host
- port
- kubernetes.container.id
- kubernetes.container.image
- kubernetes.container.name
- kubernetes.labels
- kubernetes.namespace
- kubernetes.node.name
- kubernetes.pod.name
如果将include_annotations配置添加到 providers,则会将 config 中存在的注解列表添加到 event 中。例如:
{
"data": {
"host": "172.17.0.21",
"port": 9090,
"kubernetes": {
"container": {
"id": "bb3a50625c01b16a88aa224779c39262a9ad14264c3034669a50cd9a90af1527",
"image": "prom/prometheus",
"name": "prometheus"
},
"labels": {
"project": "prometheus",
...
},
"namespace": "default",
"node": {
"name": "minikube"
},
"pod": {
"name": "prometheus-2657348378-k1pnh"
}
}
}
}
kubernetes provider 有如下配置项:
- in_cluster: (optional)在kubernetes客户端的集群设置中使用,默认为
true - host: (optional)标记filebeat运行节点的host,以防无法正确检测到。如在host network mode下运行filebeat时。
- kube_config: (optional)使用给定的配置文件作为kubernetes客户端的配置。
下面看一下具体的templates配置,如收集所有kubernetes.namespace=kube-system的 pods 的所有 containers 的日志
filebeat.autodiscover:
providers:
- type: kubernetes
templates:
- condition:
equals:
kubernetes.namespace: kube-system
config:
- type: docker
containers.ids:
- "${data.kubernetes.container.id}"
exclude_lines: ["^\\s+[\\-`('.|_]"] # drop asciiart lines
如果使用 modules,可以使用 docker input 重写 default input
filebeat.autodiscover:
providers:
- type: kubernetes
templates:
- condition:
equals:
kubernetes.container.image: "redis"
config:
- module: redis
log:
input:
type: docker
containers.ids:
- "${data.kubernetes.container.id}"
实战
使用 Kubernetes auto discover 进行日志收集
输出的日志程序
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import org.apache.logging.log4j.message.ObjectMessage;
import java.io.PrintWriter;
import java.io.StringWriter;
import java.util.HashMap;
import java.util.Map;
public class LogGenerator {
private final static Logger logger = LogManager.getLogger(LogGenerator.class);
public static void main(String[] args) {
nestedJsonLogs();
}
public static void nestedJsonLogs() {
while (true) {
// 输出 debug 信息到 rolling file
logger.debug("debug log zzzz");
// 输出异常栈信息到 stderr
StringWriter sw = new StringWriter();
PrintWriter pw = new PrintWriter(sw);
try {
throw new IllegalArgumentException("error log");
} catch (Exception e) {
e.printStackTrace(pw);
logger.error(sw.toString());
}
// 输出完整的 json 格式数据
Map<String, String> map = new HashMap<String, String>();
map.put("name", "张强");
map.put("age", "24");
map.put("province", "山东");
map.put("girlfriend", "唐嘉蕙");
ObjectMessage msg = new ObjectMessage(map);
logger.info(msg);
// 日志不要太快
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.rich</groupId>
<artifactId>jsonlogs</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!-- Log4j2 -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.11.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.11.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-1.2-api</artifactId>
<version>2.11.2</version>
</dependency>
<!-- Log4j2 Json Format Dependency -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.8</version>
</dependency>
<!-- 你也可以不引入这个依赖而是直接使用上面的依赖,或者使用 Google 的 Gson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.56</version>
</dependency>
<!--
为了模拟项目中包含老版本 Log4j 的情况,在这里引入了比较老的 HBase client,在这里,我将所有冲突的 jar
包全部排除后,然后 HBase 输出的日志就以 Log4j2 的配置输出了。
使用 Log4j2 不是强制要求,只要能正常输出日志就可以了,甚至是直接 System.out.prinltn()都是可以的。
但是个人推荐使用 Log4j2,不只是因为 Log4j2 支持完全的 Json Format Log 下面摘抄一下官网的原文:
Log4j 2 contains next-generation Asynchronous Loggers based on the LMAX Disruptor library.
In multi-threaded scenarios Asynchronous Loggers have 10 times higher throughput and orders
of magnitude lower latency than Log4j 1.x and Logback.
原文链接: https://logging.apache.org/log4j/2.x/manual/index.html
-->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-shaded-client</artifactId>
<version>1.1.2</version>
<!--
关于解决 jar 包冲突的问题,我向大家推荐一款 idea 的插件,叫 Maven Helper,大家可以搜一下,
使用非常简单、直观,比使用`mvn dependency:tree -Dverbose > dependency.log` 和 idea
自带的 analyser 工具方便的多的多。
-->
<exclusions>
<exclusion>
<artifactId>slf4j-log4j12</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
<exclusion>
<artifactId>slf4j-api</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
<exclusion>
<artifactId>log4j</artifactId>
<groupId>log4j</groupId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
</project>
配置 log4j2.properties
# ---------------------------------------------------
# -------------------- 定义变量 ----------------------
# ---------------------------------------------------
# `property`下的变量可以通过 ${filename} 获取相应的值
property.filename = target/rolling/rolling.log
# ---------------------------------------------------
# ------------------ 定义 appender -------------------
# ---------------------------------------------------
# ----------------- json logs -----------------
appender.json.type = Console
appender.json.name = stdout
appender.json.target = "SYSTEM_OUT"
appender.json.layout.type = JsonLayout
# If true, the appender does not use end-of-lines and indentation. Defaults to false.
appender.json.layout.compact = true
# If true, the appender appends an end-of-line after each record. Defaults to false. Use with eventEol=true and compact=true to get one record per line.
appender.json.layout.eventEol = true
# If true, ObjectMessage is serialized as JSON object to the "message" field of the output log. Defaults to false.
appender.json.layout.objectMessageAsJsonObject = true
# If true, the appender includes the JSON header and footer, and comma between records. Defaults to false.
appender.json.layout.complete = false
# If true, include full stacktrace of any logged Throwable (optional, default to true).
appender.json.layout.includeStacktrace = true
# Whether to format the stacktrace as a string, and not a nested object (optional, defaults to false).
appender.json.layout.stacktraceAsString = true
# If true, the appender includes the thread context map in the generated JSON. Defaults to false.
appender.json.layout.properties = false
# If true, the thread context map is included as a list of map entry objects, where each entry has a "key" attribute (whose value is the key) and a "value" attribute (whose value is the value). Defaults to false, in which case the thread context map is included as a simple map of key-value pairs.
appender.json.layout.propertiesAsList = false
appender.json.filter.threshold.type = ThresholdFilter
appender.json.filter.threshold.level = info
# ----------------- common logs -----------------
appender.console.type = Console
appender.console.name = stderr
appender.console.target = "SYSTEM_ERR"
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{yyyy-MM-dd HH:mm:ss.sss} %c{10} %level %m
appender.console.filter.threshold.type = ThresholdFilter
appender.console.filter.threshold.level = error
# ----------------- rolling file logs -----------------
appender.rolling.type = RollingFile
appender.rolling.name = rolling
appender.rolling.append = true
appender.rolling.bufferedIO = true
appender.rolling.immediateFlush = false
appender.rolling.fileName = ${filename}
appender.rolling.filePattern = target/rolling/rolling-%d{MM-dd-yy-HH-mm-ss}-%i.log.gz
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = %d %p %C{1.} [%t] %m%n
appender.rolling.policies.type = Policies
appender.rolling.policies.time.type = TimeBasedTriggeringPolicy
appender.rolling.policies.time.interval = 60 * 10
appender.rolling.policies.time.modulate = true
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling.policies.size.size = 100MB
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.max = 5
appender.rolling.filter.threshold.type = ThresholdFilter
appender.rolling.filter.threshold.level = debug
# ---------------------------------------------------
# ------------------- 启用 loggers -------------------
# ---------------------------------------------------
rootLogger.name = rootLogger
rootLogger.level = info
# `rootLogger.appenderRef.*.ref`通过`appender.*.name`指定前面定义好的 appender
rootLogger.appenderRef.stdout.ref = stdout
# 可以指定多个,保证`appenderRef`和`ref`之间的部分不冲突即可
rootLogger.appenderRef.stderr.ref = stderr
#rootLogger.appenderRef.rolling.ref = rolling
build docker image
关于 docker 相关操作可以参考Docker 实战
kubernetes-jsonlogs.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: log4j2-deployment
labels:
app: log4j2
spec:
replicas: 1
selector:
matchLabels:
app: log4j2
template:
metadata:
labels:
app: log4j2
spec:
containers:
- name: log4j2
image: 192.168.51.35:5000/log4j2_logs:v1
ports:
- containerPort: 80
kubernetes-filebeat.yaml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: default
labels:
k8s-app: filebeat
data:
filebeat.yml: |-
# k8s autodiscover
# To enable hints based autodiscover, you need to remove `filebeat.config.inputs` configuration and uncomment this:
filebeat.autodiscover:
providers:
- type: kubernetes
# 开启基于提供程序提示的自动发现,它会在kubernetes pod注释或去具有前缀co.elastic.logs的docker标签中查找提示
# hints.enabled: true
templates:
# 这里可以新建多个模板以匹配多个不同的条件
- condition.and:
- equals:
kubernetes.namespace: default
- contains:
kubernetes.container.name: log4j2
config:
# 同理这里也可以配置多个 inputs
- type: docker
containers:
# all, stdout, stderr
stream: all
ids:
- "${data.kubernetes.container.id}"
# 添加自定义字段,默认放在字段 "fields" 下
fields:
log_type: "${data.kubernetes.container.name}"
# 合并 java 异常栈为一条,将匹配的行放在不匹配行的后面
multiline:
pattern: '^\t'
negate: false
match: after
# # 对合法的 json 字符串进行解析,注意必须是 json 字符串,json object 解析不出来
# json:
# # 解析出的 key 不要放在 root 下,默认放在字段 "json" 下,这样可以避免很多 key 冲突
# keys_under_root: false
# add_error_key: true
# # 如果解析出的 key 和已有的 key 冲突,覆盖
# overwrite_keys: true
# # 指定以哪个 key 的值为标准,进行匹配过滤和多行合并,这个应以 debug publish 解析出的字段为准,而不是原生 docker logs
# # 的字段,比如"log"。因为在 line filtering、multiline 和 JSON decoding 之前已经被解析成了到了"message"中,并且提
# # 取了"timestamps"到"@timestamps",因此如果这里指定"log"的话,根本解析不出日志来。
# # message_key 只能指定 root 下的 key,而且 value 必须是 string 类型的,如果是 jsonObject 会报错
# message_key: "message"
# ignore_decoding_error: false
# filter and enhance fields
processors:
# # 添加 k8s 相关元数据
# - add_kubernetes_metadata:
# in_cluster: true
# 字段重命名
- rename:
fields:
- from: "message"
to: "raw_message"
# 对合法的 json 字符串进行解析,注意必须是 json 字符串,json object 解析不出来
- decode_json_fields:
# 指定要解析的字段
fields: ["raw_message"]
# 是否解析 json 数组
process_array: true
# 最大 json 解析层数
max_depth: 10
# `target: ""`代表合并到 event 根下,或者指定的字段下,不写则覆盖被解析的字段,比如"message"
target: "json_message"
# 如果已经存在解析出来的 key,是否覆盖
overwrite_keys: true
# 保证 es mapping 不会有字段类型冲突
- rename:
# 如果字段 json_message.message 不是字符串,而是 json object 就改名为 json_message.json
when:
not:
regexp:
json_message.message: ".*"
fields:
- from: "json_message.message"
to: "json_message.json"
# 丢掉一些不需要的字段
- drop_fields:
fields: ['input', 'beat', 'prospector', 'kubernetes']
# 如果是 json 类型的日志,丢弃原生日志
- drop_fields:
when:
has_fields: ['json_message']
fields: ['raw_message']
# 配置 elasticsearch index template
setup.template.name: "logs"
setup.template.pattern: "logs-*"
# 如果为 false,在修改了 setup.template.settings 后需要手动删除 elasticsearch 的 template 才有效
setup.template.overwrite: true
setup.template.settings:
index.number_of_shards: 3
index.codec: best_compression
# 必须启用!默认模版会把 event 信息放到 _source 字段下
_source.enabled: true
# 设置 elasticsearch output https://www.elastic.co/guide/en/beats/filebeat/current/elasticsearch-output.html
output.elasticsearch:
hosts: ["http://192.168.51.81:9200", "http://192.168.51.82:9200"]
# https://www.elastic.co/guide/en/beats/filebeat/current/elasticsearch-output.html#index-option-es
index: "logs-%{[fields.log_type]}-%{+yyyy.MM.dd}"
# =========== filebeat 运行日志 ===========
path.logs: /usr/share/filebeat/logs
# =========== debug logging ===========
logging.level: debug
# Enable debug output for selected components,可用的选项 "beat", "publish", "service", 全选使用 ["*"]
logging.selectors: ["publish"]
# 可以通过 docker logs 查看 debug 日志
logging.to_stderr: true
logging.to_eventlog: false
logging.to_syslog: false
# 改为 true 启用写到指定 file 文件
logging.to_files: false
logging.files:
path: /usr/share/filebeat/logs
name: filebeat
logging.json: false
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: filebeat
namespace: default
labels:
k8s-app: filebeat
spec:
template:
metadata:
labels:
k8s-app: filebeat
spec:
# 指定运行在当前 pod 的 Service Account
serviceAccountName: filebeat
terminationGracePeriodSeconds: 30
containers:
# docker compose
- name: filebeat
image: 192.168.51.35:5000/filebeat:6.4.0
# -d 启用对指定选择器的调试,publish 可以看到完整的 event 信息
args: [
"-c", "/etc/filebeat.yml",
"-e",
"-d", "publish"
]
env:
- name: ES_HOST
value: "192.168.51.81"
- name: ES_PORT
value: "9200"
securityContext:
runAsUser: 0
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
# 将指定 volumes mount 到容器内的路径
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
# registry 文件路径,用于记录 filebeat 读取本节点文件的 status
- name: data
mountPath: /usr/share/filebeat/data
- name: logs
mountPath: /usr/share/filebeat/logs
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
# 创建 volumes
volumes:
- name: config
configMap:
defaultMode: 0600
name: filebeat-config
# data folder stores a registry of read status for all files, so we don't send everything again on a Filebeat pod restart
- name: data
hostPath:
path: /var/lib/filebeat-data
type: DirectoryOrCreate
- name: logs
hostPath:
path: /var/lib/filebeat-logs
type: DirectoryOrCreate
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: filebeat
# 主题包含对该角色适用的对象的引用
subjects:
- kind: ServiceAccount
name: filebeat
namespace: default
# 只能引用全局 namespace 中的 clusterRole。如果无法解析 roleRef,则 Authorizer 一定会返回错误。
roleRef:
kind: ClusterRole
name: filebeat
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: filebeat
labels:
k8s-app: filebeat
# 此 ClusterRole 的所有策略规则
rules:
# 包含 resources 的 apiGroup 的名字,如果指定了多个 apiGroup,
# 那么对于任何一个 apiGroup 资源请求的任何操作都会允许
# "" indicates the core API group
- apiGroups: [""]
# 此 rule 适用的资源列表,`ResourceAll`代表所有资源
resources:
- namespaces
- pods
# 此 rule 适用的所有资源类型和属性限制的动词列表,`VerbAll`代表所有动词
verbs:
- get
- watch
- list
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat
namespace: default
labels:
k8s-app: filebeat
---




