
Flink 简介
Flink 作为流计算引擎的优点
- Low Latency
- Exactly Once
- 流批统一
- 可以支持足够大数据量和复杂计算
不同于 Spark,Flink 是一个真正意义上的流计算引擎,和 Storm 类似,Flink 是通过流水线数据传输实现低延迟的流处理;Flink 使用了经典的 Chandy-Lamport 算法,能够在满足低延迟和低 failover 开销的基础之上,完美地解决 exactly once 的目标;如果要用一套引擎来统一流处理和批处理,那就必须以流处理引擎为基础。Flink 还提供了 SQL/TableAPI 两个 API,为批和流在 Query 层的统一铺平了道路。因此 Flink 是最合适的批和流统一的引擎;最后,Flink 在设计之初就非常在意性能相关的任务状态 state 和流控等关键技术的设计,这些都使得用 Flink 执行复杂的大规模任务时性能更胜一筹。
Flink Architecture
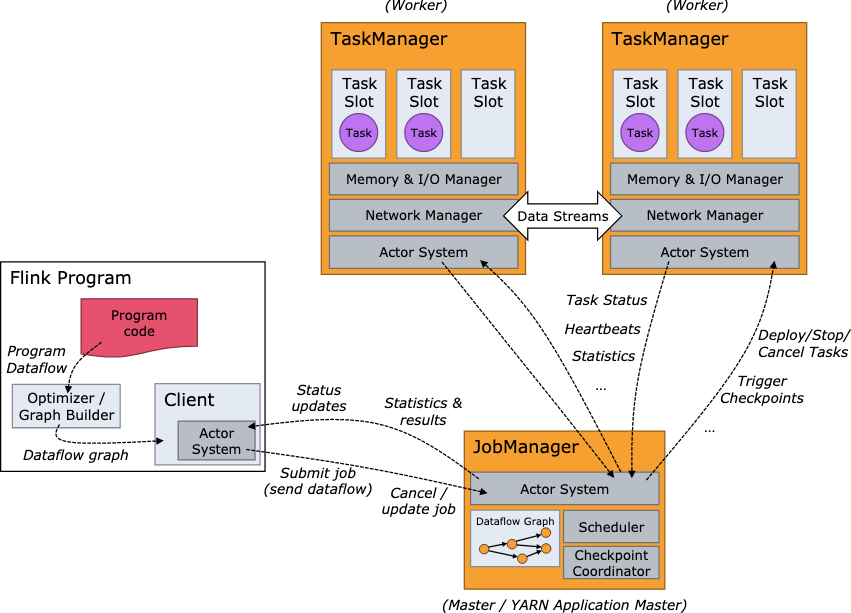
Flink架构中有三个重要的角色:
- Client: Client 不属于 runtime,而是用于处理用户代码,构建 JobGraph 并将其发送到 JobManager
- JobManager: 负责部署 JobGraph、管理 TaskManager、管理作业运行状态
- TaskManager: 负责执行具体的Task
Flink Dataflow Programming Model
API 抽象等级
Flink APIs 由低到高共抽象为四层
Low-Level building block - Stateful Stream Processing
最底层的抽象只提供有状态的流(stateful streaming)。通过把 process function 嵌入到 DataStream API
中。他允许用户处理来自一个或多个流的event,并使用一致的容错状态(consistent fault tolerant state)
。除此之外,用户还可以注册事件时间(register event time)和处理时间回调(process time callbacks),来实现复杂的计算。
Core APIs - DataStream/DataSet API
实际上大多数情况下不需要低级抽象,而是使用 Core APIs,如 DataStream API(有界/无界流)和 DataSet API(有界数据集)。这些 API 提供了用于数据处理的通用构建块,如各种形式的转换(transform)、连接(join)、聚合(aggregation)、窗口(window)、状态(state)等。
因为是低级 Process Functions 和 DataStream API 集成,因此只能对某些操作进行低级抽象。DataSet API 在有界数据集上提供了额外的 primitives,如循环/迭代。
Declarative DSL - Table API
Table API 是以表为中心的声明性 DSL,可以动态更改表(表示流时)。 Table API 遵循(扩展)关系模型:表附加了一个模式( 类似于关系数据库中的表),API 提供了类似的操作,例如 select,project,join,group-by,aggregate 等。Table API 程序以声明方式定义应该执行的逻辑操作,而不是用特定的代码实现具体的操作。尽管 Table API 可以通过各种类型的用户定义函数进行扩展,但它的表现力不如 Core API,但使用起来更简洁(编写的代码更少)。此外,Table API 在执行之前会先经过优化器,根据优化规则进行优化。
可以在表和 DataStream/DataSet 之间无缝转换,允许程序混合 Table API 以及 DataStream 和 DataSet API。
High-level Language - SQL
Flink 提供的最高级抽象是 SQL。这种抽象在语义和表达方面类似于 Table API,但是用 SQL 语句代表程序。 SQL 抽象与 Table API 紧密交互,SQL 查询可以在 Table API 中定义的表上执行。
Distributed Runtime
Basic API Concepts
Flink Programs
Flink Programs 是实现了 distributed collections,并对其进行 transformations(e.g., filtering, mapping, updating state, joining, grouping, defining windows, aggregating) 的通用程序。Flink Programs 可以运行在各种 contexts,standalone,embedded in other programs(e.g., YARN),Execution 既可以在本地 JVM 执行,也可以在有多个机器构成的集群上运行。
编写一个 Batch Program 还是一个 Streaming Program,取决于要处理的 DataSources 是有界(bounded)的还是无界(unbounded) 的,DataSet API 用于编写 Batch Programs,而 DataStream API 用于编写 Streaming Programs。
DataSet & DataStream
Deployment & Clusters
Flink Job 的部署模式
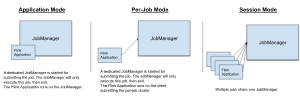
Application Mode: 专门为一个应用程序创建一个集群,Job 的 main() 方法 在 JobManager 中执行,在一个 Application
里面可以执行多次 execute()/executeSync(),也就是可以同时构建多个 JobGraph
Per-Job Mode (Deprecated): 专门为一个
Job 创建一个集群,Job 的 main() 方法在 Client 端执行,在集群创建之前就已经执行完了(构建好了
JobGraph)
Session Mode: 一个 JobManager 实例管理多个提交的 Job,这些 Job 共享集群的 TaskManagers,Job 的 main()
方法也在 Client 端执行
Step1: 配置环境变量
Flink On YARN 需要YARN_CONF_DIR或者HADOOP_CONF_DIR环境变量去获取 YARN 和 HDFS 配置
$ vim ~/.bash_profile
# 如果不配置,可能会报各种 NoClassDefFoundError
export HAOODP_CLASSPATH=`hadoop classpath`
# 如果不配置,会有如下问题
# Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR was set.
# Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set. The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.
export HADOOP_CONF_DIR="/etc/hadoop/conf"
export FLINK_HOME="/home/hdfs/flink-1.7.1"
export PATH=$PATH:$FLINK_HOME/bin
$ source ~/.bash_profile
# 修改 flink-conf.yaml
$ vim $FLINK_HOME/flink-conf.yaml
# 默认是内存存储,很容易 OOM
state.backend: filesystem
# 注意给当前文件夹足够的权限,比如 777
state.checkpoints.dir: hdfs:///flink-checkpoints
state.savepoints.dir: hdfs://flink-checkpoints
# Flink 启动 YARN-Session 会话的时候会把所有相关的组件(如依赖包、配置文件等等)上传到该目录
# 保证 Flink 对该目录有足够的访问权限
$ hadoop fs -mkdir -p /user/${current_user:root}/.flink
$ hadoop fs -chmod -R 777 /user/${current_user:root}
# 成功启动一个YARN-Session后,实际生成目录结构如下,可以看到该YARN-Session指定了3个taskManager
-rw-r--r-- 3 root hadoop 384 2019-02-02 16:32 /user/root/.flink/application_1548409829387_0057/f11d0b7c-0ea3-4cec-bab8-cb850a27a82e-taskmanager-conf.yaml
-rw-r--r-- 3 root hadoop 384 2019-01-29 16:26 /user/root/.flink/application_1548409829387_0057/f834efc9-4c44-4fe8-a6c2-7a59b21e835d-taskmanager-conf.yaml
-rw-r--r-- 3 root hadoop 384 2019-01-29 17:50 /user/root/.flink/application_1548409829387_0057/fccff855-216c-4cf0-bc54-f7d1136ba72d-taskmanager-conf.yaml
-rw-r--r-- 3 root hadoop 88.9 M 2018-12-15 12:06 /user/root/.flink/application_1548409829387_0057/flink-dist_2.11-1.7.1.jar
drwxr-xr-x - root hadoop 0 2019-01-29 13:51 /user/root/.flink/application_1548409829387_0057/lib
-rw-r--r-- 3 root hadoop 1.9 K 2018-12-11 20:39 /user/root/.flink/application_1548409829387_0057/log4j.properties
-rw-r--r-- 3 root hadoop 2.3 K 2018-12-11 20:39 /user/root/.flink/application_1548409829387_0057/logback.xml
Step2: Submit Job to Flink
Run Flink job within Running YARN Session
一个 YARN-Session 会启动所有必要的 Flink Services(JobManager and TaskManager),这样就可以提交程序到 cluster,每个 session 可以同时运行多个程序。
- Launch YARN Session: 在 YARN 上启动 Flink 集群
# 查看 yarn-session.sh 使用帮助
$ yarn-session.sh -h
Usage:
Required
-n,--container <arg> Number of YARN container to allocate (=Number of Task Managers)
Optional
-D <property=value> use value for given property
# 启动一个 yarn session
# 分配注意不要超过 yarn 的实际资源,否则会报错!
# 10 TaskManagers, 8192MB memory per TaskManager, 32 processing slots(vcores) per TaskManager
$ ./bin/yarn-session.sh \
--name "Flink YARN Session" \
--container 10 \
--taskManagerMemory 8192 \
--slots 32 \
--detached
# attach to an existing YARN session
# 连接到 application_1547006608740_4071
$ ./bin/yarn-session.sh -id application_1548409829387_0024
# Stop the YARN session by stopping the unix process (using CTRL+C) or by entering ‘stop’ into the client.
# 如果不想让 Flink YARN client 一直运行,也可以启动分离(detached)的 YARN-Session。
# 这种情况下,Flink YARN client 将仅向群集提交 Flink,然后自行关闭,类似 Spark On YARN 的 cluster 模式。
$ ./bin/yarn-session.sh -d
# 但是这样就无法使用 Flink 停止 YARN-Session 了,而是通过下面的命令停止
$ yarn application -kill application_1548409829387_0024
# 查看 YARN-Session 日志,访问 YARN 集群管理界面,查看 application_1548409829387_0024 的启动日志
# Note:另外,提交到该 Session 的 Flink Jobs 的日志也会输出到这里,这里为了方便查看,忽略了部分时间和类信息。
--------------------------------------------------------------------------------
Starting YarnSessionClusterEntrypoint (Version: 1.7.1, Rev:89eafb4, Date:14.12.2018 @ 15:48:34 GMT)
OS current user: yarn
Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Current Hadoop/Kerberos user: root
JVM: Java HotSpot(TM) 64-Bit Server VM - Oracle Corporation - 1.8/25.181-b13
Maximum heap size: 406 MiBytes
JAVA_HOME: /usr/java/jdk1.8.0_181-amd64
Hadoop version: 2.7.5
JVM Options:
-Xmx424m
-Dlog.file=/hadoop/yarn/log/application_1548409829387_0024/container_e07_1548409829387_0024_01_000001/jobmanager.log
-Dlogback.configurationFile=file:logback.xml
-Dlog4j.configuration=file:log4j.properties
Program Arguments: (none)
Classpath: lib/flink-python_2.11-1.7.1.jar:lib/flink-shaded-hadoop2-uber-1.7.1.jar:lib/log4j-1.2.17.jar:lib/slf4j-log4j12-1.7.15.jar:log4j.properties:logback.xml:flink.jar:flink-conf.yaml::/usr/hdp/2.6.4.0-91/hadoop/conf:/usr/hdp/2.6.4.0-91/hadoop/azure-data-lake-store-sdk-2.1.4.jar:/usr/hdp/2.6.4.0-91/hadoop/hadoop-annotations-2.7.3.2.6.4.0-91.jar:/usr/hdp/2.6.4.0-91/hadoop/hadoop-annotations.jar:/usr/hdp/2.6.4.0-91/hadoop/hadoop-auth-2.7.3.2.6.4.0-91.jar:/usr/hdp/2.6.4.0-91/hadoop/hadoop-auth.jar:/usr/hdp/2.6.4.0-91/hadoop/hadoop-aws-2.7.3.2.6.4.0-91.jar:/usr/hdp/2.6.4.0-91/hadoop/hadoop-aws.jar:/usr/hdp/2.6.4.0-91/hadoop/hadoop-azure-2.7.3.2.6.4.0-91.jar:/usr/hdp/2.6.4.0-91/hadoop/hadoop-azure-datalake-2.7.3.2.6.4.0-91.jar:/usr/hdp/2.6.4.0-91/hadoop/hadoop-azure-datalake.jar:/usr/hdp/2.6.4.0-91/hadoop/hadoop-azure.jar:/usr/hdp/2.6.4.0-91/hadoop/hadoop-common-2.7.3.2.6.4.0-91-tests.jar:/usr/hdp/2.6.4.0-91/hadoop/hadoop-common-2.7.3.2.6.4.0-91.jar:/usr/hdp/2.6.4.0-91/hadoop/hadoop-common-tests.jar:/usr/hdp/2.6.4.0-91/hadoop/hadoop-common.jar:/usr/hdp/2.6.4.0-91/hadoop/hadoop-nfs-2.7.3.2.6.4.0-91.jar:/usr/hdp/2.6.4.0-91/hadoop/hadoop-nfs.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/ojdbc6.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/jackson-annotations-2.2.3.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/ranger-hdfs-plugin-shim-0.7.0.2.6.4.0-91.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/jackson-core-2.2.3.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/ranger-plugin-classloader-0.7.0.2.6.4.0-91.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/jcip-annotations-1.0.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/ranger-yarn-plugin-shim-0.7.0.2.6.4.0-91.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/xmlenc-0.52.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/activation-1.1.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/jettison-1.1.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/apacheds-i18n-2.0.0-M15.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/jackson-databind-2.2.3.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/jetty-6.1.26.hwx.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/api-asn1-api-1.0.0-M20.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/jetty-sslengine-6.1.26.hwx.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/api-util-1.0.0-M20.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/asm-3.2.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/xz-1.0.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/avro-1.7.4.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/jackson-jaxrs-1.9.13.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/aws-java-sdk-core-1.10.6.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/jetty-util-6.1.26.hwx.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/aws-java-sdk-kms-1.10.6.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/joda-time-2.9.4.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/aws-java-sdk-s3-1.10.6.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/jackson-mapper-asl-1.9.13.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/azure-keyvault-core-0.8.0.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/jsch-0.1.54.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/azure-storage-5.4.0.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/json-smart-1.1.1.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/commons-beanutils-1.7.0.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/commons-beanutils-core-1.8.0.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/commons-cli-1.2.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/jsp-api-2.1.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/commons-codec-1.4.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/jersey-json-1.9.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/commons-collections-3.2.2.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/jsr305-3.0.0.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/commons-compress-1.4.1.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/jersey-server-1.9.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/commons-configuration-1.6.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/junit-4.11.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/commons-digester-1.8.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/commons-io-2.4.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/log4j-1.2.17.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/commons-lang-2.6.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/mockito-all-1.8.5.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/commons-lang3-3.4.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/nimbus-jose-jwt-3.9.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/commons-logging-1.1.3.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/netty-3.6.2.Final.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/commons-math3-3.1.1.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/commons-net-3.1.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/paranamer-2.3.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/curator-client-2.7.1.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/protobuf-java-2.5.0.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/curator-framework-2.7.1.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/servlet-api-2.5.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/curator-recipes-2.7.1.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/gson-2.2.4.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/guava-11.0.2.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/slf4j-api-1.7.10.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/hamcrest-core-1.3.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/jets3t-0.9.0.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/htrace-core-3.1.0-incubating.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/slf4j-log4j12-1.7.10.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/httpclient-4.5.2.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/httpcore-4.4.4.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/jackson-core-asl-1.9.13.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/jackson-xc-1.9.13.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/snappy-java-1.0.4.1.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/java-xmlbuilder-0.4.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/jaxb-api-2.2.2.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/stax-api-1.0-2.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/jaxb-impl-2.2.3-1.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/jersey-core-1.9.jar:/usr/hdp/2.6.4.0-91/hadoop/lib/zookeeper-3.4.6.2.6.4.0-91.jar:/usr/hdp/current/hadoop-hdfs-client/hadoop-hdfs-2.7.3.2.6.4.0-91-tests.jar:/usr/hdp/current/hadoop-hdfs-client/hadoop-hdfs-2.7.3.2.6.4.0-91.jar:/usr/hdp/current/hadoop-hdfs-client/hadoop-hdfs-nfs-2.7.3.2.6.4.0-91.jar:/usr/hdp/current/hadoop-hdfs-client/hadoop-hdfs-nfs.jar:/usr/hdp/current/hadoop-hdfs-client/hadoop-hdfs-tests.jar:/usr/hdp/current/hadoop-hdfs-client/hadoop-hdfs.jar:/usr/hdp/current/hadoop-hdfs-client/lib/asm-3.2.jar:/usr/hdp/current/hadoop-hdfs-client/lib/commons-cli-1.2.jar:/usr/hdp/current/hadoop-hdfs-client/lib/commons-codec-1.4.jar:/usr/hdp/current/hadoop-hdfs-client/lib/commons-daemon-1.0.13.jar:/usr/hdp/current/hadoop-hdfs-client/lib/commons-io-2.4.jar:/usr/hdp/current/hadoop-hdfs-client/lib/commons-lang-2.6.jar:/usr/hdp/current/hadoop-hdfs-client/lib/commons-logging-1.1.3.jar:/usr/hdp/current/hadoop-hdfs-client/lib/guava-11.0.2.jar:/usr/hdp/current/hadoop-hdfs-client/lib/htrace-core-3.1.0-incubating.jar:/usr/hdp/current/hadoop-hdfs-client/lib/jackson-annotations-2.2.3.jar:/usr/hdp/current/hadoop-hdfs-client/lib/jackson-core-2.2.3.jar:/usr/hdp/current/hadoop-hdfs-client/lib/jackson-core-asl-1.9.13.jar:/usr/hdp/current/hadoop-hdfs-client/lib/jackson-databind-2.2.3.jar:/usr/hdp/current/hadoop-hdfs-client/lib/jackson-mapper-asl-1.9.13.jar:/usr/hdp/current/hadoop-hdfs-client/lib/jersey-core-1.9.jar:/usr/hdp/current/hadoop-hdfs-client/lib/jersey-server-1.9.jar:/usr/hdp/current/hadoop-hdfs-client/lib/jetty-6.1.26.hwx.jar:/usr/hdp/current/hadoop-hdfs-client/lib/jetty-util-6.1.26.hwx.jar:/usr/hdp/current/hadoop-hdfs-client/lib/jsr305-3.0.0.jar:/usr/hdp/current/hadoop-hdfs-client/lib/leveldbjni-all-1.8.jar:/usr/hdp/current/hadoop-hdfs-client/lib/log4j-1.2.17.jar:/usr/hdp/current/hadoop-hdfs-client/lib/netty-3.6.2.Final.jar:/usr/hdp/current/hadoop-hdfs-client/lib/netty-all-4.0.52.Final.jar:/usr/hdp/current/hadoop-hdfs-client/lib/okhttp-2.4.0.jar:/usr/hdp/current/hadoop-hdfs-client/lib/okio-1.4.0.jar:/usr/hdp/current/hadoop-hdfs-client/lib/protobuf-java-2.5.0.jar:/usr/hdp/current/hadoop-hdfs-client/lib/servlet-api-2.5.jar:/usr/hdp/current/hadoop-hdfs-client/lib/xercesImpl-2.9.1.jar:/usr/hdp/current/hadoop-hdfs-client/lib/xml-apis-1.3.04.jar:/usr/hdp/current/hadoop-hdfs-client/lib/xmlenc-0.52.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-api-2.7.3.2.6.4.0-91.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-api.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-applications-distributedshell-2.7.3.2.6.4.0-91.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-applications-distributedshell.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-applications-unmanaged-am-launcher-2.7.3.2.6.4.0-91.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-applications-unmanaged-am-launcher.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-client-2.7.3.2.6.4.0-91.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-client.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-common-2.7.3.2.6.4.0-91.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-common.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-registry-2.7.3.2.6.4.0-91.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-registry.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-server-applicationhistoryservice-2.7.3.2.6.4.0-91.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-server-applicationhistoryservice.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-server-common-2.7.3.2.6.4.0-91.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-server-common.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-server-nodemanager-2.7.3.2.6.4.0-91.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-server-nodemanager.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-server-resourcemanager-2.7.3.2.6.4.0-91.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-server-resourcemanager.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-server-sharedcachemanager-2.7.3.2.6.4.0-91.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-server-sharedcachemanager.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-server-tests-2.7.3.2.6.4.0-91.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-server-tests.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-server-timeline-pluginstorage-2.7.3.2.6.4.0-91.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-server-timeline-pluginstorage.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-server-web-proxy-2.7.3.2.6.4.0-91.jar:/usr/hdp/current/hadoop-yarn-client/hadoop-yarn-server-web-proxy.jar:/usr/hdp/current/hadoop-yarn-client/lib/activation-1.1.jar:/usr/hdp/current/hadoop-yarn-client/lib/aopalliance-1.0.jar:/usr/hdp/current/hadoop-yarn-client/lib/jsch-0.1.54.jar:/usr/hdp/current/hadoop-yarn-client/lib/apacheds-i18n-2.0.0-M15.jar:/usr/hdp/current/hadoop-yarn-client/lib/jersey-core-1.9.jar:/usr/hdp/current/hadoop-yarn-client/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/usr/hdp/current/hadoop-yarn-client/lib/jetty-6.1.26.hwx.jar:/usr/hdp/current/hadoop-yarn-client/lib/api-asn1-api-1.0.0-M20.jar:/usr/hdp/current/hadoop-yarn-client/lib/jetty-sslengine-6.1.26.hwx.jar:/usr/hdp/current/hadoop-yarn-client/lib/api-util-1.0.0-M20.jar:/usr/hdp/current/hadoop-yarn-client/lib/asm-3.2.jar:/usr/hdp/current/hadoop-yarn-client/lib/avro-1.7.4.jar:/usr/hdp/current/hadoop-yarn-client/lib/java-xmlbuilder-0.4.jar:/usr/hdp/current/hadoop-yarn-client/lib/azure-keyvault-core-0.8.0.jar:/usr/hdp/current/hadoop-yarn-client/lib/jetty-util-6.1.26.hwx.jar:/usr/hdp/current/hadoop-yarn-client/lib/azure-storage-5.4.0.jar:/usr/hdp/current/hadoop-yarn-client/lib/json-smart-1.1.1.jar:/usr/hdp/current/hadoop-yarn-client/lib/commons-beanutils-1.7.0.jar:/usr/hdp/current/hadoop-yarn-client/lib/javassist-3.18.1-GA.jar:/usr/hdp/current/hadoop-yarn-client/lib/commons-beanutils-core-1.8.0.jar:/usr/hdp/current/hadoop-yarn-client/lib/commons-cli-1.2.jar:/usr/hdp/current/hadoop-yarn-client/lib/jsp-api-2.1.jar:/usr/hdp/current/hadoop-yarn-client/lib/commons-codec-1.4.jar:/usr/hdp/current/hadoop-yarn-client/lib/javax.inject-1.jar:/usr/hdp/current/hadoop-yarn-client/lib/commons-collections-3.2.2.jar:/usr/hdp/current/hadoop-yarn-client/lib/jsr305-3.0.0.jar:/usr/hdp/current/hadoop-yarn-client/lib/commons-compress-1.4.1.jar:/usr/hdp/current/hadoop-yarn-client/lib/jersey-guice-1.9.jar:/usr/hdp/current/hadoop-yarn-client/lib/commons-configuration-1.6.jar:/usr/hdp/current/hadoop-yarn-client/lib/leveldbjni-all-1.8.jar:/usr/hdp/current/hadoop-yarn-client/lib/commons-digester-1.8.jar:/usr/hdp/current/hadoop-yarn-client/lib/commons-io-2.4.jar:/usr/hdp/current/hadoop-yarn-client/lib/log4j-1.2.17.jar:/usr/hdp/current/hadoop-yarn-client/lib/commons-lang-2.6.jar:/usr/hdp/current/hadoop-yarn-client/lib/metrics-core-3.0.1.jar:/usr/hdp/current/hadoop-yarn-client/lib/commons-lang3-3.4.jar:/usr/hdp/current/hadoop-yarn-client/lib/netty-3.6.2.Final.jar:/usr/hdp/current/hadoop-yarn-client/lib/commons-logging-1.1.3.jar:/usr/hdp/current/hadoop-yarn-client/lib/nimbus-jose-jwt-3.9.jar:/usr/hdp/current/hadoop-yarn-client/lib/commons-math3-3.1.1.jar:/usr/hdp/current/hadoop-yarn-client/lib/commons-net-3.1.jar:/usr/hdp/current/hadoop-yarn-client/lib/objenesis-2.1.jar:/usr/hdp/current/hadoop-yarn-client/lib/curator-client-2.7.1.jar:/usr/hdp/current/hadoop-yarn-client/lib/paranamer-2.3.jar:/usr/hdp/current/hadoop-yarn-client/lib/curator-framework-2.7.1.jar:/usr/hdp/current/hadoop-yarn-client/lib/protobuf-java-2.5.0.jar:/usr/hdp/current/hadoop-yarn-client/lib/curator-recipes-2.7.1.jar:/usr/hdp/current/hadoop-yarn-client/lib/fst-2.24.jar:/usr/hdp/current/hadoop-yarn-client/lib/gson-2.2.4.jar:/usr/hdp/current/hadoop-yarn-client/lib/guava-11.0.2.jar:/usr/hdp/current/hadoop-yarn-client/lib/guice-3.0.jar:/usr/hdp/current/hadoop-yarn-client/lib/servlet-api-2.5.jar:/usr/hdp/current/hadoop-yarn-client/lib/guice-servlet-3.0.jar:/usr/hdp/current/hadoop-yarn-client/lib/jersey-json-1.9.jar:/usr/hdp/current/hadoop-yarn-client/lib/htrace-core-3.1.0-incubating.jar:/usr/hdp/current/hadoop-yarn-client/lib/snappy-java-1.0.4.1.jar:/usr/hdp/current/hadoop-yarn-client/lib/httpclient-4.5.2.jar:/usr/hdp/current/hadoop-yarn-client/lib/httpcore-4.4.4.jar:/usr/hdp/current/hadoop-yarn-client/lib/jersey-server-1.9.jar:/usr/hdp/current/hadoop-yarn-client/lib/jackson-annotations-2.2.3.jar:/usr/hdp/current/hadoop-yarn-client/lib/stax-api-1.0-2.jar:/usr/hdp/current/hadoop-yarn-client/lib/jackson-core-2.2.3.jar:/usr/hdp/current/hadoop-yarn-client/lib/xmlenc-0.52.jar:/usr/hdp/current/hadoop-yarn-client/lib/jackson-core-asl-1.9.13.jar:/usr/hdp/current/hadoop-yarn-client/lib/xz-1.0.jar:/usr/hdp/current/hadoop-yarn-client/lib/jackson-databind-2.2.3.jar:/usr/hdp/current/hadoop-yarn-client/lib/zookeeper-3.4.6.2.6.4.0-91.jar:/usr/hdp/current/hadoop-yarn-client/lib/jackson-jaxrs-1.9.13.jar:/usr/hdp/current/hadoop-yarn-client/lib/jets3t-0.9.0.jar:/usr/hdp/current/hadoop-yarn-client/lib/jackson-mapper-asl-1.9.13.jar:/usr/hdp/current/hadoop-yarn-client/lib/zookeeper-3.4.6.2.6.4.0-91-tests.jar:/usr/hdp/current/hadoop-yarn-client/lib/jackson-xc-1.9.13.jar:/usr/hdp/current/hadoop-yarn-client/lib/jaxb-api-2.2.2.jar:/usr/hdp/current/hadoop-yarn-client/lib/jaxb-impl-2.2.3-1.jar:/usr/hdp/current/hadoop-yarn-client/lib/jcip-annotations-1.0.jar:/usr/hdp/current/hadoop-yarn-client/lib/jersey-client-1.9.jar:/usr/hdp/current/hadoop-yarn-client/lib/jettison-1.1.jar:/usr/hdp/current/ext/hadoop/*
--------------------------------------------------------------------------------
Registered UNIX signal handlers for [TERM, HUP, INT]
YARN daemon is running as: root Yarn client user obtainer: root
Loading configuration property: rest.port, 8081
Loading configuration property: internal.cluster.execution-mode, NORMAL
Loading configuration property: parallelism.default, 1
Loading configuration property: high-availability.cluster-id, application_1548409829387_0024
Loading configuration property: jobmanager.rpc.address, localhost
Loading configuration property: taskmanager.numberOfTaskSlots, 3
Loading configuration property: jobmanager.rpc.port, 6123
Loading configuration property: taskmanager.heap.size, 4096m
Loading configuration property: jobmanager.heap.size, 1024m
Setting directories for temporary files to: /hadoop/yarn/local/usercache/root/appcache/application_1548409829387_0024,/data/hadoop/yarn/local/usercache/root/appcache/application_1548409829387_0024
Starting YarnSessionClusterEntrypoint.
Install default filesystem.
Hadoop user set to root (auth:SIMPLE)
Initializing cluster services.
Trying to start actor system at hadoop4:0
Slf4jLogger started
Starting remoting
Remoting started; listening on addresses :[akka.tcp://flink@hadoop4:36701]
Actor system started at akka.tcp://flink@hadoop4:36701
Created BLOB server storage directory /data/hadoop/yarn/local/usercache/root/appcache/application_1548409829387_0024/blobStore-3478c7e8-dec7-4762-b86e-8ba6f8c735be
Started BLOB server at 0.0.0.0:37214 - max concurrent requests: 50 - max backlog: 1000
No metrics reporter configured, no metrics will be exposed/reported.
Trying to start actor system at hadoop4:0
Slf4jLogger started
Starting remoting
Actor system started at akka.tcp://flink-metrics@hadoop4:43522
Remoting started; listening on addresses :[akka.tcp://flink-metrics@hadoop4:43522]
Initializing FileArchivedExecutionGraphStore: Storage directory /hadoop/yarn/local/usercache/root/appcache/application_1548409829387_0024/executionGraphStore-6fee972e-9636-4313-b7d4-060c1f2c8900, expiration time 3600000, maximum cache size 52428800 bytes.
Created BLOB cache storage directory /data/hadoop/yarn/local/usercache/root/appcache/application_1548409829387_0024/blobStore-6b334ec7-a3be-4889-a88d-589df96a1504
Upload directory /tmp/flink-web-d19ff756-c114-4c5e-a352-c5a36dc588f5/flink-web-upload does not exist, or has been deleted externally. Previously uploaded files are no longer available.
Created directory /tmp/flink-web-d19ff756-c114-4c5e-a352-c5a36dc588f5/flink-web-upload for file uploads.
Starting rest endpoint.
Determined location of main cluster component log file: /hadoop/yarn/log/application_1548409829387_0024/container_e07_1548409829387_0024_01_000001/jobmanager.log
Determined location of main cluster component stdout file: /hadoop/yarn/log/application_1548409829387_0024/container_e07_1548409829387_0024_01_000001/jobmanager.out
Rest endpoint listening at hadoop4:40450
http://hadoop4:40450 was granted leadership with leaderSessionID=00000000-0000-0000-0000-000000000000
Web frontend listening at http://hadoop4:40450.
Starting RPC endpoint for org.apache.flink.yarn.YarnResourceManager at akka://flink/user/resourcemanager .
Starting RPC endpoint for org.apache.flink.runtime.dispatcher.StandaloneDispatcher at akka://flink/user/dispatcher .
Connecting to ResourceManager at hadoop2/192.168.51.22:8030
Recovered 0 containers from previous attempts ([]).
yarn.client.max-cached-nodemanagers-proxies : 0
ResourceManager akka.tcp://flink@hadoop4:36701/user/resourcemanager was granted leadership with fencing token 00000000000000000000000000000000
Starting the SlotManager.
Dispatcher akka.tcp://flink@hadoop4:36701/user/dispatcher was granted leadership with fencing token 00000000-0000-0000-0000-000000000000
Recovering all persisted jobs.
- Run Flink Job: 提交 Flink Job
# 查看 flink run 使用方法
$ flink run -h
Action "run" compiles and runs a program.
Syntax: run [OPTIONS] <jar-file> <arguments>
"run" action options:
-c,--class <classname> Class with the program entry point
("main" method or "getPlan()" method.
Only needed if the JAR file does not
specify the class in its manifest.
...
# 将 flink job 提交到 yarn session
# YARN Session 方式不能在提交 Flink Job 的时候动态改变 taskManager 的内存参数,因为这些只在第一次启动 YARN Session
# 的时候生效,并且多个 Job 生成的日志也比较混乱。
$ flink run \
--class com.rich.apps_streaming.BaseDataStreamingJob \
--yarnname "Base data streaming to hbase" \
--yarnapplicationId "application_1548409829387_0024" \
--parallelism 10 \
--yarnslots 3 \
--yarntaskManagerMemory 4096 \
--detached \
--yarnstreaming \
violent_search.jar
方式二: Run a single Flink job on YARN
Run a single flink job on YARN
# 如果不指定 YARN Session ApplicationId,则为 Flink Job 单独启动一个 YARN Session <推荐>
# 这种方式启动的任务更加灵活,方便管理、查看日志和调试
# 坏处是每次提交任务都会在 hdfs:///user/${START_USER}/.flink/ 下生成一个 application_xxxxxxxxxxxxx_xxxx,包含 flink 相关的依赖包(220M+)
$ flink run \
--class ${main_class} \
--yarnname "\"$yarn_name\"" \
--jobmanager yarn-cluster \
--yarnslots ${yarn_slots} \
--yarndetached \
--parallelism ${parallelism} \
-yD taskmanager.heap.size=${taskManager_heap_memory} \
${jar_path} \
"--topic=${topic}" \
"--groupId=${groupId}" \
"--htable=${htable}" \
"--columnFamily=${columnFamily}" \
"--windowSize=${windowSize}" \
"--walStrategy=${walStrategy}" \
> ${log_path} 2>&1 &
Step3: Flink Web Dashboard Web UI
在yarn-session.sh的启动日志中可以找到类似JobManager Web Interface: http://hadoop2:38710信息
Step4: 查看日志
对于 YARN-Session 提交的 Flink Job 的日志会输出在 YARN-Session Application
中。可以通过yarn logs -applicationId application_1548409829387_0024查看运行日志。也可以在 Flink Web Dashboard Web
UI http://hadoop2:38710/#/jobmanager/log中查看
对于 client 端输出的用户日志(非分布式任务中的日志),则在$FLINK_HOME/log/flink-${START_USER}-client-${START_HOST}.log
中查看。
Connectors
Apache Kafka Connector
// streaming
import org.apache.flink.streaming.api.scala._
// set up the streaming execution environment
val env = StreamExecutionEnvironment.getExecutionEnvironment
// batch
import org.apache.flink.api.scala._
// set up the batch execution environment
val env = ExecutionEnvironment.getExecutionEnvironment
Common
使用 yarn 时,减少资源申请应该调小 vcores(yarn.container.vcores), parallelism(parallelism.default:1) / slots( taskmanager.numberOfTaskSlots:1) 向上取整 = taskmanager 数量,每个 taskmanager 对应一个 jvm(类比 spark executor),每个 slot 一个 subtask 对应一个处理线程, 默认一个 slot 申请一个 yarn vcore,但是可以通过参数修改 TM 总的 vcores,而且 slots 数量是可以大于 vcores 数量的,比如 slots = 8, vcores = 4,也就是 JVM 对应了总的 4 个 vcore 的 cpu 资源(简单理解为4核8线程),vcore 是 yarn 的概念,每个 nodemanager 拥有的 vcore 资源上限都是配置死的,低优队列节点应该配的就是 40vcores/200g。flink_tm_vcores 实际上对应的应该就是 yarn.container.vcores
Flink Job 运行流程
// Flink Job 入口类,主要做两件事
// 1. 加载配置文件
// 2. 解析命令行
org.apache.flink.client.cli.CliFrontend
// 如果 cli 解析命令是 run,调用 run(...) -> executeProgram(...) 开始执行用户代码(我们写的 Flink 代码的 main)
val env = StreamExecutionEnvironment.getExecutionEnvironment
...
source.flatMap(...)
.returns(...)
.print()
// 执行到这一行时
env.execute("jobName")
// 1. 通过 List<Transformation<?>> transformations 构建 StreamGraph
// 2. 构建 JobGraph
// 3. Dispatcher.submitJob(JobGraph jobGraph...) 提交任务给 RM,申请资源...
// 4. Dispatcher.runJob(JobGraph jobGraph) 正式执行 Job
// 4.1. createJobManagerRunner(JobGraph jobGraph) 创建 JobManagerRunner、JobMaster,在创建 JobMaster 的时候构建了 ExecutionGraph
// The job master is responsible for the execution of a single JobGraph.
// start JobManagerRunner 同时也启动了 JobMaster 等一系列 service,然后就开始调度 executionGraph,execution.deploy task.start




