
SparkSQL Configurations
// 定义了 SparkSQL 的配置属性,SparkSQL 源码直接检索相关类即可
org.apache.spark.sql.internal.SQLConf
org.apache.spark.sql.internal.StaticSQLConf
SparkSQL Functions
SparkSQL 的函数类型结构如下:
- Built-in Functions
- Scalar Functions: 普通函数,作用于每行记录,对一行记录中的某些列进行计算,得出一个返回值作为一个新列, 表的记录数不改变。
- Aggregate-like Functions
- Aggregate Functions:
作用于一组记录,对这一组的数据的列进行聚合计算得出一个值,做聚合后结果表的总记录数通常会减少,例如
select max(age) from person group by sex - Window Functions: 窗口函数有别于聚合函数,聚合函数分组中的所有记录都会参与计算,最终每个分组得出一条结果记录。而窗口函数只是 限定一个窗口范围,窗口内的每一条记录都会进行计算,计算的过程会涉及到窗口内的其他数据参与计算,并且得出的最 终记录数不会减少。例如窗口内有5条记录,计算完的结果表依然还有5条记录。
- Aggregate Functions:
作用于一组记录,对这一组的数据的列进行聚合计算得出一个值,做聚合后结果表的总记录数通常会减少,例如
- UDFs (User-Defined Functions)
Aggregate-like Functions
Aggregate Functions
-- Examples
SELECT bool_and(col) AS result
FROM (
VALUES (false),
(false),
(NULL)
) AS tab(col);
Window Functions
SELECT
a,
b,
ROW_NUMBER() OVER (
PARTITION BY a
ORDER BY b
)
FROM
VALUES
('A1', 2),
('A1', 1),
('A2', 3),
('A1', 1) tab(a, b);
+---+---+---+
| A1| 1| 1|
| A1| 1| 2|
| A1| 2| 3|
| A2| 3| 1|
+---+---+---+
User Defined Functions
UDF
注册 SparkSQL UDF 有两种方式sparkSession.udf.register()和org.apache.spark.sql.function.udf()
object Test {
case class Cat(name: String, age: Integer, sex: String)
// 测试数据集
val testDataset = Seq(
Cat(null, null, null),
Cat("喵", 1, "母"),
Cat("嗷", 3, "公"),
Cat("喵", 2, "母"),
Cat("嗷", 1, "公")
)
def main(args: Array[String]): Unit = {
import org.apache.spark.sql.SparkSession
val sparkSession = SparkSession.builder().master("local").getOrCreate()
import sparkSession.implicits._
val catDF = sparkSession.sparkContext.makeRDD(testDataset).toDF
/**
* Spark 自带的`concat_ws(cols: Column*, sep: String)`函数,只要有一个Column
* 的值为`null`,`concat`的结果就会变为`null`。有时我们并不想这么做,那么我们实现
* 一个`myConcat`方法解决这个问题
* 注意:Spark UDF 不支持变长参数`cols: String*`,不过可以用下面的方式实现
*/
val myConcatFunc = (cols: Seq[Any], sep: String) => cols.filterNot(_ == null).mkString(sep)
// 使用 register() 方法
// 这种方式注册的 udf 方法,只能在`selectExpr`中可见,而对于`DataFrame API`是不可见的
sparkSession.udf.register("myConcat", myConcatFunc)
catDF.selectExpr("myConcat(array(name, age, sex), '-') as concat").show()
// 使用 udf()
// DataFrame API
import org.apache.spark.sql.functions.udf
import org.apache.spark.sql.functions.array
import org.apache.spark.sql.functions.lit
val myConcat = udf(myConcatFunc)
val seq = lit("-")
catDF.select(myConcat(array("name", "age", "sex"), seq).alias("concat")).show()
}
}
UDAF
Spark UDAF 实现
import com.google.gson.GsonBuilder
import org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{ArrayType, BooleanType, DataType, IntegerType, StringType, StructField, StructType}
class CollectSortList extends UserDefinedAggregateFunction {
/**
* 按照 rank 值对 elem 进行排序,默认升序
*
* @param rank
* @param elem
* @param asc
*/
case class ComparableRow(rank: Int, elem: String, asc: Boolean = true) extends Ordered[ComparableRow] {
def toJson: String = {
new GsonBuilder().create().toJson(this)
}
override def compare(that: ComparableRow): Int = {
if (asc)
this.rank - that.rank
else
that.rank - this.rank
}
}
object ComparableRow {
def parseRow(row: Row): ComparableRow = {
ComparableRow(row.getAs[Int](0),
row.getAs[String](1),
row.getAs[Boolean](2))
}
def parseJson(jsonStr: String): ComparableRow = {
new GsonBuilder().create().fromJson(jsonStr, classOf[ComparableRow])
}
}
// 指定函数具体输入参数的数据类型
override def inputSchema: StructType = StructType(Array(
StructField("rank", IntegerType),
StructField("elem", StringType),
StructField("asc", BooleanType)
))
// 指定缓冲区的数据类型,缓冲 MutableAggregationBuffer 是 Row 实现类
override def bufferSchema: StructType = StructType(StructField("buffer", ArrayType(StringType)) :: Nil)
// UDAF函数计算的结果类型
override def dataType: DataType = StringType
// 聚合函数是否是幂等的,即相同输入是否总是能得到相同输出
override def deterministic: Boolean = true
// 初始化缓冲区
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = Array[String]()
}
// 每当一条新的值进来,进行 Executor 级别的聚合计算
override def update(executorBuffer: MutableAggregationBuffer, input: Row): Unit = {
executorBuffer(0) = executorBuffer.getSeq[String](0) ++: Array(ComparableRow.parseRow(input).toJson)
}
// 最后在 Driver 节点进行 Local Reduce 完成后需要进行全局级别的 Merge 操作
override def merge(buffer: MutableAggregationBuffer, executorBuffer: Row): Unit = {
buffer(0) = buffer.getSeq[String](0) ++: executorBuffer.getSeq[String](0)
}
// 返回 UDAF 最后的计算结果
override def evaluate(buffer: Row): Any = {
buffer.getSeq[String](0).map(ComparableRow.parseJson).sorted.map(_.elem).mkString(",")
}
}
Hive UDAF 实现
import com.google.gson.GsonBuilder;
import lombok.Data;
import lombok.experimental.Accessors;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.parse.SemanticException;
import org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;
import org.apache.hadoop.hive.serde2.objectinspector.*;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfoUtils;
import java.util.Comparator;
import java.util.Objects;
/**
* 在 SparkSQL 中,first_value() 和 last_value() 是一种窗口函数,依赖 over 开窗的 order by,
* 但想要分组取第一个元素函数的时候就必须需要再写子查询进行过滤
* 在 FlinkSQL 中,first_value() 和 last_value() 是一种 UDAF 函数,函数中可以传递排序字段
* <p>
* 该函数就是在 SparkSQL 中实现对齐 FlinkSQL 的语义,降低 SQL 复杂度
* <p>
* Usage: sorted_first_value(value_col, order_col, [asc|desc])
* <p>
* ----------------------------------------------------
* id configuration_code zh_name price_version
* 1 API_Usage API调用小时 20230703
* 2 API_Usage API调用次数_小时结 20230412
* 3 API_Usage API调用小时 20230321
* 4 API_Usage API调用次数_小时结 20230302
* 5 API_Usage API调用次数按小时 20230117
* 6 API_Usage API调用次数按小时 20230117
* 7 API_Usage API调用次数按小时 20230117
* 8 API_Usage API调用小时 20221209
* 9 API_Usage API调用小时 20220930
* ----------------------------------------------------
* <p>
* -- 按价格版本取每个 configuration_code 的最新的中文名
* SELECT product,
* configuration_code,
* sorted_first_value(zh_name, price_version, 'desc') AS zh_name
* FROM eps_tech.dwd_trade_common_configuration_df
* WHERE date = '${date}'
* AND configuration_code = 'API_Usage'
* GROUP BY
* product,
* configuration_code;
*/
public class SortedFirstValue extends AbstractGenericUDAFResolver {
/**
* 校验多个入参的参数类型,并生成 GenericUDAFEvaluator
*
* @param parameterInfos
* @return
* @throws SemanticException
*/
@Override
public GenericUDAFEvaluator getEvaluator(TypeInfo[] parameterInfos) throws SemanticException {
// Type-checking goes here!
if (parameterInfos == null || parameterInfos.length != 3) {
throw new UDFArgumentLengthException("Exactly 3 params is expected");
}
// 解析第一个参数类型,最终需要取返回值的列
ObjectInspector valueColOI = TypeInfoUtils.getStandardJavaObjectInspectorFromTypeInfo(parameterInfos[0]);
if (valueColOI.getCategory() != ObjectInspector.Category.PRIMITIVE) {
throw new UDFArgumentTypeException(0, "Must be a primitive type");
}
// 解析第二个参数类型,排序字段
ObjectInspector orderColOI = TypeInfoUtils.getStandardJavaObjectInspectorFromTypeInfo(parameterInfos[1]);
if (orderColOI.getCategory() != ObjectInspector.Category.PRIMITIVE) {
throw new UDFArgumentTypeException(1, "Must be a primitive type");
}
// 解析第三个参数类型,ASC|DESC String 类型
ObjectInspector orderOI = TypeInfoUtils.getStandardJavaObjectInspectorFromTypeInfo(parameterInfos[2]);
if (orderColOI.getCategory() != ObjectInspector.Category.PRIMITIVE) {
throw new UDFArgumentTypeException(1, "Must be a primitive type");
}
PrimitiveObjectInspector orderPOI = (PrimitiveObjectInspector) orderOI;
if (orderPOI.getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.STRING) {
throw new UDFArgumentTypeException(2, "Must be a string type, but pass " + orderPOI.getPrimitiveCategory().name());
}
return new SortedFirstValueEvaluator();
}
/**
* UDAF 计算逻辑
*/
static class SortedFirstValueEvaluator extends GenericUDAFEvaluator {
private transient ObjectInspector internalMergeOI;
@Data
@Accessors(chain = true)
static class Row {
private Object value;
private Object orderBy;
private String order = "ASC";
public String toJson() {
return new GsonBuilder().create().toJson(this);
}
public static Row parseJson(String json) {
return new GsonBuilder().create().fromJson(json, Row.class);
}
}
/**
* 用于缓存中间结果的数据结构
*/
static class SortedFirstValueBuffer extends AbstractAggregationBuffer {
Object container;
public SortedFirstValueBuffer() {
container = null;
}
}
/**
* 实例化 Evaluator 类的时候调用,初始化各 Aggregation 阶段的 ObjectInspector
*
* @param mode PARTIAL1: 原始数据到部分聚合,调用 iterate 和 terminatePartial -> map 阶段
* PARTIAL2: 部分聚合到部分聚合,调用 merge 和 terminatePartial -> combine 阶段
* FINAL: 部分聚合到完全聚合,调用 merge 和 terminate -> reduce 阶段
* COMPLETE: 从原始数据直接到完全聚合,调用 iterate 和 terminate -> map 完直接聚合出最终结果,没有 combine 和 reduce 阶段
* @param parameters UDAF 入参类型检查
* @return
* @throws HiveException
*/
@Override
public ObjectInspector init(Mode mode, ObjectInspector[] parameters) throws HiveException {
super.init(mode, parameters);
switch (mode) {
case PARTIAL1:
case PARTIAL2:
case FINAL:
case COMPLETE:
default:
// 每个阶段的 outputOI 都是 String
return PrimitiveObjectInspectorFactory.javaStringObjectInspector;
}
}
/**
* 获取一个新的存放中间结果的缓存
*
* @return
* @throws HiveException
*/
@Override
public AbstractAggregationBuffer getNewAggregationBuffer() throws HiveException {
return new SortedFirstValueBuffer();
}
/**
* Reset the aggregation. This is useful if we want to reuse the same aggregation.
*
* @param agg
* @throws HiveException
*/
@Override
public void reset(AggregationBuffer agg) throws HiveException {
((SortedFirstValueBuffer) agg).container = null;
}
/**
* 对应 map,将处理的一行数据写入 AggregationBuffer
*
* @param agg
* @param parameters
* @throws HiveException
*/
@Override
public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException {
Object value = parameters[0];
Object orderBy = parameters[1];
// parameters[2] 是 org.apache.hadoop.io.Text
String order = parameters[2].toString();
compareWithBuffer(value, orderBy, order, (SortedFirstValueBuffer) agg);
}
/**
* 返回部分聚合数据 AggregationBuffer 中的持久化对象。
* <p>
* Note: 调用这个方法时,说明已经是 map 或者 combine 的结束了,必须将数据持久化以后交给 reduce 进行处理。
* 持久化类型只支持 Java 原始数据类型及其封装类型、Hadoop Writable 类型、List、Map,不能返回自定义的类,
* 即使实现了 Serializable 也不行,否则会出现问题或者错误的结果。
*
* @param agg
* @return
* @throws HiveException
*/
@Override
public Object terminatePartial(AggregationBuffer agg) throws HiveException {
return ((SortedFirstValueBuffer) agg).container;
}
/**
* 将 terminatePartial 返回的部分聚合数据进行合并,partial 是 List 类型
*
* @param agg
* @param partial
* @throws HiveException
*/
@Override
public void merge(AggregationBuffer agg, Object partial) throws HiveException {
SortedFirstValueBuffer firstValueBuffer = (SortedFirstValueBuffer) agg;
Row partialRow = Row.parseJson(partial.toString());
compareWithBuffer(partialRow.value, partialRow.orderBy, partialRow.order, firstValueBuffer);
}
/**
* 结束,生成最终结果
*
* @param agg
* @return
* @throws HiveException
*/
@Override
public Object terminate(AggregationBuffer agg) throws HiveException {
return Row.parseJson(((SortedFirstValueBuffer) agg).container.toString()).value;
}
Comparator<Object> objectComparator = (o1, o2) -> {
if (o1 == null && o2 == null) return 0;
if (o1 == null) return -1; // NULL 算无限小
if (o2 == null) return 1;
if (o1 instanceof Number) {
return Double.compare(((Number) o1).doubleValue(), ((Number) o2).doubleValue());
} else {
return o1.toString().compareTo(o2.toString());
}
};
/**
* @param value sorted_first_value 返回值的列
* @param orderBy sorted_first_value 用于排序的列
* @param order asc|desc 按指定列升序或降序后取 first_value
* @param sortedFirstValueBuffer buffer 缓存
*/
private void compareWithBuffer(Object value, Object orderBy, String order, SortedFirstValueBuffer sortedFirstValueBuffer) {
Row row = new Row()
.setValue(value)
.setOrderBy(orderBy)
.setOrder(order);
Object pCopy = ObjectInspectorUtils.copyToStandardObject(row.toJson(),
PrimitiveObjectInspectorFactory.javaStringObjectInspector);
if (sortedFirstValueBuffer.container == null) {
sortedFirstValueBuffer.container = pCopy;
} else {
Object elem = sortedFirstValueBuffer.container;
Row bufferedRow = Row.parseJson(elem.toString());
// compare > 0,代表当前值比 buffer 的值大
int compare = Objects.compare(orderBy, bufferedRow.getOrderBy(), objectComparator);
// 升序的 FirstValue 是取最小值,如果小于 buffer 就置换,反之是取最大值,如果大大于 buffer 就置换
if (("ASC".equalsIgnoreCase(order) ? -compare : compare) > 0) {
sortedFirstValueBuffer.container = pCopy;
}
}
}
}
}
SparkSQL 调优
Tuning Tips
- JOIN ON 条件中避免使用 OR 条件,在 MySQL 中会导致索引失效,在 SparkSQL 中会导致某些优化规则不生效,导致执行时间变长,可以改成两个查询再 UNION(去重) / UNION ALL + GROUP BY 去重
Spark SQL 执行顺序
# SQL 的语法如下
(8) SELECT
(1) FROM [left_table]
(3) <join_type> JOIN <right_table>
(2) ON <join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_field_list>
(6) WITH <cube|roll_up>
(7) HAVING <having_condition>
(10) ORDER BY <order_by_field_list>
# 按执行顺序排序后
(1) FROM [left_table]
(2) ON <join_condition>
(3) <join_type> JOIN <right_table>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_field_list>
(6) WITH <cube|roll_up>
(7) HAVING <having_condition>
(8) SELECT (9) DISTINCT <select_field_list>
(10) ORDER BY <order_by_field_list>
SparkSQL 逻辑执行计划优化
在了解 SparkSQL 的优化策略时,需要先搞清楚几个核心概念
- Logical Plan: 逻辑执行计划。SparkSQL 会先解析你写的实际 SQL,然后出一版逻辑计划,实际上是描述你想要怎么操作、处理数据,描述的是你数据处理逻辑的意图。
- Spark Catalyst Optimizer: SparkSQL 优化器。对于你写的这套 SQL 逻辑,有可能在最终数据结果逻辑等价的前提下,不是相对更优的处理方式,Spark Catalyst Optimizer 会对逻辑执行计划进行优化,比如谓词下推(Predicate Pushdown),投影剪裁(Projection Pruning)等,给数据处理逻辑瘦身,让数据处理更快。然后根据
SparkStrategies.JoinSelection确定 JOIN 的最终执行策略,最终生成物理执行计划。 - Physical Plan: 物理执行计划。其实就是最终要实际执行的具体方式了,也确定了物理执行的策略,比如 JOIN 是排序合并连接(SortMergeJoin)还是广播哈希连接(BroadcastHashJoin),在具体节点上的任务划分情况,分区(partitions)的数量和位置,最终生成一系列的 Stage 和 Task 来实际执行这些操作
可以通过 EXPLAIN 查看 SQL 的相关执行计划,也可以 可以通过 Spark APP WebUI 通过 SQL 页查看可视化的物理执行计划
其中涉及到了一些关键的步骤,分别介绍一下
- Scan parquet: 首先要读取 Hive 表,对应 From,将 Hive 表实际存储数据的存储文件加载进来
- WholeStageCodegen[x]: 在没有 WholeStageCodegen 之前,Spark 的每个步骤(比如过滤、聚合等) 都是独立执行的,每一步都会生成中间的数据。有了 WholeStageCodegen 将多个步骤合并在一起执行,减少了中 间数据的生成等步骤
- ColumnarToRow: 通常,SparkSQL 为了更好的性能,会采用列式存储格式,也就是把同一列的数据存储在一起, 这样就能针对性地压缩和快速处理相似数据,大大提高处理的效率和速度。但是在数据查询的时候,有些操作是需要整 行数据的,这时候就需要将列存储转成行
- Filter: 数据过滤,根据条件对数据进行过滤,横向裁剪数据
- Project: 翻译过来是「投影」,负责对数据进行转换,只筛选那些需要关心的字段投影到最终的结果集中,竖向裁剪数据
- Sort: 按指定条件对数据集进行排序
- Aggregate: 按指定的条件对数据进行聚合操作
- Exchange: 数据交换,保证数据在分布式执行节点间的传输没有问题,将数据从 RDD 转化为 DataFrame/Dataset
的内部格式。通常发生在需要进行 Shuffle 的地方,比如 GROUP BY 或者 JOIN 操作之前
- ShuffleExchange: 将不同分区的数据 ShuffleRead 进来,然后对数据进行重分区
- BroadcastExchange: 将小数据集分发到各个执行节点上
- AQEShuffleRead: Adaptive Query Execution Shuffle Read,自适应查询执行的 Shuffle 读取优化,当 Spark 在运行时发现数据倾斜严重,某个执行器上的任务拖了后腿时,会动态地调整 Shuffle 读取的计划,比如合并一 些读取减少数据倾斜,或者在执行节点间更均匀的分配任务
- Join: 两个结果数据集的数据关联拼接操作
提到 SparkSQL 的优化逻辑,不得不提几个关键的技术,也是 SparkSQL 对计算任务核心的优化方式
- RBO(Rule-based Optimization): 基于规则的优化。最早期的时候,为了减少计算资源和存储的浪费,加快任务计
算速度,SparkSQL 在已知的一些固定场景会基于一系列对应的静态规则去执行优化,这些优化不需要统计信息,在逻辑计
划阶段就尽可能对查询进行优化。常见地优化规则比如
- 常量折叠(Constant folding): 是编译原理当中的概念,在编译过程就将一些常量表达式计算好,而不用每次都
计算,比如
select 60 * 5 * period会被优化成select 300 * period - 谓词下推(Predicate Pushdown): 其实就是将 Filter 提前,尽早过滤数据,在更贴近数据集读取的环节就把 没用的数据行过滤掉,主要是横向裁剪数据。
- 字段裁剪(Column Pruning): 有些查询字段(比如子查询中的字段,最终其实没有被引用)其实不会最终计算,
加载这些字段没任何作用白白浪费 IO 资源,就会将这些字段筛掉,主要是竖向裁剪数据。
select name from ( select * from student ) -- 会优化成 select * from ( select name from student ) - 布尔表达式简化: 和离散数学一样,Bool 计算很多情况下都可以进行等价转换,会转换成最简单的执行方式
- 常量折叠(Constant folding): 是编译原理当中的概念,在编译过程就将一些常量表达式计算好,而不用每次都
计算,比如
- CBO(Cost-based Optimization): 基于成本的优化。RBO 在一些固定模式下是有效的,但是在实际大数据量场景下, 实际的数据分布不同可能会影响实际的执行效果。而 CBO 就是通过一些静态的数据统计数据(比如 SparkCatalog),权衡 IO、CPU、网络成本来决定执行计划什么样更优。
- AQE(Adaptive Query Execute): CBO 的统计数据因为是静态统计数据,有时候数据并不准确,比如 Hive 元数据 的数据有时和实际对应的存储文件中的数据完全不一样,这样就有可能选择执行计划导致优化效果就大大折扣。于是就有聪明 人提出了 AQE,这个技术基于上个 Stage 执行完成后的实时统计数据,动态调整执行计划。
相关文档
SparkSQL Join
SQL 的所有操作,可以分为简单操作(如过滤WHERE、限制次数LIMIT等)和聚合操作(GROUP BY、JOIN等),
其中 JOIN 操作是最复杂、代价最大的操作类型。
Join Operations
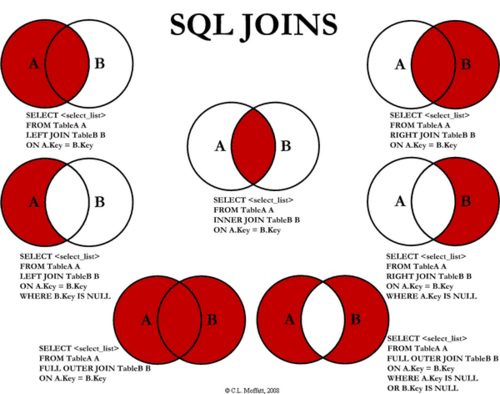
Join 策略与原理
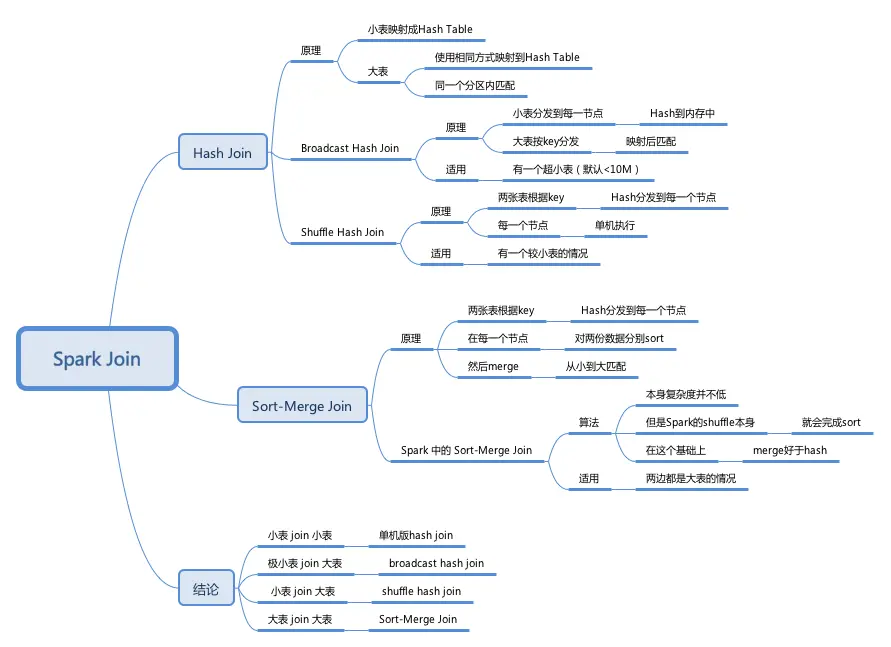
当前 SparkSQL 支持 5 种 JOIN 策略,其中前两者归根到底都属于Hash Join,只不过在Hash Join之前需要先 Shuffle 还是先 Broadcast。
Broadcast Hash JoinShuffle Hash JoinShuffle Sort Merge JoinCartesian Product Join: 笛卡尔乘积连接Broadcast Nested Loop Join: 广播嵌套循环连接
影响 JOIN 操作效率的三大因素
Join type is equi-join or not: 连接类型是否为等值连接。等值连接是一个在连接条件中只包含 equals 比较的连接,而非等值连接包含除 equals 以外的任何比较,例如<,>,>=,<=。由于非等值连接需要对不确定 的值的范围进行比较,因而嵌套循环是必须的。因此,对于非等值连接,SparkSQL 只支持Broadcast Nested Loop Join(广播嵌套循环连接)和Cartesian Product Join(笛卡尔乘积连接)。 而所有连接运算符都支持等值连接。SparkSQL 定义了ExtractEquiJoinKeys模式,JoinSelection(规划 连接操作的核心对象)使用它来检查逻辑连接计划是否是等值连接。如果是等值连接,连接的元素将从逻辑计划中提取出 来,包括连接类型、左键、右键、连接条件、左连接关系、右连接关系和连接提示。这些元素的信息构成了接下来连接规 划过程的基础。Join strategy hint: 连接策略提示。Size of Join relations: 连接数据集的大小。
SparkSQL Join 谓词下推 PushPredicateThroughJoin
SparkSQL DataFrame Common Operators
DataFrame 是一种泛型类型为 Row 的 Dataset,即
type DataFrame = Dataset[Row]
SQL 实践
列转行
列转行主要用到的是 TableFunction,用户也可以定义自己的 UDTF(User Defined Table Function) 操作
Explode Map
SELECT account_id AS volc_account_id,
product_code AS pm_product_code,
MIN(`created_time`) AS stage_time
FROM (
SELECT account_id,
temp.product_code,
temp.tag_value,
row_number() OVER (
PARTITION BY
account_id,
temp.product_code,
temp.tag_value
ORDER BY
tag.created_time DESC
) AS rn,
tag.created_time
FROM xxx.dim_account_tag_df AS tag
-- OUTER 类似与 OUTER JOIN,会在 EXPLODE() 函数中的参数是 NULL 或者空的时候保留一条数据,避免整条数据丢失
LATERAL VIEW OUTER
EXPLODE(json_to_map(tag.tag_value)) temp AS product_code,
tag_value
WHERE tag.date = '${date}'
AND tag.tag_key = 'xxx'
)
WHERE rn = 1
AND tag_value = 1
GROUP BY
account_id,
product_code
使用 VALUES() 构造子查询数据表
INSERT OVERWRITE TABLE db.table PARTITION (date = '${date}')
SELECT id,
sla_condition_str,
sla_id,
lower_condition,
lower_target,
upper_condition,
upper_target,
compensate_rate,
version,
created_time,
updated_time,
status,
is_deleted
FROM db.tablename
WHERE date = '${date}'
UNION
VALUES
(
1000001, -- id
'[0.99,1.0]', -- condition_str
1000001, -- sla_id
'', -- lower_condition
'', --lower_target
'', -- upper_condition
'', -- upper_target
'', -- compensate_rate
NULL, -- version
NULL, -- created_time
NULL, -- updated_time
0,
'0' --is_deleted
)
判断 NULL 值是否相等
SparkSQL 中 <=> 和 = 号的区别,在 where 或者 on 条件中比较重要,当数据都为NULL时使用=会导致关联结果为NULL而没有成功关联造成数据丢失
SELECT a <=> b, -- true
a = b -- NULL
FROM (
SELECT NULL AS a,
NULL AS b
)
计算错误率的补点逻辑
WITH
-- TLS Kafka 不保证数据 Exactly once,这里完全去重是为了做类似幂等的处理
distinct_log AS(
SELECT DISTINCT *
FROM eps_volc_sla.ods_sla_raw_http_log_from_tls_hourly
WHERE date = '${date}'
AND hour = '${hour}'
AND sli_key IN (
-- TOS
'tos_http_request_success_rate',
-- TLS
'tls_request_err_rate'
)
),
-- 补点逻辑,小时级任务按小时补
template AS (
SELECT account_id,
extra,
sli_key,
CAST((UNIX_TIMESTAMP('${date}${hour}', 'yyyyMMddHH') + i * (period * 60)) AS BIGINT) AS sli_time
FROM (
SELECT account_id,
extra,
sli_key,
period
FROM distinct_log
GROUP BY
account_id,
extra,
sli_key,
period
)
LATERAL VIEW
-- 例如: 一分钟一个点(period=1),一个小时就需要构造 60 个点 => SPLIT(SPACE(59), ' ')
-- TOS 和 TLS 现在都是按照 1 小时补点
POSEXPLODE(SPLIT(SPACE(60 / period - 1), ' ')) seq AS i,
x
),
-- 指标计算过程
indicator AS (
SELECT (`time` - `time` % (60 * period)) AS sli_time,
UNIX_TIMESTAMP() AS event_time,
sli_key,
extra,
account_id,
CASE WHEN sli_key = 'tos_http_request_success_rate' THEN
-- TOS 请求成功率
1 - CAST(COUNT(IF(val >= 500 AND val < 600, 1, NULL)) AS DOUBLE) / COUNT(val)
WHEN sli_key IN ('tls_request_err_rate') THEN
-- TLS 请求错误率
CAST(COUNT(IF(val >= 500 AND val < 600, 1, NULL)) AS DOUBLE) / COUNT(val)
END AS sli_value
FROM distinct_log
GROUP BY
account_id,
extra,
sli_key,
period,
(`time` - `time` % (60 * period))
)
INSERT OVERWRITE TABLE eps_volc_sla.dwd_sli_event_log_tls_hourly PARTITION (date = '${date}', hour = '${hour}')
SELECT template.sli_time,
indicator.event_time,
template.sli_key,
template.extra,
template.account_id AS vol_account_id,
CASE WHEN template.sli_key = 'tos_http_request_success_rate' THEN
-- TOS 成功率,默认成功率为 1
COALESCE(indicator.sli_value, 1)
WHEN template.sli_key IN ('tls_request_err_rate') THEN
-- TLS 错误率,默认错误率为 0
COALESCE(indicator.sli_value, 0)
END AS sli_value
FROM template
LEFT JOIN
indicator
ON template.account_id = indicator.account_id
AND template.extra = indicator.extra
AND template.sli_key = indicator.sli_key
AND template.sli_time = indicator.sli_time
处理数据倾斜
数据倾斜定位
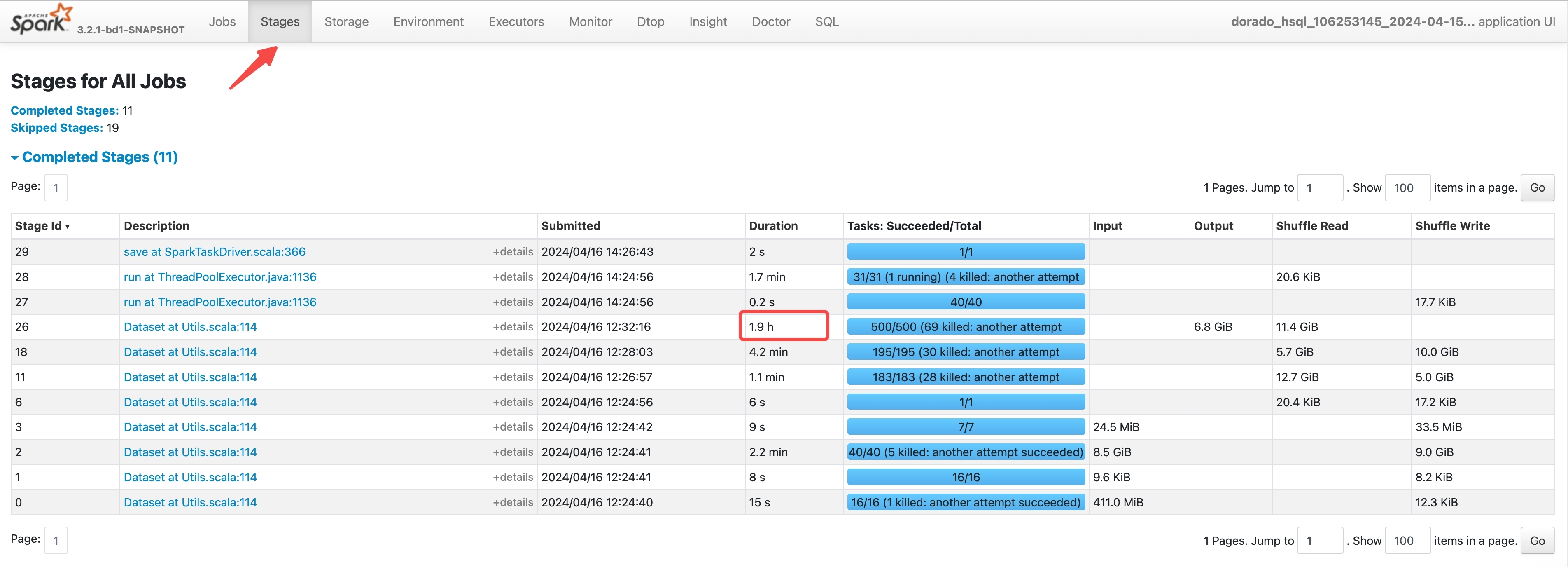
首先找到耗时比较长的 Stage,然后点击图中的 Description 进入查看详细的 Task 运行统计信息
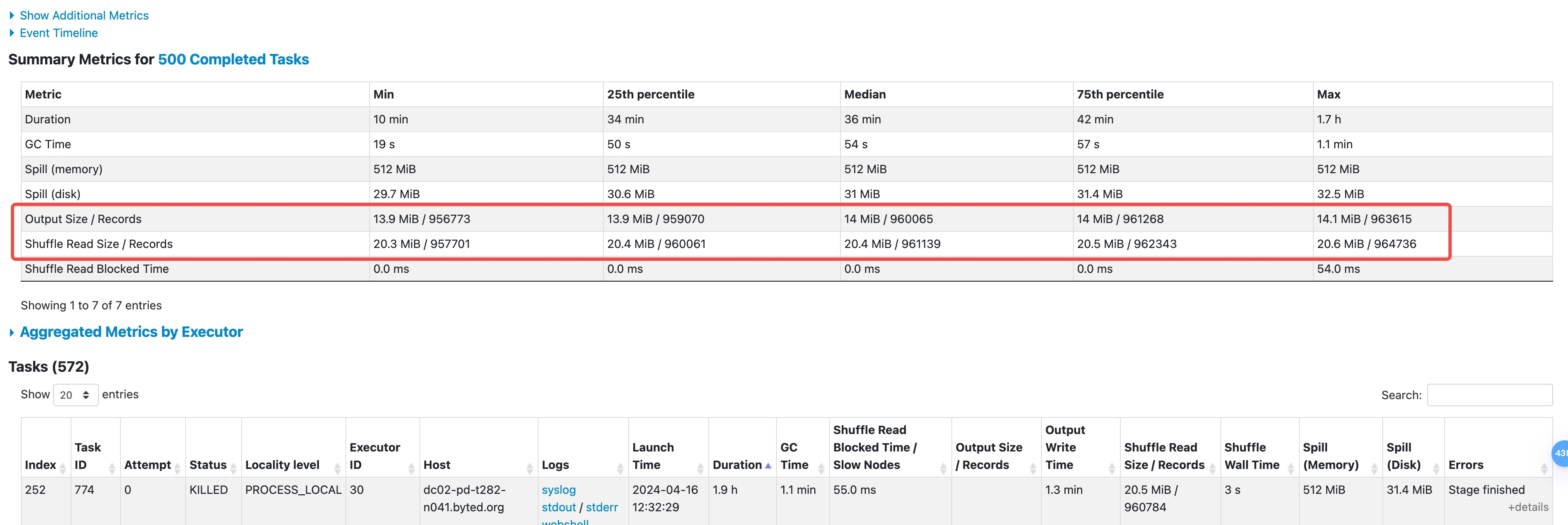
主要看 Shuffle Read Size/Records,如果各个分位的数据相差太多说明数据上出现了倾斜,如果相差不多说明没有倾斜
解决数据倾斜
避免数据 Shuffle
利用 Broadcast Join 避免数据在计算节点之间进行 Shuffle,这样数据就不会倾斜(取决于 Map 阶段的数据分布), 但 Broadcast Join 只适合小表,先把小表数据加载到 Driver 内存,然后广播到各个 Executor 节点上,中间不 存在数据 Shuffle 过程
-- 方式1: 调大 Broadcast Join 表的阈值
SET spark.sql.autoBroadcastJoinThreshold = 41943040; -- 40MB
-- 方式2: 使用 hint 强制广播 t1 表和 t2 表
SELECT
/*+ BROADCAST(t1), BROADCAST(t2) */
*
FROM t
LEFT JOIN t1 ON ...
LEFT JOIN t2 ON ...
通过 SQL 页面查看执行计划是否是 Broadcast Join
单独处理大 Key 数据
将大 Key 过滤出来单独处理,在 Union 上其他数据的结果数据,偏一次性的临时方案,不通用,比如新增数据可能会产 生新的大 Key
随机后缀打散倾斜 KEY
将倾斜 Key 打散,小表数据成倍膨胀扩容,让数据分布均匀,交由多个 Task 做 shuffle 操作,对业务侵入比较少, 但被 JOIN 的表也需要添加随机前缀,数据放大了,增加资源消耗
-- 假设某个大客户 account_id = 100001 下有 1 亿条收入明细,现在要关联客户信息维表扩充一些客户属性
WITH dim_account_bucket AS(
SELECT account_id,
bucket_num,
bucket_no
FROM (
SELECT account_id, -- 账号 ID
(COUNT(1) / 1000000) AS bucket_num -- 根据账号拥有的收入明细数量决定要分桶的数据量,这里平均每 100 万条一个 bucket
-- 倾斜的收入明细表
FROM skewed_income_detail
GROUP BY
account_id
)
LATERAL VIEW
-- SPACE(bucket_num) 构造由 bucket_num 个空格拼接成的字符串
-- SPLIT(SPACE(bucket_num), ' ') 将 bucket_num 个字符串按照空格拆分,生成一个长度为 bucket_num + 1,值为空字符串的数组
-- POSEXPLODE(...) seq AS bucket_no, x; 将数组炸开并获取数组下标,其中 bucket_no 为从 0 开始的数组下标,x 为元素值
POSEXPLODE(SPLIT(SPACE(bucket_num), ' ')) seq AS bucket_no,
x
),
-- 将账号维表进行膨胀处理(扩充n倍)
explode_account AS (
SELECT account.*,
dim_account_bucket.bucket_num,
dim_account_bucket.bucket_no
FROM account
LEFT JOIN
dim_account_bucket
ON account.id = dim_account_bucket.account_id
)
-- 将收入明细与膨胀后的账号维表进行关联计算
SELECT *
FROM skewed_income_detail
LEFT JOIN
explode_account
-- JOIN 的关联 KEY 从单一的 account_id 被打散成了,
-- account_id + MOD(skewed_income_detail.id, explode_account.bucket_num)
-- 这样一个 account_id 的收入明细就可以被拆分到多个节点上去并发执行了
ON skewed_income_detail.account_id = explode_account.account_id
-- Suffle Key 变成了 account_id + MOD(skewed_income_detail.id, explode_account.bucket_num),
-- 相当于把原来的倾斜 Key account_id 打散了
AND MOD(skewed_income_detail.id, explode_account.bucket_num) = explode_account.bucket_no
Spark AQE SkewedJoin
Spark Adaptive Query Execution 简称 Spark AQE,是 Spark 3.0+ 的新特性,AQE 的总体思想是动态优化和修改 Stage 的物理执行计划。利用上游已经执行结束的 Stage 的统计信息(主要是数据量和记录数),来优化下游 Stage 的物理 执行计划
-- 相关参数
-- 开启 SkewedJoin 检测
SET spark.sql.adaptive.skewedJoin.enabled=true;
SET spark.sql.adaptive.skewedJoinWithAgg.enabled=true;
SET spark.sql.adaptive.multipleSkewedJoin.enabled=true;
SET spark.sql.adaptive.allowBroadcastExchange.enabled=true;
SET spark.sql.adaptive.forceOptimizeSkewedJoin=true;
SET spark.sql.adaptive.multipleSkewedJoinWithAggOrWin.enabled=true;
SET spark.sql.adaptive.skewedJoinSupportUnion.enabled=true;
SET spark.sql.adaptive.skewShuffleHashJoin.enabled=true;
Note:
spark.shuffle.highlyCompressedMapStatusThreshold(默认5000)需要大于等于spark.sql.adaptive.maxNumPostShufflePartitions(默认2000,设置相等即可), 否则 AQE SkewedJoin 可能无法生效。spark.sql.adaptive.maxNumPostShufflePartitions设置过高(例如超过2w), 会增加 Driver CPU 的压力,可能出现 Executor 心跳注册超时,建议同时提高 Driver 的内存 CPU 资源。- 倾斜非常严重,被拆分后倾斜仍然很严重,可能是 Shuffle 分布统计精度太低,需要降低
spark.shuffle.accurateBlockThreshold,默认为100M,可按需降低(例如改成4M或1M), 但需要额外注意的是,降低该参数会增加 Driver 内存的压力(统计数据更加精确),为防止出现 Driver OOM 等问题,建议同时提高 Driver 的内存和 CPU 资源。
SkewedJoin 优化原理
A 表 INNER JOIN B 表,并且 A 表中第 0 个 Partition(PA 0)是一个倾斜的 Partition,正常情况下,PA 0
会和 B 表的第 0 个 Partition(PB 0) 进行 JOIN,由于此时PA 0倾斜,Task 0 就会成为长尾 Task
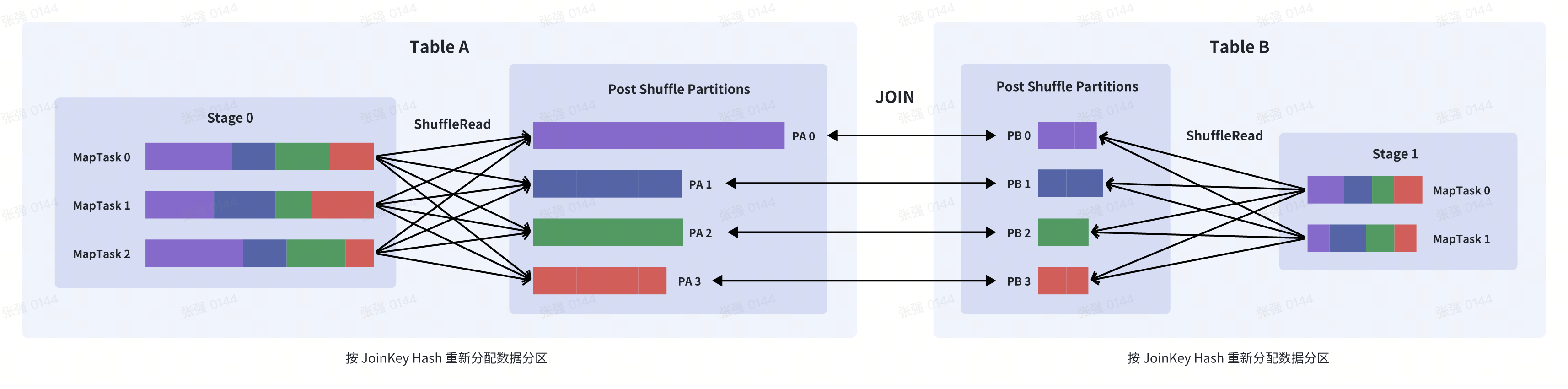
SparkAQE 在执行 A JOIN B 之前,会动态收集上游 Stage 执行结果的统计信息,发现PA 0的数据量明显超过平均值, 即判断 A JOIN B 会发生数据倾斜,且倾斜分区为PA 0
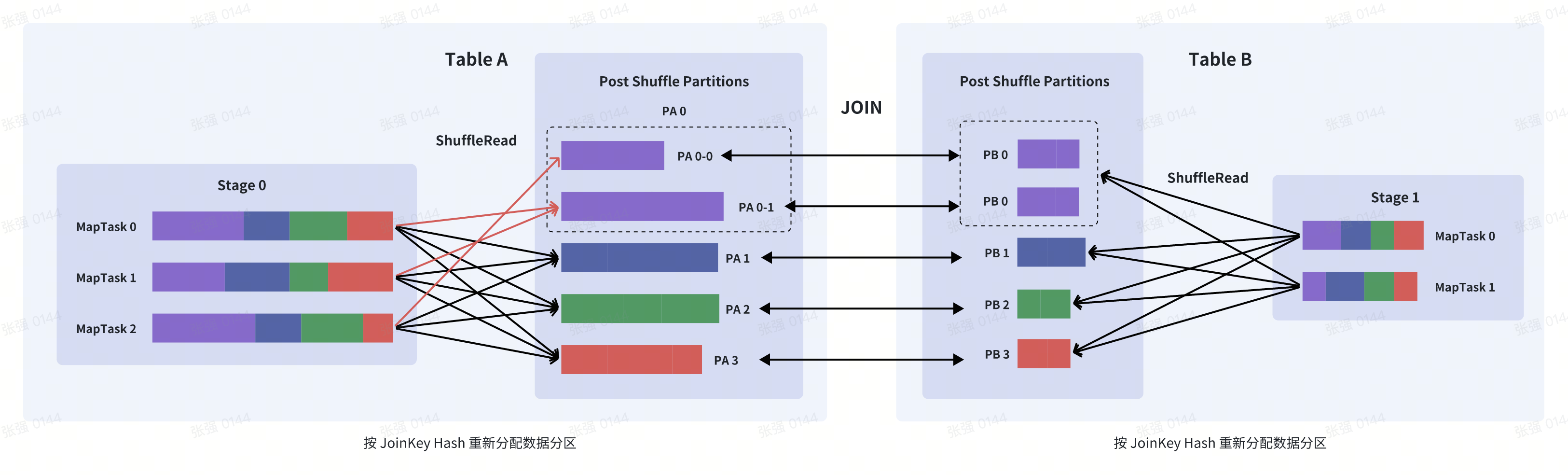
这时 SparkAQE 会将PA 0的数据拆成 2 份,并使用 2 个 Task 去处理该 Partition,每个 Task 只读取若干个
MapTask 的 Shuffle 输出文件,如下图所示,PA 0-0 只会读取Stage0#MapTask0中属于PA 0的数据,而
PA 0-1读取了Stage0#MapTask1和Stage0#MapTask2中属于PA 0的数据
这 2 个 Task 然后都分别读取 B 表PB 0的数据做 JOIN,最后再将结果合并。也就是说PA 0 INNER JOIN PB 0
和 (PA 0-0 INNER JOIN PB 0) UNION ALL (PA 0 INNER JOIN PB 0) 在语义上是等价的
SkewedJoin 的局限
在上面的处理中,B 表的PB 0被读取了 2 次,虽然会增加一定的额外成本,但是通过 2 个任务并行处理倾斜数据带来的
收益远大于这些成本,能有效的解决数据倾斜问题
但 SparkAQE 对于不同的 JOIN 类型,能够处理的倾斜侧是不一样的,例如,A INNER JOIN B,我们可以处理 A 和 B 两侧的倾斜键,但是对于 LEFT/RIGHT JOIN,另一侧的倾斜是无法被处理的,比如对于 A RIGHT JOIN B 来说,左侧的 数据倾斜是无法被处理的
首先 RIGHT JOIN 需要保留右侧的全部数据,如果我们拆分 A 的倾斜分区PA 0, 每一个拆分后的 Task 会读取PB 0
以及PA 0-0(PA 0的部分数据) 的数据,拆分后就无法确定PB 0的某条数据是否一定在PA n中没有匹配记录(没
有匹配记录就需要补 NULL 值),比如PA 0-0和PB 0并没有匹配记录,导致关联结果左侧表数据全部补了 NULL 值,
但可能在PA 0-1匹配上了记录,又生成了关联结果,最终合并的时候数据就出现了问题,也就是说PA 0RIGHT JOIN
PB 0和 (PA 0-0RIGHT JOINPB 0) UNION ALL (PA 0RIGHT JOIN PB 0) 在语义上是不等价的
除此之外,SparkAQE 目前只支持 ShuffleRead 的倾斜优化,不支持 ShuffleWrite 的倾斜优化
社区 AQE 与数据倾斜优化
- Adaptive Query Execution (SPARK-31412)
- Skew join optimization (SPARK-29544)
- Improve the splitting of skewed partitions(SPARK-30918)
- make skew join split skewed partitions more evenly(SPARK-31070)
- OptimizeSkewedJoin support ShuffledHashJoinExec(SPARK-35214)
- Optimize skew join before coalescing shuffle partitions(SPARK-35447)
- Simplify OptimizeSkewedJoin(SPARK-35541)




