
变量
Scala中包含两种类型的变量:可变变量和不可变变量。分别用var和val定义。
可变变量就和java中的对象变量一样,变量被赋值之后仍然随着程序的运行而改变。
var str = "abc"
str = "def"
而不可变变量就相当于java中被final修饰的变量,一旦被赋值就不可以再修改。
val str = "abc"
// 不能再修改它的值!会报错
str = "def"
编译报错:
Error:(43, 7) reassignment to val
sum = "edf"
需要特别注意的是:Scala中的变量在定义的时候必须初始化赋值。无论是可变还是不可变变量
可变变量在初始化时可以使用占位符_,会给不同类型的对象赋上默认的初始值
var str: String = _
str: String = null
var in: Int = _
in: Int = 0
var flo: Float = _
flo: Float = 0.0
var c: Char = _
c: Char = ?
lazy 变量
Scala中的不可变变量可以用lazy关键字修饰,这样变量只有在真正被使用的时候才会赋值。
// 普通变量,定义时就已经赋值
val test1 = "test1"
test1: String = test1
// lazy修饰,定义时没有被赋值
lazy val test2 = "test2"
test2: String = <lazy>
// 使用时会被赋值
test2
res0: String = test2
需要注意的是:lazy只能修饰val类型的变量,不能用于var,主要是为了避免程序运行中变量还未使用便被重新赋值。
数据类型
Scala万物皆对象,包括数字、函数,与java存在很大的不同。下面介绍一些重要的类。
Scala中Any类是所有类的超类。它有两个子类AnyRef和AnyVal。其中AnyRef是所有引用类型的基类,AnyVal是直接类型(例如Int、Double)的基类。
Any是一个抽象类,它有如下方法:!=()、==()、asInstanceOf()、equals()、hashCode()、isInstanceOf()和toString()。AnyVal没有更多的方法了。AnyRef
则包含了Java的Object类的一些方法,比如notify()、wait()和finalize()。
AnyRef是可以直接当做java的Object来用的。对于Any和AnyVal,只有在编译的时候,Scala才会将它们视为Object。换句话说,在编译阶段Any和AnyVal会被类型擦除为Object。
Nothing是所有对象的子类,是一个类。null是所有对象的默认值,是一个特殊的独立的概念(null不是对象),是一个特殊的唯一的值。
基本数据类型
Scala的基本数据类型和基本Java一致,但是首字母必须大写,因为Scala中的所有值类型都是对象:Byte、Short、Int、Long、Float、Double、Char、Boolean
val a: Int = 1;
// 可以直接使用对象的方法
println(a.toString)
// 也可以这样~
println(1.toString)
String类型
Scala中定义的String类型实际上就是java.lang.String类型,因此可以调用java中String类型的所有方法
除此之外,也可以调用以下方法。这些方法在java中是不存在的,实际上在遇到reverse、map、drop、slice方法调用时编译器会自动进行隐式转换,将String类型对象转换成StringOps类型对象。
val s = "hello"
// 反转符
println(s.reverse)
// 丢弃字符 (丢弃前n个字符)
println(s.drop(3))
// 获取一定范围内的子串, 左开右闭[1,4)
println(s.slice(1, 4))
对于包含需要转义的字符的字符串,除了添加转移符\外,还可以使用三个双引号将字符串包裹起来。这样就可以原样输出字符串中的内容。
println("""hello world \n""")
// 原样输出:hello world \n
但是在使用split()或者replace()等函数内部使用正则表达式的方法时需要额外注意,需要添加额外的转义符。详细原因请参考我的这篇文章:特殊字符处理异常
对象比较运算
Scala中的对象比较和java中的对象比较不同,Scala是基于内容比较,而java是依据对象引用比较(即对象的物理内存地址是否一样)。基于内容比较是Scala的重要特点之一
val s1 = new String("abc");
val s2 = new String("abc");
// 结果是true
println(s1 == s2)
// 在Scala中String的equals方法和==相同
println(s1.equals(s2))
// 如果想比较内存地址(引用)是否为是相同的,可以使用eq方法。返回false
println(s1.eq(s2))
元组类型
元组是Scala的一种特殊类型,它是不同类型值的聚集,将不同类型的值放在一个变量中保存。
// 一个三元组
val tuple = ("hello", "world", 1)
// 访问元组
println(tuple._1 + "," + tuple._2 + "," + tuple._3)
// 使用时还可以提取元组的内容到变量中
val (a, b, c) = tuple
// 访问元组
println(a + "," + b)
在函数中表示一个参数是二元组类型:
def tupleString2Int(tuple2: (String, String)): (Int, Int) = (tuple2._1.toInt, tuple2._2.toInt)
tupleString2Int(("1", "2"))
符号类型
符号类型主要起标识作用,常用于模式匹配、内容判断中。符号类型(Symbol) 定义时需要'(单引号)符号
// 定义一个符号类型的变量s,变量s会被默认识别为Symbol类型
val s = 'start
// 显示声明符号类型
val s_ : Symbol = 'start
// 符号类型主要起标识作用,常用与模式匹配、内容判断中
// for example
if (s == s_) println(true) // 使用 == 来比较变量时,比较的是变量的内容而非引用
else println(false)
// 直接输出符号类型的变量会按原样输出
println("s = " + s)
集合
Scala中的集合分两种:可变和不可变。可变集合可以被更新或修改,增删改操作会作用与原集合对象。而不可变集合是不可以被更新或修改的,增删改会导致生成新的集合对象,原集合对象没有任何变化。
在不导入任何包的情况下,Scala会默认自动导入下面的包:
import java.lang._
import Scala._
import Predf._
而Predef对象中包含了Set、Map等定义
type Map[A, +B] = immutable.Map[A, B]
type Set[A] = immutable.Set[A]
val Map = immutable.Map
val Set = immutable.Set
因此Scala默认导入的包是不可变集合,Scala.collection.immutable,想要使用可变集合就要手动导入Scala.collection.mutable包中的可变集合。
mutable和immutable包中常用的可变集合和不可变集合的对应关系表如下:
| 可变(mutable) | 不可变(immutable) |
|---|---|
| ArrayBuffer、ArraySeq | Array |
| ListBuffer、MutableList | List |
| LinkedList、DoubleLinkedList | / |
| Queue | / |
| Stack | Stack |
| HashMap | HashMap |
| HashSet | HashSet |
| ArrayStack |
数组(Array)
列表(List)
集合(Set)
映射(Map)
队列(Queue)
栈(Stack)
Stream vs Views vs Iterator
集合性能测试
https://colobu.com/2016/11/17/Benchmarking-Scala-Collections
函数
一个Scala函数:
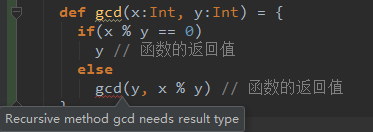
def gcd(x: Int, y: Int): Int = {
if (x % y == 0)
y // 函数的返回值
else
gcd(y, x % y) // 函数的返回值
}
其中def是函数声明,gcd是函数名称,x:Int和y:Int是Int类型的函数形参,最后的:Int是函数返回值类型。=后的花括号包含的是函数体,当函数体只有一行的时候可以省略掉{}
。函数中的最后一条执行语句为函数的返回值,返回值可以加return关键字,也可以不加。
Scala的函数还有类型推导功能,如果不写函数返回值类型,会根据最终的返回值推导出函数的返回值类型。
def sum(x: Int, y: Int) = x + y
类型推导有两个限制:
- 如果函数中存在递归调用,则必须显示的指定函数的返回值类型,不能省略,否则编译报错。
- 如果使用
return指定返回值,则必须显示指定函数的返回值类型,不能省略,否则编译报错。
使用变长参数
函数的最后一个参数可以是重复的,这样就可以向函数传递一个可变长的参数列表。
def echo(str: String, strs: String*) = {
println(str)
strs.foreach(println)
}
调用函数
echo("my", "name", "is", "zhangqiang")
输出
my
name
is
zhangqiang
String*的底层类型实际上是Array[String],但是如果你直接给函数传递一个Array[String]类型的参数会出type mismatch的编译错误。因为函数接到的参数类型是Array[String]
,而不是String。要正确传递参数则需要这样
val arr = Array("name", "is", "zhangqiang")
// _* 会告知编译器需要把 arr 中的每个元素都当作参数传递给函数,而不是将 arr 当作一个参数传递给函数。
echo("my", arr: _*)
值函数(函数字面量)
Scala中函数也是对象,可以赋值给变量,这种函数称为值函数或函数字面量。
val sum = (x: Int, y: Int) => {
x + y
}
其中sum是变量名(函数名),(x:Int, y:Int)是函数参数,=>是函数映射符,{}中的内容是函数体,同理如果只有一行可以省略。
像(x:Int, y:Int) => { x + y }这样的表达式被称为Lambda表达式,因此值函数也被称为Lambda函数或者匿名函数。
值函数不能像正常函数一样指定返回值类型,只能用类型推导的方式确定返回值类型,因此函数体中也不可以包含关键字return.
// 值函数不能在参数后面指定返回值类型
val sum = (x: Int, y: Int): Int => x + y
编译报错:
Error:(42, 37) not found: type +
val sum = (x:Int, y:Int):Int => x + y
Error:(42, 14) not found: value x
val sum = (x:Int, y:Int):Int => x + y
Error:(42, 21) not found: value y
val sum = (x:Int, y:Int):Int => x + y
并且值函数不支持变长参数
val concat = (cols: String *) = cols.mkString
编译报错
Error:(14, 29) ')' expected but identifier found.
val concat = (cols: String*) => cols.mkString
调用函数和使用普通函数一样,例如:sum(1, 2)。
值函数可以跟一般的val变量一样使用lazy关键字修饰,只有当程序真正使用到该函数字面量的时候才会被创建。
值函数最常用的场景是作为高阶函数的输入参数,例如我们常用的map()
def map[B](f: (A) => B): Array[B]
其中f就是值函数,输入参数只有一个,类型为A,返回值类型是B,其中B是泛型。
例如将数组中的各个元素都加1
// 定义一个值函数,作用于数组中的每一个元素
val arr = Array(1, 2, 3, 4)
val increment1 = (x: Int) => {
x + 1
}
val resultArr = arr.map(increment1)
而在实际使用中值函数一般都只使用一次,直接用匿名函数作为参数。
val arr = Array(1, 2, 3, 4)
val resultArr = arr.map((x: Int) => {
x + 1
})
Scala语法博大精深,在实际使用中也不用这么麻烦,写这么多代码,可以将其简化,下面就逐步讲解神(cao)奇(dan)的语法糖:
// 因为arr是Int类型的数组,使用map的时候可以通过类型推断得知它的输入类型是Int,因此可以将输入参数的类型省略
arr.map((x) => {
x + 1
})
// 在调用函数时,如果只有一个参数,可以用花括号`{}`来替代小括号`()`。map函数只有一个函数类型的参数。
arr.map {
(x) => {
x + 1
}
}
// 当用花括号`{}`来限定函数类型的参数时,不论函数体中有多少行代码,函数的花括号`{}`都可以省略。
arr.map {
(x) => x + 1
}
// 在定义函数时,如果函数的输入参数只有一个,可以将()省略,map函数的参数是函数类型,这个函数的输入参数是一个。
arr.map {
x => x + 1
}
// 对于值函数, => 左面的输入参数 x 在 => 右面只出现过一次,因此可以用占位符 _ 代替
arr.map {
_ + 1
}
需要注意的是:arr.map(_+1)合法是因为arr是Int类型的可以推断出_的类型。但是单独声明值函数就会出错,例如:
// val increment = (x:Int) => {1 + x} 的简写
val increment = 1 + _
即便有1 +这种表达式,但是还不足让编译器推断出准确的类型,因为_还有可能是String类型,这时就需要指定明确的类型。
val increment = 1 + (_: Int)
或者指定increment的具体类型,输入参数是Int类型,返回值是Int类型。这样也可以。
val increment: (Int) => Int = 1 + _
下面用 Spark 中的withScope方法举一个实例:
// withScope 的源码定义,它接收一个函数类型参数body,body是一个参数列表为空,返回值类型为泛型U的函数。
private[spark] def withScope[U](body: => U): U = RDDOperationScope.withScope[U](sc)(body)
// 调用 withScope,用`{}`替代`()`,因为是无参的函数,函数映射符`=>`也省略了。
def collectAsMap(): Map[K, V] = self.withScope {
val data = self.collect()
val map = new mutable.HashMap[K, V]
map.sizeHint(data.length)
data.foreach { pair => map.put(pair._1, pair._2) }
map
}
高阶函数
一个函数的输入参数中有函数类型的参数,或者返回值的类型是函数类型,那么这个函数就是高阶函数。
输入参数是函数类型的
def higherOrderFunction(f: (Double) => Double) = {
f(1)
}
返回值是函数类型的
def higherOrderFunction(factor: Int): (Double) => Double = {
(x: Double) => factor * x
}
常见高阶函数的使用:其中A是调用函数的迭代对象的元素的类型,例如:Array(1,2).map(),调用函数的迭代对象是Array[Int],所以A是Int类型。
1.map() 将函数f应用于调用map()的可迭代对象的每一个元素,返回新的可迭代对象。
// Array的map函数定义
def map[B](f: (A) => B): Array[B]
// Array类型的map函数
Array("kafka", "sparkstreaming", "elasticsearch").map(_ * 2)
// List类型的map函数
List("kafka", "sparkstreaming", "elasticsearch").map((_, 1))
// Map类型的map函数
Map("kafka" -> 1, "sparkstreaming" -> 2, "elasticsearch" -> 3).map(_._1)
2.flatMap() 将函数f应用于调用flatMap()的可迭代对象的每一个元素,每一个元素会转换成相应的集合GenTraverableOnce[B],最后将得到的所有集合扁平化,返回一个新的可迭代对象。
// Array的flatMap函数定义
def flatMap[B](f: (A) => GenTraversableOnce[B]): Array[B]
// flatMap的使用
Array("Hello world", "This is John Snow").flatMap(
sentence => {
val words: Array[String] = sentence.split("")
val statistics: Array[(String, Int)] = words.map(word => {
(word, 1)
})
statistics
})
// 简写
Array("Hello world", "This is John Snow").flatMap {
_.split(" ").map((_, 1))
}
3.filter() 返回所有满足条件p的元素
// Array的filter函数定义
def filter(p: (T) => Boolean): Array[T]
// filter的使用,返回大于3的元素
Array(1, 5, 7, 3, 4).filter(_ > 3)
4.reduce() 使用op作用于集合之上,返回结果类型为A1。op是特定的联合二元算子(associative binary operator),A1为A的超类。
// Array的reduce函数定义
def reduce[A1 >: A](op: (A1, A1) => A1): A1
// reduce的使用,结果是10
Array(1, 2, 3, 4).reduce((x1, x2) => {
println(s"x1 = ${x1}, x2 = ${x2}")
x1 + x2
})
// 输出结果
// x1 = 1, x2 = 2
// x1 = 3, x2 = 3
// x1 = 6, x2 = 4
// 简写
Array(1, 2, 3, 4).reduce(_ + _)
/**
* reduce还有两个变种,reduceLeft()、reduceRight()。
* reduceLeft()和reduce()一样,op函数按照集合中元素的顺序从左到右进行reduce操作,
* 而reduceRight()作用顺序相反。
* 只要记住left就是取元素的顺序和x1、x2的赋值顺序都是从左往右,
* 计算结果也是先从左开始赋值(x1),right就全部反过来就可以了。
*/
Array(1, 2, 3, 4).reduceRight((x1, x2) => {
println(s"x1 = ${x1}, x2 = ${x2}")
x1 + x2
})
// 输出结果
// x1 = 3, x2 = 4
// x1 = 2, x2 = 7
// x1 = 1, x2 = 9
5.fold() 使用联合二元算子对集合进行fold操作,z为给定的初始值。和reduce差不多,区别就是有初始值z
// Array的fold函数定义
def fold[A1 >: A](z: A1)(op: (A1, A1) => A1): A1
// fold的使用,结果是10
Array(1, 2, 3, 4).fold(0)((x1, x2) => {
println(s"x1 = ${x1}, x2 = ${x2}")
x1 + x2
})
// 输出结果
// x1 = 0, x2 = 1
// x1 = 1, x2 = 2
// x1 = 3, x2 = 3
// x1 = 6, x2 = 4
// 简写
Array(1, 2, 3, 4).fold(0)(_ + _)
/**
* fold同样也有两个变种,foldLeft()、foldRight()。
* foldLeft()和fold()一样,op函数按照集合中元素的顺序从左到右进行fold操作,
* 而foldRight()作用顺序相反
*/
Array(1, 2, 3, 4).foldRight(0)((x1, x2) => {
println(s"x1 = ${x1}, x2 = ${x2}")
x1 + x2
})
// 输出结果
// x1 = 4, x2 = 0
// x1 = 3, x2 = 4
// x1 = 2, x2 = 7
// x1 = 1, x2 = 9
闭包
“An Object is data with functions.A Closure is a function with data” —— Jon D. Cook
闭包是由函数和运行时的数据决定的,也可以理解为函数和上下文。
// 自由变量(上下文),在运行中随时可能发生变化
var factor = 2
// 函数
val f = (x: Int) => x * factor
f(2) // 得到结果 4
factor = 3
f(2) // 得到结果6
自由变量factor在程序运行时随时可能发生变化,它处于一个开放的状态。但是执行函数f时,就临时确定了自由变量factor的值,自由变量就暂时处于一个封闭的状态,这种存在从开放到封闭过程的函数就称为闭包。
高阶函数也可以理解为闭包,例如:
def higherOrderdFunction(f: Double => Double) = {
println(f(1.7))
}
// 向上取整
val f1 = (x: Double) => Math.ceil(x)
// 向下取整
val f2 = (x: Double) => Math.floor(x)
higherOrderdFunction(f1) // 结果是2.0
higherOrderdFunction(f2) // 结果是1.0
可见 f 就是自由变量(上下文),函数在运行时传入的参数不一样得到的结果也是不一样的,因此高阶函数也是一种闭包(closure)。
函数柯里化
一个返回值类型是函数类型的高阶函数:
def higherOrderFunction(factor: Int): (Double) => Double = {
(x: Double) => factor * x
}
用下面的方式调用这个函数:
higherOrderFunction(3)(5.0) // 结果是 15.0
// 实际调用过程是下面的样子。
val f = higherOrderFunction(3) // f = (x: Double) => 3 * x
f(5.0) // 结果 15.0
这种调用方式合并的函数调用方式与柯里化函数十分相似,柯里化函数的定义是这个样子的。
def curryMultiply(factor: Int)(x: Double) = factor * x
// 调用
curryMultiply(3)(5.0) // 结果是15.0
// 例如 hbase的scan方法
def scan(tableName: String, cf: String, startRow: String, stopRow: String)(processFn: (Result) => Unit) = {
...
}
// 在调用时如果参数只有一个时,可以用花括号{}代替小括号()
scan(t1, cf, startRow, stopRow) { r =>
//TODO process result
}
需要注意的是:柯里化函数和高阶函数不同,curryMultiply(3)并不能返回一个函数对象,需要写上所有的柯里化参数。
如果想让柯里化的函数生成新的函数,就需要下一节的部分应用函数(partially applied function)
部分应用函数
让柯里化函数生成部分应用函数。
val part = curryMultiply(3) _
part(5.0) // 结果是15.0
// 注意函数名和 _ 之间有空格
val part2 = curryMultiply _
part2(3)(5.0)
其中part是(Double) => Double类型的函数,part2是(Int) => (Double => Double)类型的函数。part2就可以像高阶函数一样来返回函数对象了。
不只是柯里化函数可以转为部分应用函数,普通的函数也可以。
def price(x1: Double, x2: Double, x3: Double): Double = {
x1 + x2 * x3
}
// 一个参数的部分应用函数,返回一个 Double => Double 类型的函数
def price_1 = price(_: Double, 699.0, 0.7)
// 调用
price_1(18.0)
// 两个参数的部分应用函数,返回一个 (Double, Double) => Double 类型的函数
def price_2 = price(_: Double, _: Double, 0.7)
// 调用
price_2(18.0, 699.0)
// 两个参数的部分应用函数,返回一个 (Double, Double, Double) => Double 类型的函数
def price_3 = price(_: Double, _: Double, _: Double)
// 调用
price_3(18.0, 699.0, 0.7)
// 等价与 price_3
def price_4 = price _
偏函数
离散数学中,函数的概念主要是限制了关系概念中的一对多,但是允许多对一。即在函数y = f(x)中一个x值只能对应一个y值,不可以对应多个y值,但是x0、x1、x2可以对应同一个y值。
如果所有的x值,在y = f(x)函数中都能找到对应的y值,那么这个函数就是全函数,如果存在某个x找不到对应的y值,那么这个函数就是偏函数。
Scala中的偏函数定义为trait PartialFunction[-A, +B] extends (A => B)。其中泛型A是片函数的输入参数类型,泛型B
是偏函数的返回结果类型。偏函数只处理参数定义域的子集,对于子集外的参数会抛出异常,这一特点与Scala模式匹配的特点吻合。
// 定义一个偏函数,只处理偶数值的参数
val isEven: PartialFunction[Int, String] = {
case x if x % 2 == 0 => x + "is even"
}
// 对于定义域子集外的参数会抛出异常
isEven(11)
/*
Caused by: Scala.MatchError: 11 (of class java.lang.Integer)
at Scala.PartialFunction$$anon$1.apply(PartialFunction.Scala:253)
at Scala.PartialFunction$$anon$1.apply(PartialFunction.Scala:251)
at com.zq.Scala.函数.部分应用函数$$anonfun$2.applyOrElse(部分应用函数.Scala:41)
at com.zq.Scala.函数.部分应用函数$$anonfun$2.applyOrElse(部分应用函数.Scala:41)
at Scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.Scala:36)
at com.zq.Scala.函数.部分应用函数$.<init>(部分应用函数.Scala:45)
at com.zq.Scala.函数.部分应用函数$.<clinit>(部分应用函数.Scala)
... 1 more
*/
// 除了定义一个变量是PartialFunction[Int, String]类型的,还可以直接定义函数
def partial: PartialFunction[Any, Unit] = {
case x: Int => println("Int")
case x: String = > println ("String")
}
类与对象
Scala底层还是用的jvm,所以Scala类文件也会被编译成java字节码文件,逻辑上可以理解为将Scala代码转换成相应的java代码来执行。
定义一个类
class Person {
// 声明一个成员变量,Scala中的成员变量在声明时必须要初始化,可以使用占位符。如果在定义时确实不需要初始化,则需要将类定义为抽象类。
var name: String = null
}
上面的代码就相当于java的下列这些代码,Scala会自动添加下面的方法。
class Person {
// 虽然成员变量在Scala中声明时并没有添加private关键字,但实际上转换成字节码时是private的
// 因此要访问name只能通过下面public的name()和name_$eq(String name)方法
private String name = null;
// 默认构造方法
public Person() {
}
// getter方法
public String name() {
return this.name;
}
/**
* setter方法
* name_$eq(java.lang.String)等同于name_=(java.lang.String)
* 这是因为字节码的字符限制问题导致的
*/
public void name_$eq(String name) {
this.name = name;
}
}
如果成员变量定义为val
class Person {
// 声明一个成员变量,Scala中的成员变量在声明时必须要初始化,可以使用占位符。如果在定义时确实不需要初始化,则需要将类定义为抽象类。
val name: String = null
}
就会转换成下面的样子,与var相比,会发现成员变量被final修饰,而且少了setter方法
class Person {
// 虽然成员变量在Scala中声明时并没有添加private关键字,但实际上转换成java字节码时是private的
private final String name = null;
// 默认构造方法
public Person() {
}
// getter方法
public String name() {
return this.name;
}
}
如果声明成员变量是用private关键词修饰时,生成的setter和getter方法也是private的,这样就限定了成员只能在类中访问。
class Person {
private var name: String = null
}
相当于
class Person {
private String name = null;
// 默认构造方法
public Person() {
}
// getter方法
private String name() {
return this.name;
}
// setter方法
private void name_$eq(String name) {
this.name = name;
}
}
创建对象
同java一样,使用关键字new你的对象。
val girlFriend = new Female("xx")
// 对于无参的构造函数,可以省略()
val singleDog = new Dog
类成员的访问
对于var定义的类成员变量,通过自动生成的getter、setter方法来访问类成员。
person = new Person
// 显式调用setter
person.name_$eq("zhangsan")
// getter
val name = person.name
// 隐式调用setter
person.name = "lisi"
看完隐式调用setter,你可能发现了一个问题,生成的字节码文件中的name是被关键字private修饰的,为什么可以直接访问name呢?因为实际上Scala底层依然是调用的name_$eq(String name)
方法,而它是public的,只不过编译器的开发人员将这些细节屏蔽掉了。像这种调用者不知道是直接对成员变量进行访问,还是通过setter进行访问的方式称为统一访问原则
默认生成的setter和getter是Scala风格的,如果想生成java风格的setter和getter,需要使用注解@BeanProperty
import Scala.beans.BeanProperty
class Person {
@BeanProperty var name: String = null
}
相当于下面的代码,可以看到除了生成Scala风格的getter和setter,还会生成java风格的getter和setter
class Person {
private String name = null;
// 默认构造方法
public Person() {
}
// Scala风格的getter方法
public String name() {
return this.name;
}
// Scala风格的setter方法
public void name_$eq(String name) {
this.name = name;
}
// java风格的getter方法
public String getName() {
return this.name;
}
// java风格的setter方法
public void setName(String name) {
this.name = name;
}
}
单例对象 object
实际应用中,常常存在不创建对象就可以访问相应的成员变量或方法的场景,java使用关键字static来实现这个场景。而Scala并没有关键字static,它使用单例对象(object)来实现这个场景。
object Person {
private var num: Int = _
def increment() = {
num += 1
}
}
// 不需要创建对象,通过单例对象名称就可以直接访问其成员方法了
Person.increment()
转换成字节码反编译成java代码可以看到increment()被关键字static修饰。
应用程序对象
在java程序中,只要类中定义了public static void main(String[] args)方法的类就是程序执行的入口。在Scala中同样也是使用main函数作为程序的入口,但是main方法只能定义在单例对象(
object)中,定义了main方法的单例对象就成为应用程序对象(App)。
object Main {
def main(args: Array[String]): Unit = {
var num = 1
println(num)
}
}
除了手动定义main方法,还可以通过混入特质(trait)App来定义应用程序对象,这样在对象中可以直接写执行代码,使得代码更简洁,但是所有的局部变量(本来在main方法中声明的变量)会变成object的成员变量。
object Main extends App {
var num = 1
println(num)
}
伴生对象(Companion Object)和伴生类(Companion Class)
伴生类和伴生对象区别于其他类或者对象的最主要的地方就是控制访问权限。
// 伴生类
class Student {
private var name: String = null
def getStudentNo = {
Student.incrementNo()
// 伴生类中可以直接访问伴生对象Student的私有成员studentNo
Student.studentNo
}
}
// 伴生对象
object Student {
private var studentNo: Int = 0
def incrementNo() = {
studentNo += 1
}
// 伴生对象中可以直接访问伴生类中的私有成员name
def printName() = println(new Student().name)
}
上面的代码可以看出,伴生类与伴生对象互相开放了成员的访问权限。除此之外,伴生类和伴生对象还可以实现无new的方式创建对象。例如创建一个Array
val arr = Array(1, 2, 3, 4, 5)
// 其实它调用的是伴生对象Array中的apply方法
object Array extends FallbackArrayBuilding {
/** Creates an array of `Int` objects */
// Subject to a compiler optimization in Cleanup, see above.
def apply(x: Int, xs: Int*): Array[Int] = {
val array = new Array[Int](xs.length + 1)
array(0) = x
var i = 1
for (x <- xs.iterator) {
array(i) = x; i += 1
}
array
}
}
亲自实现一个
// 伴生类
class Student {
private var name: String = null
}
// 伴生对象
object Student {
private var studentNo: Int = 0
def incrementNo() = {
studentNo += 1
}
// apply方法,当使执行Student()时就会调用伴生对象的apply()方法,类似与构造方法。
def apply: Student = new Student()
}
主构造函数
主构造函数的定义:
// 如果不写 var 默认成员变量是 val 的
class Student(var name: String, var age: Int) {
// 类体中的执行代码会在构造函数中执行。
println("this is construct method")
}
上面的代码就相当于下面的java代码,看完你就会发现Scala的代码是有多简洁了。
class Student {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Student(String name, int age) {
System.out.println("this is construct method");
this.name = name;
this.age = age;
}
}
主构造函数可以为参数提供默认值,这样创建对象的时候就可以不指定使用默认值的参数了。
class Student(var name: String, var age: Int = 18)
// age 使用默认值 18
new Student("zhangsan")
通过private关键字将构造函数私有化,这样就只能在类内部使用构造函数。
class Student private(var name: String, var age: Int)
辅助构造函数
当一个类中需要多个构造函数的时候,就需要用到辅助构造函数了。Scala使用this关键字来构造辅助函数(类改名的时候就不用改构造方法名了)。
// 无参的主构造函数
class Student {
private var name: String = null
private var age: Int = 0
// 辅助构造函数
def this(name: String) {
// 调用无参的默认主构造函数,这是必须的,否则会报错
this()
this.name = name
}
// 辅助构造函数同样可以指定默认值
def this(name: String, age: Int = 18) {
// 调用一个参数的辅助构造函数
this(name)
this.age = age
}
}
对于私有的主构造函数或者辅助函数,无法在类外部调用。下面调用其实调用的是公有的辅助构造参数。
// 定义私有的主构造函数
class Student private {
private var name: String = null
private var age: Int = 0
// 都赋上默认值
def this(name: String = "zhangsan", age: Int = 18) {
// 调用一个参数的辅助构造函数
this()
this.name = name
this.age = age
}
override def toString: String = {
s"name = ${this.name}, age = ${this.age}"
}
}
// 结果是 name = zhangsan, age = 18
println(new Student().toString)
构造函数的执行顺序
首先回顾下Java的构造函数执行顺序:创建子类对象的时候会先调用父类的构造函数,然后调用子类的构造函数。在Scala中顺序也是如此。
class Person(var name: String, var age: Int) {
// 类中的执行语句,相当于写在类的主构造函数中
println("调用Person(父)类的主构造函数")
}
class Student(name: String, age: Int, var grade: String) extends Person(name: String, age: Int) {
// 类中的执行语句,相当于写在类的主构造函数中
println("调用Student(子)类的柱构造函数")
}
new Student("张三", "18", "大学一年级")
输出结果如下:
调用Person(父)类的主构造函数
调用Student(子)类的柱构造函数
内部类和内部对象
内部类就是定义在对象(object单例对象)或类内部的类,内部对象就是定义在对象或类内部的对象
object Practice extends App {
// 伴生类
class Car(var carType: String, var color: String) {
// 内部类
class Wheel(var radius: Double) {}
// 内部对象
object Tools {
def navigation(destination: String) = println(s"开往$destination")
}
}
// 伴生对象
object Car {
// 内部类
class Descriptor(car: Car) {
override def toString: String = s"${car.color}的${car.carType}"
}
// 内部对象
object Printer {
def printDescriptor(descriptor: Descriptor) = println(descriptor)
}
}
val car = new Car("凯迪拉克", "黑色")
// 创建一个伴生对象中的内部类对象
val descriptor = new Car.Descriptor(car)
// 调用伴生对象中的内部对象中的方法
Car.Printer.printDescriptor(descriptor)
// 创建一个伴生类中的内部类对象
val wheel = new car.Wheel(631.9)
// 调用伴生类中的内部对象中的方法
car.Tools.navigation("希尔顿酒店")
}
执行结果如下:
黑色的凯迪拉克
开往希尔顿酒店
继承与多态
继承 是面向对象语言实现代码复用的重要特性,子类除了能够继承父类的属性和方法外,还可以添加自己新的属性和方法。
多态 是在继承的基础上,通过重写而实现的一种语言特性,它允许不同的子类对同一消息做出不同的反馈。
继承
Scala同Java相同,使用extends关键字实现类之间的继承。
class Person(var name: String, var age: Int) {
// 这是Scala方法重写的语法,与Java不同。
override def toString: String = s"name:${name},age:${age}"
}
/**
* Student中的name和age并没有var修饰,因为这两个成员变量是继承自Person类
* 而 var grade:String 是新增加的成员
*/
class Student(name: String, age: Int, var grade: String) extends Person(name, age) {
override def toString: String = s"${super.toString},grade:${grade}"
}
子类如果需要继承父类的成员变量,在继承的时候要带上成员变量extends Person(name, age),而且在声明的时候不能使用var和val关键字修饰。
多态
多态(polymorphic)又称动态绑定(dynamic binding)或者延迟绑定(late binding)。在代码执行期间而非编译期间确定所引用对象的实际类型(确切的子类型) ,根据其实际的类型调用相应的方法。实际上就是将子类的引用赋值给父类的变量,在程序运行的时候去确定具体的子类,然后调用子类相应的方法。
多态遵守一个准则,对于重写的方法,不管变量声明的类型是什么,调用方法时以实际引用对象的类型(子类型)为准。什么意思呢?看下面的例子
class Person(var name: String, var age: Int) {
def squat(): Unit = {
println("人蹲")
}
def sayName(): Unit = {
println(s"我是$name")
}
}
class Zombie(name: String, age: Int) extends Person(name, age) {
override def squat(): Unit = {
println("小僵尸蹲")
}
def zombieJump(): Unit = {
println("小僵尸跳")
}
}
// 声明一个Person类型的变量p,将子类Zombie类型的对象赋值给它
val p: Person = new Zombie("秦始皇", 5000)
p.squat()
p.sayName()
// 因为p声明为Person类型,所以对象p无法调用Zombie类特有的方法zombieJump(),除非将其强转为Zombie类。
输出结果
小僵尸蹲
我是秦始皇
对于子类重写的方法,虽然声明变量p是Person类型,实际调用的是子类中的squat()方法。想想如果它不这么设计,就没有办法构成多态了。
抽象类
抽象类是一种不能直接实例化的类,与Java相同使用关键字abstract
声明抽象类,Scala中的抽象类可以有抽象成员变量、抽象成员方法、具体成员变量、具体成员方法。Scala普通类中的成员变量必须显式初始化,如果不显式初始化,就必须将类声明为抽象类,当子类继承了抽象类的时候,就需要将没有初始化的成员变量初始化,否则子类也必须声明为抽象类。
abstract class Person {
// 抽象成员变量
var name: String
// 抽象成员方法,注意abstract只能用于修饰class
def squat()
// 具体成员变量
var age: Int = 5000
// 具体成员方法
def sayName(): Unit = {
println(s"我是$name")
}
}
class Zombie extends Person {
// 对抽象成员变量和抽象成员方法重写时 override 关键字可以省略
override var name: String = "嬴政"
override def squat(): Unit = {
println("小僵尸蹲")
}
}
反编译上面的抽象类Person
public abstract class com.zq.Practice$Person{
private int age;
public abstract java.lang.String name();
public abstract void name_$eq(java.lang.String);
public abstract void squat();
public int age();
public void age_$eq(int);
public void sayName();
public com.zq.Practice$Person();
}
可以看到反编译后,抽象类中的抽象成员变量name不见了,只有setter方法。而具体成员变量age,既生成了成员变量age,还有getter和setter方法。
Trait 特质(接口)
什么是 trait
Scala中没有interface,而是使用trait关键字,tarit用来封装成员方法和变量,中文翻译过来就是特质。但是trait并不等于Java中的interface,他们之间的不同,我们稍后再说。
首先给出TraitTest.Scala的源码:
package com.zq
trait TraitTest {
// 方法声明
def add(o: Any)
def delete(o: Any)
def update(o: Any)
def select(id: String): Any
}
我们将Scala代码编译成字节码,然后通过javap -private TraitTest.class命令反编译后可以看到
Compiled from "TraitTest.Scala"
public interface com.zq.TraitTest {
public abstract void add(java.lang.Object);
public abstract void delete(java.lang.Object);
public abstract void update(java.lang.Object);
public abstract Object select(java.lang.String);
}
定义一个 trait
Scala中没有implements关键字,对于类、Java接口、Scala特质都是用extends进行扩展。对于第一个混入的特质,使用extends,其余的使用with:
trait Trait1
trait Trait2
trait Trait3
class A extends Trait1 with Trait2 with Trait3
定义一个Trait,有两种方式:
- 直接定义,见上
- 继承Java接口,见下
tarit Cloneable extends java.lang.Cloneable {}
trait 和 interface 的区别
上面除了语法上和Java的interface有些不同,好像也没什么不一样的,别急,下面来讲解差别到底在哪。
trait中可以有:抽象成员变量、抽象成员方法(方法声明)、具体成员变量、具体成员方法。是不是和抽象类很像。下面看一个具体trait
trait TraitTestAll {
// 具体成员变量
var id = "0000001"
// 抽象成员变量
var record: String
// 具体成员方法
def add(o: Any) = println("add")
// 抽象成员方法
def select(id: String): Any
}
编译后发现TraitTestAll.Scala生成了两个.class文件TraitTestAll.class和TraitTestAll$class.class,下面分别看看反编译后的内容,本例使用jd-gui(
一款绿色的反编译工具)反编译:
首先看下TraitTestAll.class
package com.zq;
import Scala.reflect.ScalaSignature;
import Scala.runtime.TraitSetter;
@ScalaSignature(bytes = "\006\001}2q!\001\002\021\002\007\005qA\001\007Ue\006LG\017V3ti\006cGN\003\002\004\t\005\021!0\035\006\002\013\005\0311m\\7\004\001M\021\001\001\003\t\003\0231i\021A\003\006\002\027\005)1oY1mC&\021QB\003\002\007\003:L(+\0324\t\013=\001A\021\001\t\002\r\021Jg.\033;%)\005\t\002CA\005\023\023\t\031\"B\001\003V]&$\bbB\013\001\001\004%\tAF\001\003S\022,\022a\006\t\0031ui\021!\007\006\0035m\tA\001\\1oO*\tA$\001\003kCZ\f\027B\001\020\032\005\031\031FO]5oO\"9\001\005\001a\001\n\003\t\023AB5e?\022*\027\017\006\002\022E!91eHA\001\002\0049\022a\001=%c!1Q\005\001Q!\n]\t1!\0333!\021\0359\003\0011A\007\002!\naA]3d_J$W#A\025\021\005)jcBA\005,\023\ta#\"\001\004Qe\026$WMZ\005\003=9R!\001\f\006\t\017A\002\001\031!D\001c\005Q!/Z2pe\022|F%Z9\025\005E\021\004bB\0220\003\003\005\r!\013\005\006i\001!\t!N\001\004C\022$GCA\t7\021\02594\0071\0019\003\005y\007CA\005:\023\tQ$BA\002B]fDQ\001\020\001\007\002u\naa]3mK\016$HCA\t?\021\025)2\b1\001*\001")
public abstract interface TraitTestAll {
public abstract String id();
@TraitSetter
public abstract void id_$eq(String paramString);
public abstract String record();
public abstract void record_$eq(String paramString);
public abstract void add(Object paramObject);
public abstract void select(String paramString);
}
然后看下TraitTestAll$class.class
package com.zq;
import Scala.Predef.;
public abstract class TraitTestAll$class {
public static void $init$(TraitTestAll $this) {
$this.id_$eq("0000001");
}
public static void add(TraitTestAll $this, Object o) {
Predef..MODULE$.println("add");
}
}
从上面可以看出TraitTestAll生成了一个interface和一个abstract class,在interface中将具体成员变量和抽象成员变量的setter和getter声明为abstract
方法,但具体成员变量的setter用注解@TraitSetter标注,而且不论是具体成员方法还是抽象成员方法都声明为abstract方法。然后在抽象类TraitTestAll$class
中的静态方法$init$(TraitTestAll $this)中去初始化具体成员变量,最后添加具体成员方法的实现。
trait 和 abstract class 的相似点
trait 和 abstract class 除了可以有抽象方法,具体方法,还可以有执行语句。
abstract class Logger {
println("Logger.") // 执行语句
}
trait DailyLogger extends Logger {
println("DailyLogger.") // 执行语句
}
trait FileLogger extends Logger {
println("FileLogger.") // 执行语句
}
class DailyFileLogger extends DailyLogger with FileLogger {
println("DailyFileLogger.") // 执行语句
}
def main(args: Array[String]): Unit = {
new DailyFileLogger()
}
输出结果:
Logger.
DailyLogger.
FileLogger.
DailyFileLogger.
trait 和 abstract class 的区别
到这里可能发现Scala的 trait 的抽象程度更贴近于 abstract class。其实还是有不同的。
1.无论是普通的类还是抽象类都可以在类定义的时候使用主构造函数定义类的成员变量,但是trait就不可以。没有主构造方法,因此就不会有辅助构造方法,别忘了辅助构造方法第一行就要调用this(),否则会报错的!
如下面的例子,都是允许的:
abstract class Logger(msg: String)
class Logger(msg: String)
2.abstract class 是单继承,trait 是多继承。
多重继承问题
那么 trait 既然可以多继承,并且可以有具体的成员方法实现,肯定会遇到多重继承问题,比如菱形继承。
首先说下什么是菱形继承
abstract class Animal {
// 注意 abstract 关键词在Scala中只能用于修饰class,这里必须省略。
def describe(): Unit
}
trait Donkey extends Animal {
override def describe(): Unit = println("I'm donkey.")
}
trait Horse extends Animal {
override def describe(): Unit = println("I'm horse.")
}
class Mule extends Donkey with Horse
def main(args: Array[String]): Unit = {
val firstMuleInTheWorld = new Mule
// 让我们听听它会说什么呢
firstMuleInTheWorld.describe()
}
这就是一个典型的菱形继承问题。那么世界上第一头骡子会说自己是什么呢?是驴,是马,还是出错呢?
我们看下运行结果。
I'm horse.
Scala 在方法调用冲突的时候会对类进行线性优化,采用最右深度优先遍历算法查找调用冲突的方法,因此调用了Horse中的describe()方法。
自身类型
总结
trait 看起来什么都像,像interface、像abstract class,但也正因如此,trait有着更灵活、更强大的使用方式,甚至可以使用trait去替代interface和abstarct class。
包和访问权限
包
同Java中的包、C++中的命名空间相同,Scala中的包用于组织大型工程的代码、解决命名冲突。除了和Java一样在代码文件顶端添加package com.zq.Scala.practice(Scala可以省略分号)
来声明代码所属包路径。Scala还提供另一种灵活的方式。
package com {
class Test1 {}
package zq {
class Test2 {}
}
}
这样在程序的任何地方都可以通过com.Test1和com.zq.Test2
来使用这两个类,而且上面的代码可以出现在Scala程序中的任何地方。最后生成的字节码文件和传统的写法生成的字节码文件结构路径完全一样。虽然这种方式灵活,但会使得代码分散,不方便进行代码管理,不推荐使用(强行装逼的话,我就无话可说了)。
包的使用规则:
- 外层包不能直接访问内层包,需要
import。 - 内层包可以直接访问外层包
因此Test2可以直接访问Test1,但Test1想访问Test2的话就需要import
包对象
Scala是纯面向对象的语言,比Java还纯。通过package关键字声明的对象称为包对象(package object)。包对象主要用于封装常量、工具函数,可以直接通过包名直接引用。
package com.zq.Scala.practice
// 用package关键字修饰的单例对象
package object Math {
val PI = 3.1415926
}
class Computation {
// 这样可以直接通过package object直接访问成员
def computeArea(r: Double) = Math.PI * r * r
}
其中package object编译后会在当前包路径com.zq.Scala.practice下生成新的文件夹Math
访问权限控制
回想一下Java的访问权限,从下到大有四种:private、default(默认)、protected、public,具体访问权限如下表
| 权限 | private | default | protected | public |
|---|---|---|---|---|
| 类内可访问 | √ | √ | √ | √ |
| 包内可访问 | × | √ | √ | √ |
| 子类可访问 | × | × | √ | √ |
| 其他可访问 | × | × | × | √ |
Scala和Java不同,他只有三种权限:private、protected、默认。注意默认权限是与Java中的public对应的,而非default,并且Scala中并没有public关键字。private和protected和Java控制的作用域类似,但还有更灵活的使用方法。
使用private[X]和protected[X]限定到X可见,X代表包、类、单例对象。
注意private修饰的成员在类及其伴生对象中可见,如果想像Java一样只在类内可见,使用private[this]修饰对象,这种对象又叫做对象私有成员。
假设包结构路径为com.zq.Scala.practice,则private[Scala] object Sample{}代表限定单例对象Sample在Scala包及其子包practice中可访问。
protected也是同理。
import 高级特性
- Scala允许在任何地方使用
import,而不像Java,只能写在package声明和类声明之间。 - Scala默认引用了
java.lang._和Scala.Predef._中的所有类和方法,其中_相当于java中的*。 - 引入重命名,用于解决类命名冲突
import java.util.{HashMap => JavaHashMap}
import Scala.collection.mutable.HashMap
- 类隐藏,不引入某个包中的类,如引用Scala HashMap和除了java HashMap的util包的所有类。
import Scala.collection.mutable.HashMap
import java.util.{HashMap => _, _}
模式匹配
隐式转换 implicit
implicit是Scala中的一个关键字,也是Scala语言的一个重要特性,它使得Scala语言非常灵活、容易扩展,但是增加了代码的迷幻性。不过,这并不影响它的魔力。
隐式转换函数
Scala会默认引入scala包及scala.PreDef对象,其中包含了大量的隐式函数
声明一个隐式函数
package com.zq
package object implicits {
// 用 implicit 关键字声明的函数就是隐式函数
implicit def String2StringBuffer(str: String) = new StringBuffer(str)
}
使用隐式函数
package com.zq.test
object Test {
// 引入隐式函数
import com.zq.implicits._
// == 定义完成之后,下面的代码可以编译通过的原因:
// 1、编译器发现赋值对象的类型与最终类型不匹配时,会在当前作用域范围内查找能将 String 转换成 StringBuffer
// 类型的隐式实体(隐式转换函数、隐式类、隐式对象),而`String2StringBuffer`刚好满足要求,因此可以编译通过。
// 2、当第一步没有成功,则在隐式参数类型的作用域(与该类型相关的全部伴生模块)里查找,
// (1)例如对于类`class A extends B with C with D`的对象进行隐式转换,A、B、C、D 的伴生对象都会被搜索。
// (2)对于参数化类型,例如要对`List[String]`类型的对象进行隐式转换,则会搜索 List、String 的伴生对象
// (3)如果 A 是某个`object`中的内部类, 如`O.A`则对与 class A 的隐式转换也会搜索 object O
// (4)如果 A 是类型注入 S#A,那么 S 和 A 的伴生对象都会被搜索
// == 对于隐式函数的注意事项:
// 1、隐式函数的函数名可以是任意的,隐式转换与函数名无关,只与函数签名(输入参数类型与返回值类型)有关,
// 如果在当前作用域范围内存在函数签名相同但是函数名称不同的两个隐式函数,在进行隐式转换的时候会报错,提
// 示有歧义
// 2、隐式函数只有一个形参,如果有多个参数就失去隐式函数的意义了,编译器永远也不会使用到这个隐式函数
// 3、不支持嵌套的隐式转换,A 能隐式转换成 B,B 能隐式转换成 C,但 A 不能通过两次隐式转换转成 C
// 4、代码如果在不实用隐式转换的前提下就能变异通过就不会使用隐式转换
val sb: StringBuffer = "heihei"
}
隐式类
隐式类一般用于扩展已经存在的类
/**
* 隐式类
* 通过implicit关键字定义一个隐式类,隐式类的主构造函数接受 String 类型参数
* 这样当一个 String 类型的变量调用隐式类中的方法时,就会进行 String 类型到隐
* 式类类型的隐式转换
*/
object Test {
implicit class Dog(val name: String) {
def bark = println(s"Dog $name is barking")
}
}
// String类型本身没有bark方法,此时进行了隐式转换
"大狗".bark
/**
* == 隐式类的原理:
* 隐式类会最终被翻译成如下代码,隐式类是通过隐式函数来实现的,隐式类的代
* 码更简洁,但是也会使代码更加“迷幻”
* == 隐式类的注意事项:
* 1、只能在`class/trait/object`内部定义`implicit class`
* 2、构造函数只能有一个非隐式参数,如果有多个非隐式参数,同样的也无法用于隐式转换了。
* 但是可以有隐式参数如:`implicit class A(s: String)(implicit i: Int)`
* 3、implicit 不可以用于`case class`
*/
class Dog(val name: String) {
def bark = println(s"Dog $name is barking")
}
implicit def string2Dog(name: String) = new Dog(name)
隐式值
implicit val x: Int = 1
隐式对象和隐式参数
trait Multiplicable[T] {
def multiply(x: T): T
}
/**
* 隐式对象:整型数据的相乘
*/
implicit object MultiplicableInt extends Multiplicable[Int] {
override def multiply(x: Int): Int = x * x
}
/**
* 隐式对象:字符串数据的乘积
*/
implicit object MultiplicableString extends Multiplicable[String] {
override def multiply(x: String): String = x * 2
}
// 定义一个函数,函数具有泛型参数,限定泛型`T`为`Multiplicable`的子类
def multiply[T: Multiplicable](x: T) = {
// 使用 implicitly 方法,主动搜索`Multiplicable[T]`类型的隐式对象
val ev = implicitly[Multiplicable[T]]
ev.multiply(x)
}
// 调用隐式对象`MultiplicableInt`中的`multiply(x: Int)`方法
println(multiply(5))
// 调用隐式对象`MultiplicableString`中的`multiply(x: String)`方法
println(multiply("5"))
/**
* == 隐式参数:
* implicitly 函数被定义在`scala.Predef`对象中,其中的参数`e`使用了`implicit`
* 关键字修饰,这种形式的参数叫做隐式参数
* == 隐式参数的注意事项:
* 函数在定义的时候,只支持最后一组参数使用`implicit`表明这是一组隐式参数,这样在调用
* 该函数的时候,可以不用向传递隐式参数传递实参,编译器会自动寻找一个`implicit`修饰的
* 值、对象或函数作为该参数的实参
*/
@inline def implicitly[T](implicit e: T) = e
// 使用隐式参数定义`multiply`函数
def multiply[T: Multiplicable](x: T)(implicit ev: Multiplicable[T]) = ev.multiply(x)
/**
* 调用
* 他会在当前作用域查找类型为`Multiplicable[T]`的隐式对象,然后根据泛型`T`的实际
* 类型决定调用哪一个隐式对象中的方法
*/
println(multiply(5))
println(multiply("5"))
函数式编程
Monoids(单子)
A Monoid is any associative binary operation with a unit.
- what’s
associative? involving the condition that a group of quantities connected by operators gives the same result whatever their grouping, as long as their order remains the same, e.g., ( a × b ) × c = a × ( b × c ). - what’s
unit? a quantity chosen as a standard in terms of which other quantities may be expressed.
Monoid 是一种很广泛的代数结构。
Scala Type System
Context Bounds
Context Bounds(上下文界定),是隐式参数的语法糖,下面代码的两个max方法等价
import java.util.Comparator
// 定义一个隐式值
implicit val c: Comparator[Int] = new Comparator[Int] {
override def compare(a: Int, b: Int): Int = a - b
}
def max[T](a: T, b: T)(implicit cp: Comparator[T]): T = {
if (cp.compare(a, b) > 0) a else b
}
// 类型参数声明 T: Comparator 就表示存在一个 Comparator[T] 类型的隐式值。
def max[T: Comparator](a: T, b: T): T = {
// implicitly 是在 Predef.scala 里定义的,它是一个特殊的方法,编译器会记录当前上下文里的隐式值,而这个方法则可以获得当前上下文指定类型的隐式值。
val cp = implicitly[Comparator[T]]
if (cp.compare(a, b) > 0) a else b
}




