
基本操作
# 安装完后可以在浏览器中输入下面的URL来测试安装是否成功:
http://localhost:60010
# hbase目录输出日志文件所在位置:
$HBASE_HOME/logs/
# hbase Usage
$ hbase
Usage: hbase [<options>] <command> [<args>]
Options:
--config DIR Configuration direction to use. Default: ./conf
--hosts HOSTS Override the list in 'regionservers' file
Commands:
Some commands take arguments. Pass no args or -h for usage.
shell Run the HBase shell
hbck Run the hbase 'fsck' tool
snapshot Create a new snapshot of a table
wal Write-ahead-log analyzer
hfile Store file analyzer
zkcli Run the ZooKeeper shell
upgrade Upgrade hbase
master Run an HBase HMaster node
regionserver Run an HBase HRegionServer node
zookeeper Run a Zookeeper server
rest Run an HBase REST server
thrift Run the HBase Thrift server
thrift2 Run the HBase Thrift2 server
clean Run the HBase clean up script
classpath Dump hbase CLASSPATH
mapredcp Dump CLASSPATH entries required by mapreduce
pe Run PerformanceEvaluation
ltt Run LoadTestTool
version Print the version
CLASSNAME Run the class named CLASSNAME
# 进入hbase shell console
$HBASE_HOME/bin/hbase shell
# 如果有kerberos认证,需要事先使用相应的keytab进行一下认证(使用kinit命令),认证成功之后再使用hbase shell进入可以使用whoami命令可查看当前用户
hbase(main)> whoami
表管理
# 查看有哪些表
hbase(main)> list
# 创建表
create <table>, {NAME => <family>, VERSIONS => <VERSIONS>}
# 例如:创建表t1,有两个family name:f1,f2,且版本数均为2
hbase(main)> create 't1',{NAME => 'f1', VERSIONS => 2},{NAME => 'f2', VERSIONS => 2}
# 删除表
# 分两步:首先disable,然后drop
hbase(main)> disable 't1'
hbase(main)> drop 't1'
# 正则批量删除表
hbase(main)> disable_all 'a.*'
a1
a2
Disable the above 2 tables (y/n)?
y
hbase(main)> drop_all 'a.*'
a1
a2
Drop the above 2 tables (y/n)?
y
# 查看表的结构
describe <table>
# 例如:查看表t1的结构
hbase(main)> describe 't1'
# 修改表结构,修改表结构必须先 disable
# 语法:
alter 't1', {NAME => 'f1'}, {NAME => 'f2', METHOD => 'delete'}
# 例如:修改表test1的cf的TTL为180天
hbase(main)> disable 'test1'
hbase(main)> alter 'test1',{NAME=>'body',TTL=>'15552000'},{NAME=>'meta', TTL=>'15552000'}
hbase(main)> enable 'test1'
# 查看表是否处于 enable 或者 disable 状态
is_enable 't1' | is_disable 't1'
# 统计表记录数
count <table>, {INTERVAL => intervalNum, CACHE => cacheNum}
# INTERVAL设置多少行显示一次及对应的rowkey,默认1000;CACHE每次去取的缓存区大小(一次加载多少条数据),默认是10,调整该参数可提高查询速度
# 例如,查询表t1中的行数,每100条显示一次,一次加载500条
hbase(main)> count 't1', {INTERVAL => 100, CACHE => 500}
# 如果表很大,统计会很慢,不建议使用。
# <1> 可以调用 hbase.jar 自带的统计行数的 MapReduce 工具类
$HBASE_HOME/bin/hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'tablename'
# <2> 也可以用Hive关联HBase表,用SQL查询
权限管理
# 分配权限
grant <user> <permissions> <table> <column family> <column qualifier> 参数后面用逗号分隔
# 权限用五个字母表示: "RWXCA".
# READ('R'), WRITE('W'), EXEC('X'), CREATE('C'), ADMIN('A')
# 例如,给用户test分配对表t1有读写的权限,
hbase(main)> grant 'test','RW','t1'
# 查看权限
user_permission <table>
# 例如,查看表t1的权限列表
hbase(main)> user_permission 't1'
# 收回权限
revoke <user> <table> <column family> <columnqualifier>
# 例如,收回test用户在表t1上的权限
hbase(main)> revoke 'test','t1'
表数据的增删改查
添加数据
put <table>, <rowkey>, <family:column>, <value>, <timestamp>
# 例如:给表t1的添加一行记录, timestamp 系统默认
hbase(main)> put 't1', 'rk1', 'f1:col1', 'v1'
查询数据
# a) 查询某行记录
get <table>,<rowkey>,[<family:column>,....]
# 例如:查询表t1,rowkey001中的f1下的col1的值
hbase(main)> get 't1','rowkey001', 'f1:col1'
# 或者:
hbase(main)> get 't1','rowkey001', { COLUMN=>'f1:col1'}
# 查询表t1,rowke002中的f1下的所有列值
hbase(main)> get 't1','rowkey001'
# b) 扫描表
scan <table>, {COLUMNS=>[<family:column>,...], LIMIT=>num}
# 例如:扫描表t1的前3条数据
hbase(main)> scan 'test', {LIMIT=>3}
ROW COLUMN+CELL
1 column=cf1:cq1, timestamp=1542264962903, value=1
1 column=cf1:cq2, timestamp=1542265010138, value=2
1 column=cf2:cq1, timestamp=1542264971415, value=1
1 column=cf2:cq2, timestamp=1542265017234, value=2
2 column=cf1:cq1, timestamp=1542265136926, value=1
3 column=cf1:cq1, timestamp=1542265141513, value=1
3 row(s) in 0.0100 seconds
# c) 过滤器 Filter
# 显示所有可用的 filter
hbase(main)> show_filters
# 查看某个filter的使用方法
# 只返回一个 rowkey 下所有 key-value 的第一条
hbase(main)> scan 'test', {FILTER=>"FirstKeyOnlyFilter()"}
ROW COLUMN+CELL
1 column=cf1:cq1, timestamp=1542264962903, value=1
2 column=cf1:cq1, timestamp=1542265136926, value=1
3 column=cf1:cq1, timestamp=1542265141513, value=1
3 row(s) in 0.0160 seconds
# 只返回一个 rowkey 下所有 key-value 的 key
hbase(main)> scan 'test', {FILTER=>"KeyOnlyFilter()"}
ROW COLUMN+CELL
1 column=cf1:cq1, timestamp=1542264962903, value=
1 column=cf1:cq2, timestamp=1542265010138, value=
1 column=cf2:cq1, timestamp=1542264971415, value=
1 column=cf2:cq2, timestamp=1542265017234, value=
2 column=cf1:cq1, timestamp=1542265136926, value=
3 column=cf1:cq1, timestamp=1542265141513, value=
3 row(s) in 0.0270 seconds
# 查找所有 rowkey 以 `abc` 为前缀的数据 row
ROW COLUMN+CELL
abcdef column=cf1:cq1, timestamp=1542265446897, value=1
abcdef column=cf1:cq2, timestamp=1542265868562, value=2
1 row(s) in 0.0100 seconds
# 返回满足条件的 column
hbase(main)> scan 'test', {FILTER=>"PrefixFilter('abc') AND ColumnPrefixFilter('cq1')"}
ROW COLUMN+CELL
abcdef column=cf1:cq1, timestamp=1542265446897, value=1
1 row(s) in 0.0090 seconds
# 返回满足多条件的 column
hbase(main)> scan 'test', {FILTER=>"PrefixFilter('abc') AND MultipleColumnPrefixFilter('cq1', 'cq2')"}
ROW COLUMN+CELL
abcdef column=cf1:cq1, timestamp=1542265446897, value=1
abcdef column=cf1:cq2, timestamp=1542265868562, value=2
1 row(s) in 0.0210 seconds
删除数据
# a)删除行中的某个列值
delete <table>, <rowkey>, <family:column> , <timestamp>,必须指定列名
# 例如:删除表t1,rowkey001中的f1:col1的数据
hbase(main)> delete 't1','rowkey001','f1:col1'
# 注:将删除改行f1:col1列所有版本的数据
# b)删除行
deleteall <table>, <rowkey>, <family:column> , <timestamp>,可以不指定列名,删除整行数据
# 例如:删除表t1,rowk001的数据
hbase(main)> deleteall 't1','rowkey001'
# c)删除表中的所有数据
truncate <table>
# 其具体过程是:disable table -> drop table -> create table
# 例如:删除表t1的所有数据
hbase(main)> truncate 't1'
Namespace
Namespace 简介
namespace 是对一组表的逻辑分组,类似 RDBMS 的 database,方便表在业务上进行划分。从0.98.0+、0.95.2+ 开始支持 namespace 级别的授权操作,HBase 全局管理员可以创建、修改和回收 namespace 的授权。
HBase 系统默认定义两个缺省的 namespace
- hbase: 系统内建表,包括
namespace和meta表。 - default: 用户建表的时候如果没有指定
namespace,那么表都会创建在这里面
Note: 因为引入了 namespace 的概念,表命名空间被隔离,因此原来的 -ROOT- 表的功能由 hbase:namespace 和 hbase:meta 两张表完成
shell 基本操作
# 列出所有 namespace
hbase> list_namespace
# 创建 namespace
hbase> create_namespace 'test_namespace'
# 查看 namespace
hbase> describe_namespace 'test_namespace'
# alter namespace
hbase> alter_namespace 'test_namespace', {METHOD => 'set', 'PROPERTY_NAME' => 'PROPERTY_VALUE'}
# 删除 namespace
hbase> drop_namespace 'test_namespace'
# 在 namespace 下创建表
hbase> create 'test_namespace:test_table', 'column_family'
# 查看某个 namespace 下面的所有表
hbase> list_namespace_tables 'test_namespace'
授权
在 HBase 中启用授权机制
<property>
<name>hbase.security.authorization</name>
<value>true</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.hadoop.hbase.security.access.AccessController</value>
</property>
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.apache.hadoop.hbase.security.token.TokenProvider,org.apache.hadoop.hbase.security.access.AccessController</value>
</property>
# 授权 user 用户对 test_namespace 的写权限
hbase> grant 'user' 'w' '@test_namespace'
# 回收对 test_namespace 的所有授权
hbase> revoke 'user' '@test_namespace'
Region管理
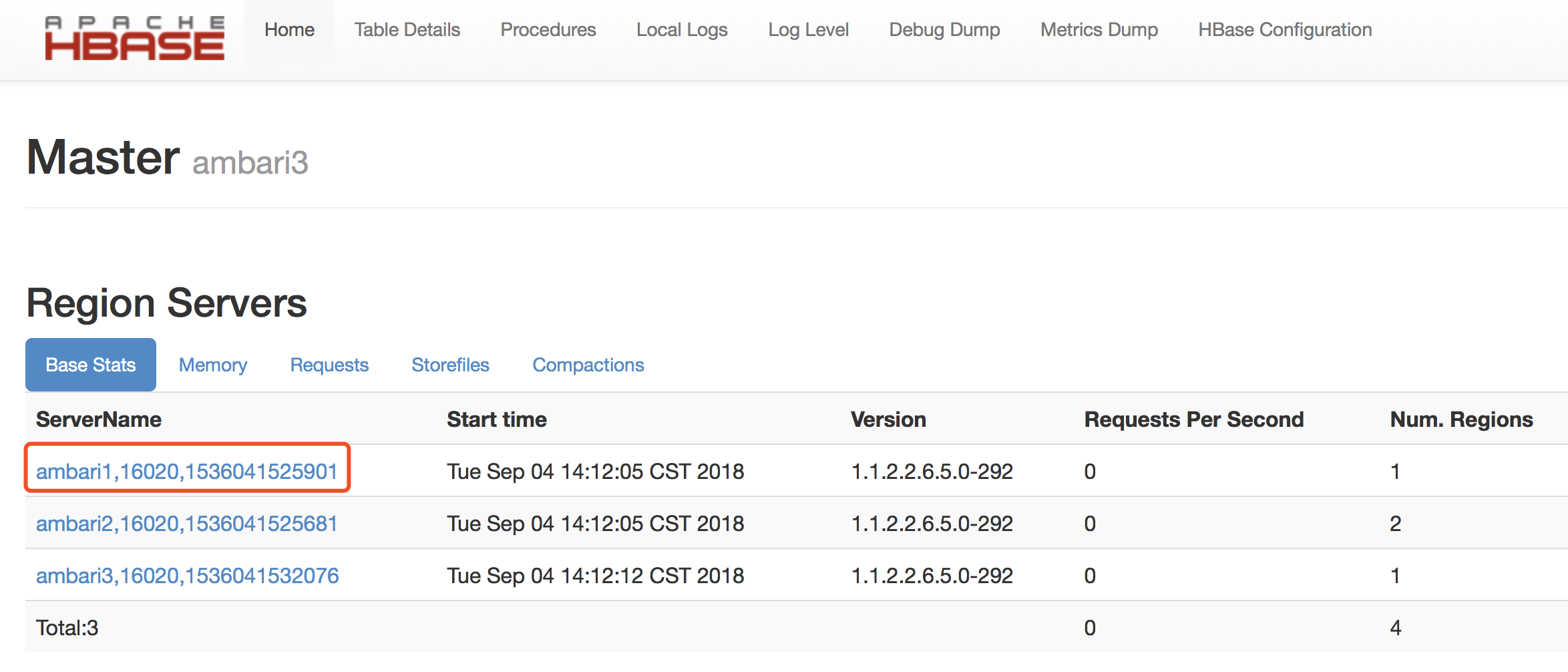
移动region
# 语法:move 'encodeRegionName', 'serverName'
hbase(main)> move '4e369bcae7354a649d45f350aef98315', 'ambari1,16020,1536041525901'
# 也可以在脚本中这样写
$ echo "move '4e369bcae7354a649d45f350aef98315', 'ambari1,16020,1536041525901'" | hbase shell
encodeRegionName指的http://ambari3:16030/rs-status的Region Name后面的编码

serverName指的是http://ambari3:16010/master-status的Region Servers列表
开启/关闭region
# 语法:balance_switch true|false
hbase(main)> balance_switch
手动split
hbase(main)> split 'regionName', 'splitKey'
手动触发major compaction
# Compact all regions in a table:
hbase> major_compact 't1'
# Compact an entire region:
hbase> major_compact 'r1'
# Compact a single column family within a region:
hbase> major_compact 'r1', 'c1'
# Compact a single column family within a table:
hbase> major_compact 't1', 'c1'
配置管理及节点重启
# 1)修改hdfs配置
# hdfs配置位置:/etc/hadoop/conf
# 同步hdfs配置:
cat /home/hadoop/slaves|xargs -i -t scp /etc/hadoop/conf/hdfs-site.xml hadoop@{}:/etc/hadoop/conf/hdfs-site.xml
# 关闭hdfs配置:
cat /home/hadoop/slaves|xargs -i -t ssh hadoop@{} "sudo /home/hadoop/cdh4/hadoop-2.0.0-cdh4.2.1/sbin/hadoop-daemon.sh --config /etc/hadoop/conf stop datanode"
# 启动hdfs配置:
cat /home/hadoop/slaves|xargs -i -t ssh hadoop@{} "sudo /home/hadoop/cdh4/hadoop-2.0.0-cdh4.2.1/sbin/hadoop-daemon.sh --config /etc/hadoop/conf start datanode"
# 2)修改hbase配置
# hbase配置位置:/home/hadoop/hbase/conf
# 同步hbase配置
cat /home/hadoop/hbase/conf/regionservers|xargs -i -t scp /home/hadoop/hbase/conf/hbase-site.xml hadoop@{}:/home/hadoop/hbase/conf/hbase-site.xml
# graceful重启
cd ~/hbase
bin/graceful_stop.sh --restart --reload --debug inspurXXX.xxx.xxx.org
数据导入和导出
./hbase org.apache.hadoop.hbase.mapreduce.Driver import/export 表名 文件路径(默认hdfs,加前缀file:///为本地数据)
执行脚本
# 将多条命令写入脚本文件中
$ vim shell.txt
disable 'table'
drop 'table'
# 执行脚本
$ hbase shell shell.txt




