SparkStreaming 介绍
SparkStreaming 是 Spark-core API 的扩展,对实时数据流(live data streams)提供可扩展(scalable)、高吞吐(high-throughput)、容错(fault-tolerant)的流处理方法。
SparkStreaming 可以从许多数据源提取数据,例如Kafka、Flume、Kinesis、TCP sockets。可以用像map、reduce、join、window这样的高级方法,配合 MLlib 和 GraphX 中的算法去处理数据。最终将处理好的数据写入文件系统(HDFS)、数据库(HBase)、仪表盘(live dashboards)中。
使用SparkStreaming 需要引用 Streaming 组件的依赖。
Maven配置如下:
<dependency>
<groupId>org.apache.spark</groupId>
<!-- 2.11 是指Scala大版本,项目各组件依赖版本需要统一,否则,呵呵 -->
<artifactId>spark-streaming_2.11</artifactId>
<!-- Spark 版本 -->
<version>2.3.0</version>
</dependency>
SBT配置如下:
libraryDependencies += "org.apache.spark" % "spark-streaming_2.11" % "2.3.0"
原理
SparkStreaming 在收到实时数据流后,将数据划分成批次,然后传给Spark Engine处理,按批次生成最后的结果流。即将流式计算分解成一系列短小的批处理作业。
学习准备
安装netcat
netcat命令
# 创建一个连接(server),ip 127.0.0.1 port 9999
nc -l 9999
# 创建客户端,连接到指定连接 ip 127.0.0.1 port 9999
nc 127.0.0.1 9999
Streaming 的重要抽象
StreamingContext
StreamingContext 是 Streaming 程序所有功能的重要入口,下面创建一个StreamingContext对象。
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
// 第二个参数是设置批次间隔,比如下面的每一秒生成一个 RDD
val ssc = new StreamingContext(conf, Seconds(1))
DStream
DStream(Discretized Stream, 离散流) 是 Streaming 程序中的重要编程模型,可以将它看做一个 RDDs 的序列。同 RDD 一样提供了很多高层次的函数式编程API,例如map、reduce、groupBy等等。
DStream将计算分割为一系列较小时间间隔、状态无关、确定批次的任务,每个批次的接收到的数据被可靠的存储在集群中,作为一个输入数据集。当规定的时间间隔完成,将间隔内生成的数据集并行的进行运算,并将产生的中间数据或者新的数据存储在RDD中。
InputDStream
InputDStream 是 DStream 的一个子类,是所有输入流的抽象基类。
定义了接收和停止接收数据的方法(start和stop),InputDStream 的直接实现者不需要定义专门的 Receiver,它在Driver上即可完成生成RDD的任务。
ReceiverInputDStream
ReceiverInputDStream 是 InputDStream 的一个抽象子类。每个 ReceiverInputDStream 都会对应一个单一的接收器对象,接收器对象从数据源接收数据并且存到Spark内存中处理。在Streaming程序中可以创建多个 ReceiverInputDStream 并行接收多个数据流。
每个接收器是一个长期运行在Worker或者Executor上的Task,因此每个接收器会占用分配给Streaming程序的一个核(core)。为了保证一个或者多个接收器能够正常运行需要确保给 Streaming 程序足够的核心。要点如下:
- 当分配给 Streaming 程序的核数小于或者等于 ReceiverInputDStream 的数量时,系统可以接收数据,但是没有能力处理全部的数据。
- 当在local模式运行时,如果只有一个核运行任务,对于程序来说是不够的。就算只有一个ReceiverInputDStream,那么它的接收器将会独占这一个核,程序就没有多余的核对数据进行其他的变换操作了。
输入源
SparkStreaming中有两种类型的流式输入数据源:
- 基本输入源:能够直接应用于StreamingContext API的输入源。例如,文件系统、套接字连接、AKKA Actor。
- 高级输入源:需要额外导入一些jar包,应用于特定工具类的输入源。例如,Kafka、Flume、Kinesis、Twitter等。
基本输入源
文件流
文件流用于兼容从HDFS中读取的文件数据,示例如下:
val fileInputDStream: FileInputDStream = streamingContext.fileStream[KeyClass, ValueClass, InputFormatClass]("hdfs:///dataDirectory")
Streaming 程序将监控dataDirectory目录,并处理在该目录中创建的任何文件(嵌套目录中的文件不行)。该目录中的文件有如下特点:
- 具有相同的数据格式
- 是通过院子移动或者重命名文件的方式在dataDirectory文件夹中创建的
- 一旦移动这些文件,将不能再修改(即便在文件中追加内容,追加的内容也不会被读取)
对于简单的文本文件,还有一个更简单的方法可以使用:streamingContext.textFileStream(dataDirectory)
FileInputDStream 是 InputDStream 的直接子类,没有接收器,因此不需要分配额外的内核给它。
套接字流
套接字流通过监听Socket端接口来接收数据,示例如下:
// host:port
val lines: SocketInputDStream = streamingContext.socketTextStream("localhost", 9999)
SocketInputDStream 是 ReceiverInputDStream 的子类,因此有接收器。
RDD 队列流
基于RDD队列的 DStream 用于调试 Streaming 程序,示例如下:
// 创建一个被 QueueInputDStream 监听的RDDs 队列
// Scala SynchronizedQueue 被弃用了,考虑用 java.util.concurrent.ConcurrentLinkedQueue 替代
val rddQueue = new SynchronizedQueue[RDD[Int]]()
// 创建 QueueInputDStream
val queueInputDStream = streamingContext.queueStream(rddQueue)
// 随便做些处理
queueInputDStream.map(x => (x % 10, 1)).reduceByKey(_ + _).print()
// 启动 streamingContext
streamingContext.start()
// push 一些 RDDs
for (i <- 1 to 30) {
rddQueue += streamingContext.sparkContext.makeRDD(1 to 1000,10)
Thread.sleep(1000)
}
// 停止 streamingContext
streamingContext.stop()
自定义数据源
可以通过继承InputStream/ReceiverInputStream来创建自定义的数据源。
高级输入源
高级输入源依赖于Spark之外的库,如Kafka、Flume等。这是为了避免Spark和Kafka所依赖的jar包冲突问题,故Spark将这些输入源的创建方法实现在独立的库中。因此需要引入额外的依赖
Maven 配置如下:
<dependency>
<groupId>org.apache.spark</groupId>
<!-- 0-10 指 Kafka 版本 0.10.x 或更高 -->
<!-- -->
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.3.0</version>
</dependency>
SBT 配置如下:
libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka-0-10" % "2.3.0"
注意:kafka 0.8.x 版本已经被 Spark2.3.0 弃用了。
在 kafka 版本选择上可以参考对应Spark版本的官方文档 0.8 版本和 0.10 版本的对比说明 Spark Streaming + Kafka Integration Guide
| spark-streaming-kafka-0-8 | spark-streaming-kafka-0-10 | |
|---|---|---|
| Broker Version | 0.8.2.1 or higher | 0.10.0 or higher |
| Api Stability | Stable | Experimental |
| Language Support | Scala, Java, Python | Scala, Java |
| Receiver DStream | Yes | No |
| Direct DStream | Yes | Yes |
| SSL / TLS Support | No | Yes |
| Offset Commit Api | No | Yes |
| Dynamic Topic Subscription | No | Yes |
DirectDStream 和 ReceiverDStream
Kafka 提供两种 InputDStream:
- DirectDStream: 不需要接收器
- ReceiverDStream: 需要接收器,kafka 0.8.x 版本才有,0.10.x 版本没有
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "localhost:9092,anotherhost:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("topicA", "topicB")
val kafkaDirectDStream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
kafkaDirectDStream.map(record => (record.key, record.value)).print()
streamingContext.start()
streamingContext.awaitTermination()
DStream 状态操作
状态操作是数据的多批次操作之一(作用于多个批次),包括基于Window的操作和update-StateByKey操作。
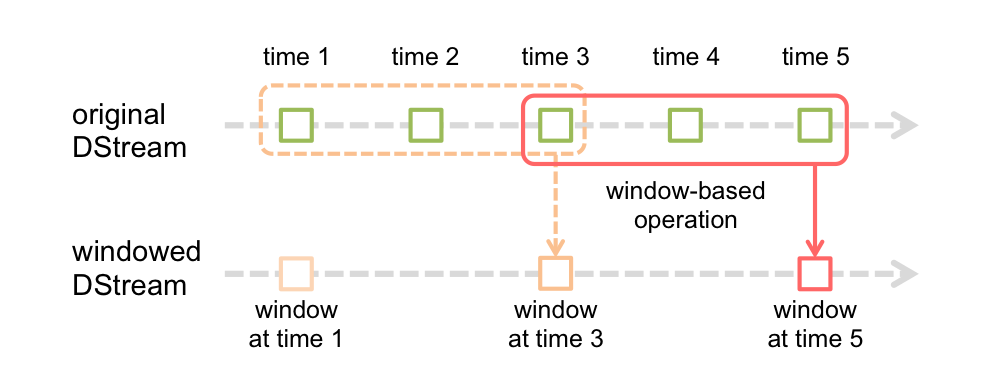
window 计算
Streaming程序提供了基于window的计算,允许通过滑动窗口对数据进行转换。任何窗口操作都需要指定两个重要参数:
- 窗口长度(window length),窗口的持续时间
- 滑动窗口时间间隔(slide interval),多长时间滑动一次窗口
可以简单理解为每隔30s(滑动窗口时间间隔)统计一下最近60秒(窗口大小)的数据
这两个参数都必须是DStream批处理间隔的倍数
举个例子,DStream的批处理间隔是1小时,如果想每隔2个小时就统计网站最近3个小时的PV量,可以设置窗口长度为3小时,窗口间隔时间为2小时。注意,攒满一个窗口的大小,才开始计算滑动间隔时间。第一个窗口在第3小时填满,第一次计算窗口中的数据,等到了第5小时,窗口进行第一次滑动,落在第3小时和第5小时的区间,开始计算第二个窗口中的数据。图示如下: